导图社区 方剂学思维导图
- 591
- 103
- 19
- 举报
方剂学思维导图
关于考研方剂学方歌、功效、主治思维导图。
编辑于2020-10-16 18:00:02- 相似推荐
- 大纲





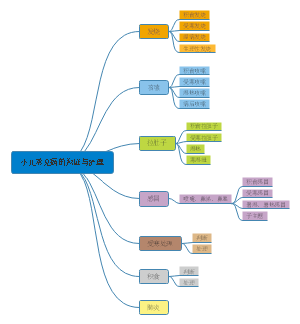


方剂学
解表剂
辛温解表
1.麻黄汤 (发汗解表,宣肺平喘)(外感风寒表实证)
麻黄汤中臣桂枝,杏仁甘草四般施, 发汗解表宣肺气,伤寒表实无汗宜。
2.桂枝汤 (解肌发表,调和营卫)(外感风寒表虚证)
桂枝芍药等量伍,姜枣甘草微火煮, 解肌发表调营卫,中风表虚自汗出。
3.小青龙汤(解表散寒,温肺化饮)(外寒内饮证)
解表蠲饮小青龙,麻桂姜辛夏草从, 芍药五味敛气阴,表寒内饮最有功。
4.九味羌活汤(发汗祛湿,兼清里热)(外感风寒湿邪,内有蕴热)
九味羌活防风苍,辛芷芎草芩地黄, 发汗祛湿兼清热,分经论治变通良。
5.正柴胡饮 (解表散寒)(外感风寒轻证)
正柴胡饮平散方,芍药防风陈草姜, 轻疏风邪解热通,表寒轻症服之康。
辛凉解表
1.银翘散(辛凉透表,清热解毒)(温病初起)
银翘散主上焦疴,竹叶荆蒡豉薄荷, 甘桔芦根凉解法,清疏风热煮无过。
2.桑菊饮(疏散风热,宣肺止咳)(风温初起,邪客肺络证)
桑菊饮中桔杏翘,芦根甘草薄荷饶, 清疏肺卫轻宣剂,风温咳嗽服之消。
3麻杏甘石汤(辛凉疏表,清肺平喘)(外感风邪,邪热壅肺证)
仲景麻杏甘石汤,辛凉宣肺清热良, 邪热雍肺咳喘急,有汗无汗均可尝。
4柴葛解肌汤(解肌清热)(外感风邪,郁而化热证)
陶氏柴葛解肌汤,邪在三阳热势张, 芩桔芍芷草枣姜,羌膏解表清热良。
5升麻葛根汤(解肌透疹)(麻疹初起)
阎氏升麻葛根汤 芍药甘草合成方, 麻疹初起出不透 解肌透疹此方良.
扶正解表
1.败毒散(散寒祛湿,益气解表)(气虚外感风寒湿证;外邪陷里之痢疾)
人参败毒草苓芎,羌独柴前枳桔共, 薄荷少许姜三片,气虚感寒有奇功。
2.参苏饮(益气解表,理气化痰)(气虚外感风寒,内有痰湿证)
参苏饮内用陈皮,枳壳前胡半夏齐, 干葛木香甘桔茯,气虚外感最相宜。
3.再造散(助阳益气,解表散寒)(阳气虚弱,外感风寒表证)
再造散用参芪甘,桂附羌防芎芍含, 细辛煨姜大枣入,阳虚无汗法当谙。
4.麻黄细辛附子汤(助阳解表)(素体阳虚,外感风寒表证;暴哑)
麻黄细辛附子汤,助阳解表代表方, 阳虚外感风寒证,寒重热轻脉沉良。
5.加减葳蕤汤(滋阴解表)(阴虚外感风寒证)
加减葳蕤用白薇,豆豉生葱桔梗随, 草枣薄荷八味共,滋阴发汗功可慰。
6.香苏散 (疏散风寒,理气和中)(外感风寒证)
香苏散内草陈皮,疏散风寒又理气, 外感风寒兼气滞,寒热无汗胸脘痞。
7.葱白七味饮 (养血解表)(血虚外感风寒证)
葱白七味外台方,新豉葛根与生姜, 麦冬生地千扬水,血虚外感最相当。
泻下剂
寒下
1大承气汤(峻下热结)(阳明腑实证;热结旁流证;里热实证之热厥痉病发狂)
大承气汤大黄硝,枳实厚朴先煮好,峻下热结急存阴,阳明腑实重证疗。 去硝名为小承气,轻下热结用之效, 调胃承气硝黄草,缓下热结此方饶。
