导图社区 第4章血液循环-心脏功能
第4章血液循环-心脏功能
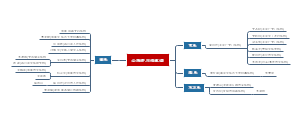
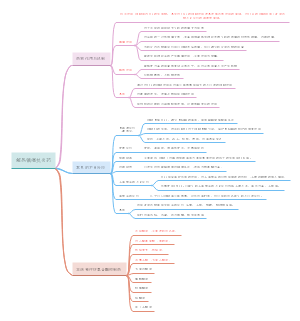
这是一篇关于第4章 血液循环 心脏功能的思维导图,心脏是一个由心肌组织构成并具有瓣膜结构的空腔器官,是血液循环的动力装置。它通过不断作收缩和舒张交替的活动,为血液流动提供能量。主要内容包括:心肌的生理特性,心脏的电生理,心脏的泵血功能。
编辑于2024-08-08 15:16:04- 第十章神经系统的功能
这是一篇关于第十章 神经系统的功能的思维导图,主要内容包括:自主神经系统,神经系统对内脏,本能行为和情绪的调节,神经系统对躯体运动的调控,神经的感觉分析功能,基本原理。
- 第三章血液
这是一篇关于第三章 血液的思维导图,血液是由血浆和血细胞组成的流体组织,具有运输物质、缓冲、维持体温恒定以及防御和保护等功能。主要内容包括:血型和输血原则,生理性止血,血细胞生理,概述。
- 第4章血液循环-心脏功能
这是一篇关于第4章 血液循环 心脏功能的思维导图,心脏是一个由心肌组织构成并具有瓣膜结构的空腔器官,是血液循环的动力装置。它通过不断作收缩和舒张交替的活动,为血液流动提供能量。主要内容包括:心肌的生理特性,心脏的电生理,心脏的泵血功能。
第4章血液循环-心脏功能
社区模板帮助中心,点此进入>>
- 第十章神经系统的功能
这是一篇关于第十章 神经系统的功能的思维导图,主要内容包括:自主神经系统,神经系统对内脏,本能行为和情绪的调节,神经系统对躯体运动的调控,神经的感觉分析功能,基本原理。
- 第三章血液
这是一篇关于第三章 血液的思维导图,血液是由血浆和血细胞组成的流体组织,具有运输物质、缓冲、维持体温恒定以及防御和保护等功能。主要内容包括:血型和输血原则,生理性止血,血细胞生理,概述。
- 第4章血液循环-心脏功能
这是一篇关于第4章 血液循环 心脏功能的思维导图,心脏是一个由心肌组织构成并具有瓣膜结构的空腔器官,是血液循环的动力装置。它通过不断作收缩和舒张交替的活动,为血液流动提供能量。主要内容包括:心肌的生理特性,心脏的电生理,心脏的泵血功能。
- 相似推荐
- 大纲