导图社区 CFA数量分析(1)
- 528
- 67
- 9
- 举报
CFA数量分析(1)
数量分析(1)的内容,包括线性回归、多元线性回归、时间序列。 后续待更新
编辑于2019-12-30 14:46:25- CFA
- 相似推荐
- 大纲

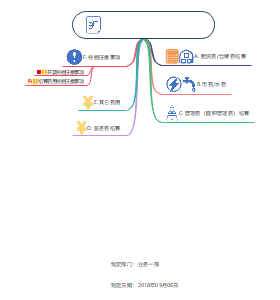




Quantative Mthods(数量分析)
传统(study session 2)
Regression
Linear regression
Model
模型构成要素
varibles(变量)
corss-sectional data
time-series data
regression coefficients(回归系数)
求解b1后,用均值(X,Y)求解b0
估计回归系数
linear least squares(最小二乘法)
最小值:
(dependent variable – predictedvalue of dependent variable)2
estimated parameters or fitted parameters:
Note that we never observe the population parameter values b0 and b1 in a regression model.
error term(残差)
excel模型
Assumptions(6条)
1.Y,X 是以b0,b1为参数的直线(X is linear in the parameters b0 and b1),不排除X多次幂
不可采用线性回归
可以采用线性回归分析
2.X, is not random
3.
误差项ε是一个期望值为零的随机变量
保证计算出正确的b0,b1
4.
同方差假设(homoskedasticity assumption)
5.
误差项ε相互独立
6. ε, 呈正态分布( normally distributed)
检测是否有特定的估计参数
SEE(Sdandard Error of Estimate)
衡量回归模型对变量关系描述的准确程度
The coefficient of determination(决定系数)
单变量
相关系数的平方,r^2
多变量
决定系数的逻辑
total variation=
RSS(SSr):sum of squares of regression
unexplained variation=
SSe:sum of squares of error
Total variation = Unexplained variation + Explained variation
决定系数越大,拟合效果越好
Hypoththesis testing
H0:ρ=0,H1:ρ≠0.H0:null hypothesis,H1:alternative hypothesis
confidence interval
置信区间外,拒绝H0。
t-test
reject H0
t-value 越大越好
we can reject the hypothesis that the true parameter is equal to 0 at the 0.5 percent significance level (99.5 percent confidence).
p-value
The p-value is the smallest level of significance at which the null hypothesis can be rejected.拒绝H0的最小值。
p-value 越小越好。通常的参考值是0.05
显著性水平(significance level )是估计总体参数落在某一区间内,可能犯错误的概率,用α表示。——百度百科
error type
Analysts often choose the 0.05 level of significance, which indicates a 5 percent chance of rejecting the null hypothesis when, in fact, it is true (a Type I error)
Analysis of variance(ANOVA)
Analysis of variance (ANOVA) is a statistical procedure for dividing the total variability of a variable into components that can be attributed to different sources.
F-test
The F-statistic tests whether all the slope coefficients in a linear regression are equal to 0.
H0: b1 = 0 , Ha: b1 ≠ 0
F越大越好
子主题
Prediction Intervals
two sources of uncertainty
the error term itself contains uncertainty.
estimated parameters
limitations
parameter instability
regression relations can change over time, just as correlations can.
public knowledge
public knowledge of regression relationships may negate their future usefulness.
assumptions are violated
hypothesis tests and predictions based on linear regression will not be valid
Multiple Linear Regression
Introduction
t-test
ANOVA
two types of uncertainty:
SEE(standard error of estimate):uncertainty in the regression model itself
b0,b1: uncertainty about the esti mates of the regression coefcients.
随着自变量Xi的数量的增加,R^2会增加,R^2的可靠性降低,此时要对照adjusted R^2来看
Dummy Variables
Dummy variables in a regression model can help analysts determine whether a particular qualitative independent variable explains the model’s dependentvariable.一个定性的自变量能否解释因变量
值(0,1)
要在n个分类中确认,需要有n-1个虚拟变量
截距表示被省略的分类X对应的Y平均值,斜率表示每个分类对Y的的增量效果(incremental effect )
与一个变量的线性回归类似
Asumptions and Violations
Asumtions
A linear relation exists between the Xj and Y.
Xj are not random;no exact linear relation exists between Xj,Xk
同方差性
ε is uncorrelated across observations.