2大陷胸汤(泻热逐水)(水热互结之结胸证)
子主题
大陷胸汤用硝黄,甘遂为末共成方, 专治水热结胸证,泻热逐水效非常。
3大黄牡丹汤(泻热破瘀,散结消肿)(肠痈初起,湿热瘀滞证)
子主题
金匮大黄牡丹汤,桃仁芒硝瓜子襄, 泻热破淤散结肿,肠痈初起腹痛康, 肠痈初起腹按痛,尚未成脓服之消。
温下
1温脾汤 (攻下冷积,温补脾阳)(阳虚寒积证)
温脾附子大黄硝,当归干姜人参草, 攻下寒积温脾阳,阳虚寒积腹痛疗。
2大黄附子汤 (温里散寒,通便止痛)(寒积里实证)
金匮大黄附子汤,细辛散寒止痛良, 温下治法代表方,寒积里实服之康。
润下
1麻子仁丸 (润肠泄热,行气通便)(胃肠燥热,脾约便秘)
麻子仁丸脾约治,杏芍大黄枳朴秘, 润肠泻热又行气,胃热肠燥便秘施。
2济川煎 (温肾益精,润肠通便)(肾阳虚弱,精津不足证(肾虚便秘))
济川苁蓉归牛膝,枳壳升麻泽泻使, 温肾益精润通便,肾虚精亏便秘宜。
逐水
1十枣汤 (攻逐水饮)(悬饮;水肿)
十枣非君非汤剂,芫花甘遂合大戟, 攻逐水饮力峻猛,悬饮水肿实证宜
2舟车丸 (行气逐水)(水热内壅,气机阻滞)
舟车牵牛及大黄,遂戟芫花槟木香, 青皮橘皮轻粉入,泻水消胀力量强。
攻补兼施
1黄龙汤 (攻下通便,补气养血)(阳明腑实,气血不足证)
黄龙汤中枳朴黄,参归甘梗枣硝姜, 攻下热结养气血,阳明腑实气血伤。
2新加黄龙汤 (滋阴益气,泄热通便)(热结里实,气阴不足证)
新加黄龙草硝黄,参归麦地玄海姜, 滋阴养液补气血,正虚便秘此方良。
3增液承气汤 (滋阴增液,泄热通便)(阳明温病,热结阴亏)
增液承气玄地冬,更加硝黄力量雄, 温病阴亏实热结,养阴泻热肠道通。
和解剂
和解少阳
1小柴胡汤(和解少阳)(伤寒少阳证;热入血室证;黄疸,疟疾以及内伤杂病见少阳证者)
小柴胡汤和解功,半夏人参甘草从, 更加黄芩生姜枣,少阳为病此方宗。
2蒿芩清胆汤(清胆利湿,和胃化痰)(少阳湿热痰浊证)
蒿芩清胆夏竹茹,碧玉赤苓枳陈辅, 清胆利湿又和胃,少阳湿热痰浊阻。
3达原饮(开达膜原,辟秽化浊)(瘟疫或疟疾,邪伏膜原)
达原草果槟厚朴,知母黄芩芍甘佐, 辟秽化浊达膜原,邪伏膜原寒热作。
调和肝脾
1.四逆散(透邪解郁,疏肝理脾)(阳郁厥逆证;肝脾气郁证)
阳郁厥逆四逆散,等分柴芍枳实甘, 透邪解郁理肝脾,肝郁脾滞力能堪。
2.逍遥散(疏肝解郁,养血理脾)(肝郁血虚脾弱证)
逍遥散用当归芍,柴苓术草加姜薄, 肝郁血虚脾气弱,调和肝脾功效卓。
3.痛泻要方(补脾柔肝,祛湿止泻)(脾虚肝郁之痛泻)
痛泻要方用陈皮,术芍防风共成剂, 肠鸣泄泻腹又痛,治在泻肝与实脾。
4.当归芍药散 (养血调肝,健脾利湿)(主治妇人肝郁气滞,脾虚血少,肝脾不和之证)
当归芍药用川芎,白术泽泻六味同, 妊娠腹中绵绵痛,调肝理脾可为功。
调和寒热
1。半夏泻心汤(寒热平调,散结消痞)(寒热互结之痞证)
半夏泻心配芩连,干姜人参草枣全, 辛开苦降除痞满,寒热错杂痞证蠲。
2.生姜泻心汤(和胃消痞,散结除水)(水热互结)
半夏泻心汤减干姜(2两)加生姜(4两) 干姜:生姜=1:4
