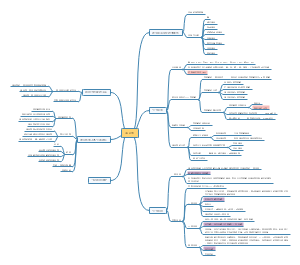
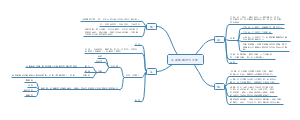
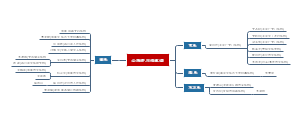
1、根据第四章均数加法法则:如果X 和Y是两个随机变量,则,可知样本均数的均数为:

即样本均数这个随机变量的均数等于总体均数μ
2、当总体中的个体数远远大于样本量时,认为样本之间时互相独立的,根据第四章只是,如果X和Y时相互独立的两个随机变量,则,所以可加性同样适用于方差,并且根据方差的揭发法则:如果X是一个随机变量并且a和b是常数,则,可以计算样本均数的方差为:

3、结论:
从一个均数等于μ,标准差等于σ的总体中抽取样本量为n的简单随机样本,其样本均数服从均数为,标准差为的抽样分布:

4、增大样本量可以减少样本均数的标准差,从而减少抽样误差
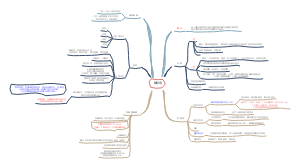
1、根据第四章均数加法法则:如果X 和Y是两个随机变量,则μ(X+Y)=μX+μY,可知样本均数的均数为:(如右图),即样本均数这个随机变量的均数等于总体均数μ
2、当总体中的个体数远远大于样本量时,认为样本之间时互相独立的,根据第四章知识,如果X和Y时相互独立的两个随机变量,则σ^2(X+Y)=σ^(X)+σ^2(Y),所以可加性同样适用于方差,并且根据方差的加法法则:如果X是一个随机变量并且a和b是常数,则σ^2(a+bX)=b^2×σ^2(X),可以计算样本均数的方差为:
σ(X-)^2是样本的方差,它的值是总体方差σ^2/n,意味着通过抽样,方差减小了,相对于总体而言,这也是我们进行抽样分布的原因,为了获取更集中的数据,好进行统计推断
3、结论:从一个均数等于μ,标准差等于σ的总体中抽取样本量为n的简单随机样本,其样本均数服从均数为μX,标准差为σX的抽样分布:
获得的抽样的样本的数据没有改变总体均数与样本的统计量样本均数的位置,而缩小了它的方差,说明数据他更集中了
原始的数据比较分散,我们通过抽样可以使数据更集中,而且不改变它的集中位置
4、增大样本量可以减少样本均数的标准差,从而减少抽样误差