导图社区 高中政治必修一第一课
高中政治必修一第一课
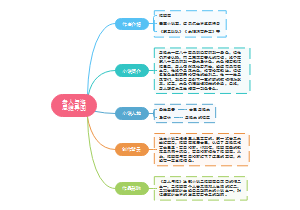
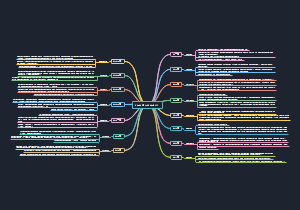
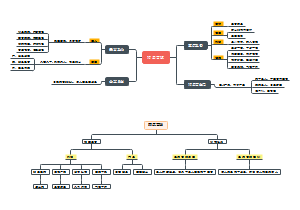
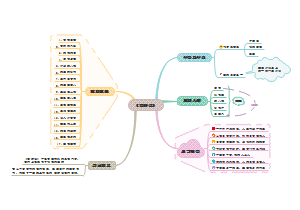
这是一个关于高中政治必修一第一课的思维导图,将知识点进行了归纳整理,涵盖所有核心内容,非常方便大家学习。适用于考试复习、预习,提高学习效率。赶紧收藏一起学习吧!
编辑于2025-06-04 23:08:21- 知识汇总
- 相似推荐
- 大纲
导图社区 高中政治必修一第一课
这是一个关于高中政治必修一第一课的思维导图,将知识点进行了归纳整理,涵盖所有核心内容,非常方便大家学习。适用于考试复习、预习,提高学习效率。赶紧收藏一起学习吧!
编辑于2025-06-04 23:08:21