导图社区 脓毒症相关急性肾损伤危重症患者预后模型的构建与验证:可解释的
脓毒症相关急性肾损伤危重症患者预后模型的构建与验证:可解释的
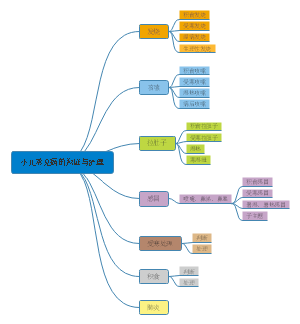
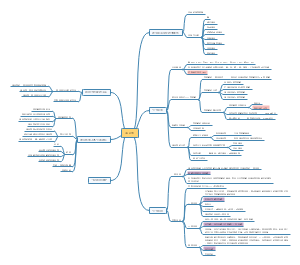
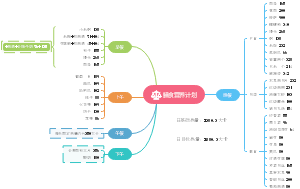
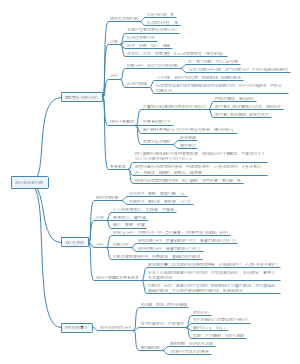
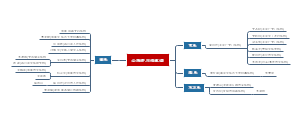
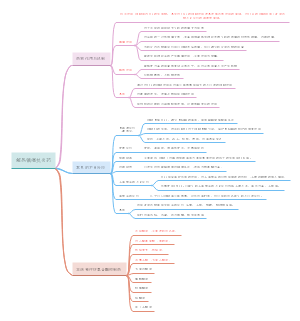
这是一篇关于脓毒症相关急性肾损伤危重症患者预后模型的构建与验证:可解释的的思维导图,主要内容包括:补充材料,表不如图,字不如表,摘要,题目。
提示: 本内容由社区用户上传并分享。平台不对内容的真实性、合法性、知识产权归属及是否侵害第三方权利进行事前审核或保证。本内容可能包含受版权保护的图片、字体或其他第三方素材,使用前请自行确认授权范围。
- 预测模型范文
- 相似推荐
- 大纲