导图社区 初中物理电学
这是一个关于初中电学的思维导图,包含电流、 电压、 电阻、 电功率、 电能、 电磁感应等。
社区模板帮助中心,点此进入>>
《老人与海》思维导图
《钢铁是怎样炼成的》章节概要图
《傅雷家书》思维导图
《西游记》思维导图
《水浒传》思维导图
《茶馆》思维导图
《朝花夕拾》篇目思维导图
《红星照耀中国》书籍介绍思维导图
初中物理质量与密度课程导图
桃花源记思维导图
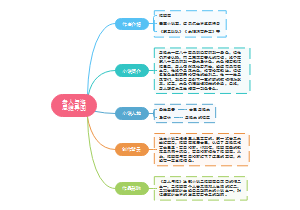
初中电学。
电流
电流的定义
电流是电荷的定向移动
电流的方向
正电荷的移动方向为电流方向
负电荷的移动方向与电流方向相反
电流的测量
电流表的使用
电流表的结构
电流表的结构包括量程、指针、刻度盘等
电流表的结构还包括两个接线柱,一个接线柱接正极,另一个接线柱接负极
电流表的读数
电流表的读数需要根据指针的位置和刻度盘上的刻度来确定
电流表的读数还需要注意电流表的量程,不能超过量程
电压
电压的定义
电压是电场中两点之间的电势差
电压的方向
电压的方向是从高电势到低电势
电压的测量
电压表的使用
电压表的结构
电压表的结构包括量程、指针、刻度盘等
电压表的结构还包括两个接线柱,一个接线柱接正极,另一个接线柱接负极
电压表的读数
电压表的读数需要根据指针的位置和刻度盘上的刻度来确定
电压表的读数还需要注意电压表的量程,不能超过量程
电阻
电阻的定义
电阻是导体对电流的阻碍作用
电阻的大小与导体的材料、长度、横截面积和温度有关
电阻的测量
电阻表的使用
电阻表的结构
电阻表的结构包括量程、指针、刻度盘等;
电阻表的结构还包括两个接线柱,一个接线柱接正极,另一个接线柱接负极
电阻表的读数
电阻表的读数需要根据指针的位置和刻度盘上的刻度来确定;
电阻表的读数还需要注意电阻表的量程,不能超过量程
电功率
电功率的定义
电功率是电流在单位时间内做的功
电功率的大小与电流、电压和电阻有关
电功率的测量
电功率表的使用
电功率表的结构
电功率表的结构包括量程、指针、刻度盘等
电功率表的结构还包括两个接线柱,一个接线柱接正极,另一个接线柱接负极
电功率表的读数
电功率表的读数需要根据指针的位置和刻度盘上的刻度来确定
电功率表的读数还需要注意电功率表的量程,不能超过量程
电能
电能的定义;
电能是电场中电荷做功的能力
电能的大小与电流、电压和电阻有关
电能的测量
电能表的使用
电能表的结构
电能表的结构包括量程、指针、刻度盘等
电能表的结构还包括两个接线柱,一个接线柱接正极,另一个接线柱接负极
电能表的读数
电能表的读数需要根据指针的位置和刻度盘上的刻度来确定
电能表的读数还需要注意电能表的量程,不能超过量程
电磁感应
电磁感应的定义
电磁感应是电流在磁场中受到力的作用
电磁感应的大小与电流、磁场和电阻有关
电磁感应的测量
电磁感应表的使用
电磁感应表的结构
电磁感应表的结构包括量程、指针、刻度盘等
电磁感应表的结构还包括两个接线柱,一个接线柱接正极,另一个接线柱接负极
电磁感应表的读数
电磁感应表的读数需要根据指针的位置和刻度盘上的刻度来确定
电磁感应表的读数还需要注意电磁感应表的量程,不能超过量程
电学实验;
电学实验的目的
电学实验的目的是验证电学理论,提高实验技能
电学实验的步骤
电学实验的步骤包括实验准备、实验操作、实验记录和实验分析
电学实验的注意事项
电学实验的注意事项包括安全操作、正确使用仪器和遵守实验规则;]