3.甘草泻心汤(益气和胃,消痞止呕)(胃气虚弱痞证)
半夏泻心汤加甘草(1两) 甘草4两
清热剂
清气分热
1.白虎汤(清热生津)(阳明气分热盛证)
白虎膏知粳米甘,清热生津止渴烦, 气分热盛四大证,益气生津人参添。
2.竹叶石膏汤(清热生津,益气和胃)(伤寒,温病,暑病余热未清,气津两伤证)
竹叶石膏参麦冬,半夏粳米甘草从, 清补气津又和胃,余热耗伤气津用。
3.栀子豉汤 (清热除烦)(伤寒误汗下后,胸膈郁热,心烦懊恼)
栀子+豆豉
清营凉血
1.清营汤(清营解毒,透热养阴)(热入营分证)
清营汤治热传营,身热燥渴眠不宁, 犀地银翘玄连竹,丹麦清热更护阴。
2.犀角地黄汤(清热解毒,凉血散瘀)(热入血分证)
犀角地黄芍药丹,清热凉血散瘀专, 热入血分服之安,蓄血伤络吐衄斑。
气血两清
1.清瘟败毒散(清热解毒,凉血泻火)(温病气血两燔证)
清瘟败毒地连芩,丹膏栀草竹叶临, 犀角玄翘知芍桔,清热解毒亦滋阴。
清热解毒
1.凉膈散(泻火通便,清上泻下)(上中二焦火热证)
凉膈硝黄栀子翘,黄芩甘草薄荷饶, 再加竹叶调蜂蜜,上中郁热服之消。
2.普济消毒饮(清热解毒,疏风散邪)(大头瘟)
普济消毒蒡芩连,甘桔蓝根勃翘玄, 升柴陈薄僵蚕入,大头瘟毒服之痊。
3.仙方活命饮(清热解毒,消肿溃坚,活血止痛)(痈疡肿毒初起)
仙方活命君银花,归芍乳没陈皂甲, 防芷贝粉甘酒煎,阳证痈疡内消法。
4.黄连解毒汤(泻火解毒)(三焦火毒热盛证)
黄连解毒柏栀芩,三焦火盛是主因, 烦狂火热兼谵妄,吐衄发斑皆可平。
5.五味消毒饮(清热解毒,消散疔疮)(火毒结聚之疔疮)
五味消毒疗诸疔,银花野菊蒲公英, 紫花地丁天癸子,煎加酒服效非轻。
6.四妙勇安汤(清热解毒,活血止痛)(热毒炽盛之脱疽)
四妙勇安用当归,玄参银花甘草随, 清热解毒兼活血,脱疽之病此方魁。
7.牛蒡解肌汤(解肌清热,化痰消肿)(风火痰热上攻之痈疮,牙痛)
牛蒡解肌薄荆翘,丹栀斛玄夏枯草, 疏风清热散痈肿,牙痛颈毒皆可消。
清脏腑热
1.龙胆泻肝汤(清泻肝胆实火,清利肝经湿热)(肝胆实火上炎证;肝经湿热下注证)
龙胆栀芩酒拌炒,木通泽泻车柴草, 当归生地益阴血,肝胆实火湿热消。
2.左金丸(清泻肝火,降逆止呕)(肝火犯胃证)
左金连萸六一比,胁痛呑酸悉能医, 再加芍药名戊己,专治泄痢痛在脐。
3.泻白散(清泻肺热,止咳平喘)(肺热咳喘证)
泻白桑皮地骨皮,粳米甘草扶肺气, 清泻肺热平和剂,热伏肺中喘咳医。
4.清胃散(清胃凉血)(胃火牙痛)
清胃散中当归连,生地丹皮升麻全, 或加石膏泻胃火,能消牙痛与牙宣。
5.玉女煎(清胃热,滋肾阴)(胃热阴虚证)
玉女石膏熟地黄,知母麦冬牛膝襄, 肾虚胃火相为病,牙痛齿衄宜煎尝。
6.芍药汤(清热燥湿,调和气血)(湿热痢疾)
芍药汤内用槟黄,芩连归桂草木香, 重在调气兼行血,里急便脓自然康。
7.白头翁汤(清热解毒,凉血止痢)(热毒痢疾)
白头翁治热毒痢,黄连黄柏佐秦皮, 清热解毒并凉血,赤多白少脓血医。
8.导赤散(清心利水养阴)(心经火热证)