ε is normally distributed
Violations
heteroskedasticity
误差项方差与观测值方差不同
the variance of the errors differs across observations
no conditional heteroskedasticity
conditional heteroskedasticity
Breusch–Pagan test
serial correlation(autocorrelated)
误差项与观测值相关
regression errors are correlated across observations
前一期间的因变量当下一期间的自变量 lag value
Positive serial correlation
方差会减小
t-statistics:inflates
F-statistic:inflates
Durbin–Watson statistic (DW)
DW=2*(1-r)
DW的值介于0-4
参考值:DW=2,
DW偏离DW=2太远,表明有序列相关问题
multicollinearity
两个自变量之间存在线性关系
1个或多个自变量X存在高度相关性
不是完美相关(not perfectly)
t-statistics:不显著 t值小
F-statistic:显著,F值大
F检验与t检验宝墩,F大t小
决定系数R^2会增大
单个斜率系数的方差会增加,总体方差减小
Model Specification misSpecification
Model Specification
cogent economic reasoning
The model should be grounded in cogent economic reasoning
functional form .(LN,对数化)
The functional form chosen for the variables in the regression should beappropriate given the nature of the variables.(LN,对数化)
parsimonious(简约)
The model should be parsimonious(简约).
小X,大Y,见微知著。
assumptions violations
be examined for violations of regression assumptions before being accepted.
useful out of sample
The model should be tested and be found useful out of sample before being accepted.
misSpecification
functional form
variables could be omitted
variables may need to be transformed
pools data from different samples
X correlated with the error term
estimated regression coefcientsto be biased and inconsistent
time-series misspecifcation
lagged dependent variables as independent
including a function of dependent variable as an independent variable
independent variables that are measured with error
qualitative dependent variable
Probit models
based on the normal distribution
logit models
based on the logistic distribution
discriminant analysis
Time Series
Trend Models
linear trend
随时间增长固定的金额
log-linear trend
have exponential growth(指数式增长)
以固定增长率稳定增长
随时间增长固定的比率
In contrast, the linear trend model (Equation 1) predicts that ytgrows by a constant amount from one period to the next.
predicted trend value of yt
增长率
continuous compounding连续复利
线性趋势回归会有回归误差与观测值相关的问题,log会修正一些,但并没有解决。
Testing for Correlated Errors
DW-test
H0:没有序列相关问题,
使用趋势模型的前提是协方差平稳,协方差不平稳,则模型是无效的。
Autoregressive (AR) Time-Series Models
0<b1<1的时候,X的均值趋向于常数,误差项满足相关条件的时候属于协方差稳定序列b1=1的时候,X属于随机游走序列 b1=0的时候,相当于对随机游走序列进行一阶差分后的协方差稳定序列b1>1的时候,属于协方差不稳定序列,稳定增长的销售业绩属于此类序列
We must assume that the time series we are modeling is covariance stationary
以前看过一个介绍时间序列平稳性的帖子(跟楼主的问题不符),回忆如下:假设你看到两个酒鬼(即两个随机游走序列)四处流浪,醉鬼相互不认识(即他们是独立的),所以他们的路径之间没有任何有意义的关系。但假设这两个随机游走序列是醉鬼与他的狗,这时尽管每个单独的路径仍然是一个不可预知的随机游走过程,然而醉酒和狗两者之间的距离是可预见性。例如,如果狗远离于他的主人,狗会倾向于朝他的方向移动,所以这两个随机游走序列有接近的趋势)。醉鬼和他的狗组成了一对协整序列。如果两个非平稳的时间序列某些线性组合是平稳的,则可以说这两个序列具有协整关系。然后,我们就可以探索序列之间的长期均衡关系了。 作者:史晓斌链接:https://www.zhihu.com/question/21982358/answer/21491673来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 人大多时候心情舒畅,平静,与人合平共处,此时这个人的状态就像经济学中的均衡,时间序列的平稳性,这表现在股票价格上就是股票处于盘整状态。人有时会失去理智,情绪失控,其行为就是异常行为,此种状态下的人就是经济学中的不均衡,时间序列的非平稳性,这表现在股票价格上就是股票处于疯狂上涨与下跌中。如果情绪极度失控,价格时间序列就会呈现,高波动性与脱离时间序列平衡性的现象。 作者:黄勇链接:https://www.zhihu.com/question/21982358/answer/36915898来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Covariance-Stationary Series
the expected value of the time series must be constant and finite in all periods
t = 1, 2, …, T; s = 0, ±1, ±2, …, ±Twhere λ signifies a constant
the covariance of the time series with itself for a fixed number of periods in the past or future must be constant and finite in all periods
the variance of the time series must be constant and finite in all periods
怎么看是不是协方差平稳?直接看图,如果图显示出相同的均值和方差
所有滞后值的自相关系数=0
For a specific autoregressive model to be a good fit to the data, the autocorrelations of the error term should be 0 at all lags.
