导图社区 考研病理 生殖
这是一篇关于生殖的思维导图,主要内容包括:前列腺,乳腺癌(女性最常见恶性肿瘤),卵巢肿瘤,滋养层细胞,子宫体,子宫颈。
临床医学考研学姐呕心沥血整理,包含续期老师的临床思维部分以及天天师兄的笔记,医学考研没那么难!
考研学姐呕心沥血整理,包含刘忠保老师的绝妙思路以及天天师兄笔记!医学考研没那么难!
准备考试的一位医学生呕心沥血整理的心电图速成宝典!系统地梳理了心电图的基础知识和读图要点,适合用于学习和复习心电图相关知识。
这是一篇关于内分泌系统的思维导图,主要内容包括:胰岛细胞瘤(属于AUPD),糖尿病(可有玻璃样变性),甲状腺疾病,甲状腺癌。
社区模板帮助中心,点此进入>>
小儿常见病的辩证与护理
蛋白质
均衡饮食一周计划
消化系统常见病
耳鼻喉解剖与生理
糖尿病知识总结
细胞的基本功能
体格检查:一般检查
心裕济川传承谱
解热镇痛抗炎药
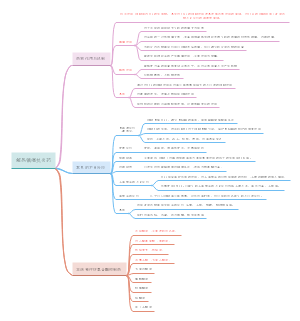
生殖
子宫颈
宫颈炎
纳博特囊肿:增生的鳞状上皮覆盖子宫颈管腺体的开口→液体潴留、腺体扩大
宫颈糜烂
假性糜烂(多见)
子宫颈损伤的鳞状上皮被子宫颈管的柱状上皮增生下移取代(相当于化生)
柱状上皮薄,上皮下血管易显露—红色;柱状上皮呈乳头状—像糜烂
真性糜烂
子宫颈阴道部的鳞状上皮坏死、脱落,形成浅表缺损
宫颈癌
宫颈上皮内瘤变(CIN)
分级
*“原位癌累及腺体”:未突破基底膜,仍属于原位癌
病因
性生活过早 & 紊乱、HPV(尤其是16、18型)
E6蛋白破坏p53;E7蛋白破坏RB
好发
鳞-柱状上皮交界处(移行带);鳞癌多见
最早 & 最常见扩散
淋巴转移(最早至子宫旁淋巴结) & 直接蔓延
分期
0 :原位癌
I:局限于子宫颈内
早期(微小)浸润癌:深度≤基底膜下5mm & 宽度≤7mm
浸润癌:深度>基底膜下5mm / 宽度>7mm
II:侵及阴道但未累及阴道下1/3
III:侵及阴道下1/3或累及盆腔壁
IV:超越骨盆或侵犯膀胱 / 直肠
子宫体
子宫内膜异位症:子宫内膜腺体 & 间质出现在子宫内膜以外的部位
*子宫腺肌病:异位于子宫肌层 & 距离内膜基底层2mm以上
卵巢(—巧克力囊肿)、子宫阔韧带最常见
子宫内膜增生症:雌激素↑ →子宫内膜腺体 / 间质增生
病理
单纯性增生
发展为子宫内膜癌几率:1%
腺体增多:无背靠背
复杂性增生
发展为子宫内膜癌几率:3%
腺体增多:可背靠背
异型(不典型)增生
发展为子宫内膜癌几率:1/3
腺体增多:明显背靠背
无子宫内膜间质浸润—可区别于癌
子宫平滑肌瘤
肌瘤变性
玻璃样变性(最常见):漩涡状结构由透明样物质取代
红色样变(妊娠期多见):肌瘤间质血管血栓形成→局部坏死、出血
子宫平滑肌肉瘤
肿瘤细胞凝固性坏死、核分裂象增多
滋养层细胞
葡萄胎:绒毛呈葡萄状、绒毛间质水肿、黏液样变性、间质内血管减少
*黏液样变性:甲减、风湿病(变质渗出期)、葡萄胎
绒毛膜癌:无绒毛、无肿瘤间质、无血管
转移(血道)