导赤木通生地黄,草梢煎加竹叶尝, 清心利水又养阴,心经火热移小肠。
9.苇茎汤(清肺化痰,逐瘀排脓)(肺痈,热毒壅滞,痰瘀互结证)
苇茎瓜瓣苡桃仁,清肺化痰逐瘀能, 热毒痰瘀致肺痈,脓成未成均胜任。
10.泻黄散 (泻脾胃伏火)(脾胃伏火证)
泻黄甘草与防风,石膏栀子藿香充, 炒香蜜酒调和服,胃火口疮并见功。
清虚热
1.青蒿鳖甲汤(养阴透热)(温病后期,邪伏阴分证)
青蒿鳖甲知地丹,热自阴来仔细看, 夜热早凉无汗出,养阴透热服之安。
2.清骨散(清虚热,退骨蒸)(肝肾阴虚,虚火内扰证)
清骨散君银柴胡,胡连秦艽鳖甲辅, 地骨青蒿知母草,骨蒸劳热一并除。
3.秦艽鳖甲散(滋阴养血,清热除蒸)(阴亏血虚,风邪传里化热之风劳病)
秦艽鳖甲治风劳,地骨柴胡及青蒿, 当归知母乌梅合,止嗽除蒸敛汗超。
4.当归六黄汤(滋阴泻火,固表止汗)(阴虚火旺盗汗)
火炎汗出六黄汤,归柏芩连二地黄, 倍用黄芪为固表,滋阴清热敛汗强。
祛暑剂
祛暑解表
1新加香薷饮(祛暑解表,清热化湿)(暑温夹湿,复感于寒)
新加香薷朴银翘,扁豆鲜花一起熬; 暑温口渴汗不出,清热化湿又解表。
2.香薷散 (祛暑解表,化湿和中)(阴暑)
香薷,厚朴,白扁豆
祛暑利湿
1.六一散(清暑利湿)(暑湿证:热,渴,淋,泄)
滑石甘草六一散,清暑利湿功用专, 辰砂黛薄依次加,益元碧玉鸡苏裁。
祛暑益气
1.清暑益气汤(清暑益气,养阴生津)(暑热气津两伤证)
王氏清暑益气汤,暑热气津已两伤, 洋参麦斛粳米草,翠衣荷连知竹尝。
祛暑清热
1.桂苓甘露饮(清暑解热,化气利湿)(暑湿证)
桂苓甘露滑石膏,寒水猪苓泽术草, 清暑化气利水湿,暑湿俱盛重证疗。
2.清络饮(祛暑清热)(暑伤肺经,气分轻证)
清络祛暑六药鲜,银扁翠衣瓜络添, 佐以竹叶荷叶边,暑热伤肺轻证安。
温中祛寒
1.理中丸(温中祛寒,补气健脾)(①脾胃虚寒证;②阳虚失血证;③脾胃虚寒所致的胸痹或病后多涎唾或小儿慢惊)
理中干姜参术甘,温中健脾治虚寒, 中阳不足痛呕利,丸汤两用腹中暖。
2.小建中汤(温中补虚,和里缓急)(中焦虚寒,肝脾失调,阴阳不和证)
小建中汤君饴糖,方含桂枝加芍汤, 温中补虚和缓急,虚劳里急腹痛康。
附:⑴黄芪建中汤(温中补气,和里缓急)(阴阳气血两虚证) 小建中汤加黄芪一两半 ⑵当归建中汤(温补气血,缓急止痛)(产后虚羸不尽;小腹拘挛疼痛引腰背) 小建中汤去饴糖、桂枝加桂心、当归
3.大建中汤(温中补虚,降逆止痛)(中阳虚弱,阴寒内盛之脘腹剧痛证)
大建中汤建中阳,蜀椒干姜参饴糖, 阴盛阳虚腹冷痛,温补中焦止痛强。
4.吴茱萸汤(温中补虚,降逆止呕)(①胃寒呕吐证;②肝寒上逆证;③肾寒上逆证)
吴茱萸汤重用姜,人参大枣共煎尝 , 厥阴头痛胃寒呕,温中补虚降逆良。
温里剂
回阳救逆
1.四逆汤(回阳救逆)(少阴病,心肾阳衰寒厥证)
四逆汤中附草姜,阳衰寒厥急煎尝, 腹痛吐泻脉沉细,急投此方可回阳。
附:①通脉四逆汤(破阴回阳,通达内外)(少阴病,阴盛格阳证) ②四逆加人参汤(回阳救逆,益气固脱)(少阴病,亡阳脱液) ③白通汤(破阴回阳,宣通上下)(少阴病,阴盛戴阳证) ④参附汤(益气回阳固脱)(阳气暴亡证)