A random walk
前值+不可预测的随机项
revious period plus an unpredictable random error
不协方差平稳
If the time series is a random walk, it is not covariance stationary
带漂移的随机游走
A random walk with drift is a random walk with a nonzero intercept term.
有单位根
All random walks have unit roots.
如果一个时间序列有单位根,则不可能协方差平稳
单位根的处理
first-differencing the time series;(一阶拆分),对一阶拆分后的序列做自回归估计。
Moving-Average Time-Series Models
移动平均
滞后于实际,起到平滑数据的作用(如平滑季节性波动)
因为滞后的原因,不能起到预测的效果
MA(1) model
MA(q):A qth order moving-average model
ts first q autocorrelations are nonzero while autocorrelations beyond the first q are zero.
ARMA models
autoregressive moving average models
the parameters in ARMA models can be very unstable;
determining the AR and MA order of the model can be difficult;
ARMA models may not forecast well
ARCH
Autoregressive conditional heteroskedasticity model自回归条件异方差模型
If the coefficient on the squared residual is statistically significant, the time-series model has ARCH(1) errors
if a time-series model has ARCH(1) errors
多元时间序列问题
所有时间线都没有单元根,回归可用
If neither of the time series has a unit root, then we can safely use linear regression.
仅有其中一个时间序列有单元根,回归可不可用
If one of the two time series has a unit root, then we should not use linear regression
所有序列都有单元根,且时间序列协整,回归可用
If both time series have a unit root and the time series are cointegrated, we may safely use linear regression
所有序列都有单元根,且时间序列不协整,回归不可用
however, if they are not cointegrated, we should not use linear regression
(Engle–Granger) Dickey–Fuller test协整检验
The (Engle–Granger) Dickey–Fuller test can be used to determine if time series are cointegrated
时间序列的一些问题
协方差平稳会形成均值回归mean reverting
比较不同回归模型的准确性
The root mean squared error (RMSE)均方根误差:误差平方并均值的平方根
越小越好
时间序列模型的参数会不稳定,在使用时间序列模型用于估计时,要检测时间序列是否稳定。
时间序列预测的步骤
理解你遇到的投资问题,选择一个初始的时间序列模型
regression model
用一个变量预测另一个变量
time-series model
用同一个变量的前期数据预测该变量
如果使用时间序列模型,先画图看看是否是协方差平稳
不含
线性趋势a linear trend
指数趋势an exponential trend
季节性seasonality
样本区间内数据出现闲置的偏离,均值或者协方差的的变化a significant shift
步骤
画图检查线性趋势或指数趋势是否最合理的
估计趋势参数
计算剩余residuals
Durbin–Watson statistic检测序列相关问题
若不存在
模型可用
若存在
使用自回归模型autoregressive model
autoregressive model
协方差平稳的处理violations of stationarity
a linear trend,
first-difference the time series(一阶差分).
exponential trend
take the natural log of the time series and then first-difference it 对数化时间序列,然后一阶拆分
shifts significantly during the sample period
estimate different time-series models before and after the shift
significant seasonality
include seasonal lags
自回归模型的构建
Estimate an AR(1) model
Test to see whether the residuals from this model have significant serial correlation。不存在序列相关问题,则AR(1)可用。
如果存在序列相关问题,使用AR(2)进行进一步估计,重复前述步骤。一直到不存在序列问题为止。
检查季节性问题
方法一:画图观察
方法二:Examine the data to see whether the seasonal autocorrelations of the residuals from an AR model are significant (for example, the fourth autocorrelation for quarterly data)
To correct for seasonality, add seasonal lags to your AR model. For example, if you are using quarterly data, you might add the fourth lag of a time series as an additional variable in an AR(1) or an AR(2) model.
检测异方差问题 conditional heteroskedasticity
ARCH(1)
Regress the squared residual from your time-series model on a lagged value of the squared residual.
Test whether the coefficient on the squared lagged residual differs significantly from 0
If the coefficient on the squared lagged residual does not differ significantly from 0, the residuals do not display ARCH and you can rely on the standard errors from your time-series estimates.
use generalized least squares or other methods to correct for ARCH
out-of-sample forecasting performance
子主题
FinTech(study session 3)
Machine Learing
Big Data Projects
Probabilistic Approaches
scenario Analysis
Decision Trees
Simulation
主题