肺(最易):咯血
阴道:蓝紫色结节
*对比侵蚀性葡萄胎—绒毛栓塞→蓝紫色结节
大脑:头痛、呕吐
*共同特征:滋养层细胞异常增生,患者hCG显著高于正常妊娠
卵巢肿瘤
上皮性肿瘤
性索-间质肿瘤
生殖细胞肿瘤
*葡形团:还可见于小细胞肺癌
*对比前列腺癌—酸性磷酸酶
乳腺癌(女性最常见恶性肿瘤)
危险因素
>40岁、遗传(BRCA-1缺陷)、放射线
雌激素暴露时间延长:月经来潮早、绝经晚、晚育不育、肥胖(芳香化酶多—促雄h → 雌h)
好发部位:乳腺外上象限
乳腺导管上皮、腺泡上皮增生
普通型:流水样分布
非典型(癌前病变):分布均匀、单一形态
分类
非浸润(原位)癌
导管原位(导管内)癌
高级别—核分裂象常见、粉刺样坏死
粉刺癌
非粉刺型癌
乳头湿疹样乳腺癌(Paget病)
小叶原位癌
核分裂象罕见、癌变间期长、多累及双侧乳房多个象限
浸润癌
浸润性非特殊癌(预后差)
导管癌(最常见):巢状结构、边界不清、间质(纤维组织)多
小叶癌(最易转移):单行串珠状(列兵样)分布、环形排列在导管周围(牛眼样 / 靶环)
髓样癌(无大量淋巴细胞浸润)(实质>间质)
单纯癌(实质=间质)
硬癌(实质<间质)
腺癌
浸润性特殊癌
预后好(比浸润性非特殊癌好)(记忆:软软的(髓样癌)小乳头分泌粘液)
髓样癌
巢状结构、边界清楚、癌细胞大、间质少、大量淋巴细胞浸润
小管癌(高分化腺癌)
大量腺体形成
恶性度最低—预后最好
实性乳头状瘤
分泌性癌
粘液癌
预后差
炎性乳癌
预后最差
化生性癌
富于脂质性癌
浸润性微乳头状癌
表现
橘皮样变(皮肤水肿)—阻塞淋巴管
酒窝征(皮肤凹陷)—侵犯Cooper韧带
转移
淋巴结
最早最常见
首先至同侧腋窝淋巴结
易经椎旁静脉系统→脊椎
鉴别
乳腺硬化性腺病
乳腺癌—缺失肌上皮细胞
对比:前列腺癌—缺失基底细胞
治疗
ER、PR(+);Her-2(-):预后好—内分泌治疗
ER、PR(+);Her-2(+):预后差—靶向治疗
前列腺
前列腺增生
发病因素:老龄 + 有功能的睾丸
好发部位:移行带
病理:淀粉样小体
尿频(最早)、进行性排尿困难(最典型)、劳累 / 饮酒加重(前列腺突然充血)
检查
直肠指检:中间沟变浅 / 消失(首选)
影像学首选B超
并发症
尿潴留、急迫性 / 充盈性尿失禁、膀胱结石、肾功能不全、无痛性血尿、腹外疝、痔疮
并发急性尿潴留
导尿
急性尿潴留病史 / 尿流率 <10
经尿道前列腺切除术(TURP)
药物治疗
观察随访
5α还原酶抑制剂:非那雄胺
α1-R(尿道括约肌)阻滞剂:哌/特拉唑嗪
*禁用M-R(逼尿肌)阻滞剂:阿托品
前列腺癌
好发于外周带
基底细胞缺失
血道转移:脊椎骨(最常见)、股骨近端、盆骨、肋骨
*男性肿瘤骨转移:首先怀疑前列腺癌
怀疑骨转移:首选ECT
诊断
PSA、酸性磷酸酶↑,直肠指检(首选)—触及硬结,经直肠超声(早期无异常)
穿刺活检--最可靠
局限在前列腺
根治性前列腺切除
突破前列腺
抗雄激素药 + 去势治疗(切双侧睾丸 / 药物抑制睾酮)