2.回阳救急汤(回阳固脱,益气生脉)(寒邪直中三阴,真阳衰微证)
回阳救急用六君,桂附干姜五味群, 加麝三厘或胆汁,三阴寒厥建奇勋。
温经散寒
1.当归四逆汤(温经散寒,养血通脉)(血虚寒厥证)
当归四逆用桂芍,细辛通草甘大枣, 温经养血通脉剂,血虚寒厥服之效。
2.阳和汤(温阳补血,散寒通滞)(阳虚寒凝之阴疽)
阳和熟地鹿角胶,姜炭肉桂麻芥草, 温阳补血散寒滞,阳虚寒凝阴疽疗。
3.黄芪桂枝五物汤(益气温经,和血通痹)(血痹证:肌肤麻木不仁)
黄芪桂枝五物汤,芍药大枣与生姜, 益气温经和营卫,血痹风痹功效良。
表里双解剂
解表攻里
1.大柴胡汤(和解少阳,内泻热结)(少阳阳明合病)
大柴胡汤用大黄,枳芩夏芍枣生姜, 少阳阳明同合病,和解攻里效无双。
2.防风通圣汤(疏风解表,泻热通便)(①风热壅盛,表里俱实证;②疮疡肿毒,肠风痔漏,丹斑瘾疹)
防风通圣大黄硝,荆芥麻黄栀芍翘; 甘桔芎归膏滑石,薄荷芩术力偏饶. 表里交攻阳热盛,外科疡毒总能消。
解表清里
1.葛根黄芩黄连汤(解表清里,升清止泻)(表证未解,邪热入里证)
葛根芩连甘草伍,用时先将葛根煮, 内清肠胃外解表,协热下利喘汗除。
2.石膏汤(清热解毒,发汗解表)(壮热无汗,伤寒表证)
石膏汤用芩柏连,麻黄豆豉山栀全, 清热解毒兼解表,枣姜细茶一同煎。
解表温里
1.五积散(发表温里,顺气化痰,活血消积)(外感风寒,内伤生冷证)
五积消滞又温中,麻黄苍芷芍归芎, 枳桔桂苓甘草朴,两姜陈皮半夏从。
补益剂
补气
1.四君子汤(益气健脾)(脾胃虚弱证)
四君子汤中和义,人参苓术甘草比, 益气健脾基础剂,脾胃气虚治相宜。
2.参苓白术散(益气健脾,渗湿止泻)(脾虚夹湿证)
参苓白术扁豆陈,莲草山药砂苡仁, 桔梗上浮兼保肺,枣汤调服益脾神。
3.完带汤(补脾疏肝,化湿止带)(脾虚肝郁,湿浊带下)
完带汤中二术陈,人参甘草车前仁, 柴芍怀山黑芥穗,化湿止带此方神。
4.补中益气汤(补中益气,升阳举陷)(中气不足;气虚下陷;气虚发热)
补中益气芪参术,炙草升柴归陈助, 清阳下陷能升举,气虚发热甘温除。
5.生脉散(益气生津,敛阴止汗)(温热、暑热耗气伤阴证;久咳伤肺,气阴两虚证)
生脉麦味与人参,保肺清心治暑淫, 气少汗多兼口渴,病危脉绝急煎斟。
6.玉屏风散(益气固表止汗)(①表虚自汗;②虚人腠理不固,易感风邪)
玉屏组合少而精,芪术防风鼎足形。 表虚汗多易感冒,固卫敛汗效特灵。
补血
1.四物汤(补血调血)(营血虚滞证;治外伤瘀血作痛,妇人诸疾)
四物熟地归芍芎,补血调血此方宗, 营血虚滞诸多症,加减运用贵变通。
2.归脾汤(益气补血,健脾养心)(心脾气血两虚证;脾不统血证)
归脾汤用术参芪,归草茯神远志齐, 酸枣木香龙眼肉,煎加姜枣益心脾。
3.当归补血汤(补气生血)(血虚阳浮发热证)
当归补血君黄芪,芪归用量五比一, 补气生血代表剂,血虚发热此方宜。
4.内补黄芪汤(补益气血,养阴生肌)(痈疽溃后,气血皆虚)
内补黄芪地芍冬,参苓远志加川芎, 当归甘草官桂并,力补痈疽善后功。
气血双补
1.泰山磐石散(益气健脾,养血安胎)(气血虚弱所致的堕胎、滑胎)
泰山磐石八珍选,去苓加芪芩断联, 再益砂仁及糯米,妇人胎动可安全。
2.八珍汤 (益气补血)(气血两虚证)
气血双补八珍汤,四君四物合成方, 煎加姜枣调营卫,气血亏虚服之康。
3.人参养荣汤 (益气补血)(脾肺气虚,荣血不足证)
人参养荣即十全,除却川芎五味联, 陈皮远志加姜枣,脾肺气血补方先。
补阴
1.六味地黄丸(填精滋补肝肾)(肾阴精不足证)
六味地黄山药萸,泽泻苓丹三泻侣,三阴并补重滋肾,肾阴不足效可居, 滋阴降火知柏需,养肝明目加杞菊,都气五味纳肾气,滋补肺肾麦味续。
2.左归丸(滋阴补肾,填精益髓)(真阴不足证)
左归丸内山药地,萸肉枸杞与牛膝, 菟丝龟鹿二胶合,壮水之主方第一。
3.左归饮 (补益肾阴)(真阴不足证)
补肾滋阴左归饮,熟地山药山茱萸, 枸杞苓草同煎服,肾阴亏虚此方医。
4.大补阴丸(滋阴降火)(阴虚火旺证)
大补阴丸知柏黄,龟板脊髓蜜丸方, 咳嗽咯血骨蒸热,阴虚火旺制亢阳。
5.虎潜丸(滋阴降火,强壮筋骨)(肝肾不足,阴虚内热之痿证)
虎潜足痿是妙方,虎骨陈皮并锁阳, 龟板干姜知母芍,再加柏地作丸尝。
6.一贯煎(滋阴疏肝)(肝肾阴虚,肝气郁滞证;疝气瘕聚)
一贯煎中生地黄,沙参归杞麦冬藏, 少佐川楝泄肝气,阴虚胁痛此方良。
7.补肺阿胶汤(养阴补肺,镇咳止血)(肺虚热盛)
补肺阿胶马兜铃,牛蒡甘草杏糯匀, 肺虚火盛最宜服,降气生津咳嗽宁。
8.石斛夜光丸 (滋阴补肾,清肝明目)(肝肾两亏,阴虚火旺证)
石斛夜光枳膝芎,二地二冬杞丝蓉,青葙草决菊杏草,味参连苓蒺草风, 再入犀羚清虚热,养阴明目第一功。
9.人参蛤蚧散 (益气清肺,止咳定喘)(咳久气喘,痰稠色黄)
人参蛤蚧作散服,杏苓桑皮草二母, 肺肾气虚蕴痰热,咳喘痰邪一并除。
补阳
1.肾气丸(补肾助阳,化生肾气)(肾阳气不足证;痰饮、水肿、消渴、脚气、转胞)
肾气丸主肾阳虚,干地山药及山萸,少量桂附泽苓丹,水中生火在温煦, 济生加入车牛膝,温肾利水消肿需,十补丸有鹿茸味,主治肾阳精血虚。
2.右归丸(温补肾阳,填精益髓)(肾阳不足,命门火衰证)
右归丸中地附桂,山药茱萸菟丝归, 杜仲鹿胶枸杞子,益火之源此方魁。
3.右归饮 (温补肾阳,填精补血)(肾阳不足证)
右归饮中用附桂,地杞茱药杜草配, 鹿菟当归易炙草,丸能温阳添精髓。
阴阳并补
1.地黄饮子(滋肾阴,补肾阳,化痰开窍)(下元虚衰,痰浊上积之喑痱证)
地黄饮萸麦味斛,苁戟附桂阴阳补, 化痰开窍菖远茯,加薄姜枣喑痱服。
2.龟鹿二仙胶 (滋阴填精,益气壮阳)(真元虚损,精血不足证)
龟鹿二仙最守真,补人三宝精气神, 人参枸杞和龟鹿,丸能温阳添精髓。
3.七宝美髯丹 (补益肝肾,乌发壮骨)(治肝肾不足证)
七宝美髯何首乌,菟丝牛膝茯苓俱, 骨脂枸杞当归合,专益肝肾精血虚。
气血阴阳并补
1.炙甘草汤(滋阴养血,益气温阳,复脉定悸)(①阴阳气血虚弱,心脉失养证;②虚劳肺痿)
炙草人参枣地胶,麻仁麦桂姜酒熬,益气养血温通脉,结代心悸肺痿疗, 加芍去参姜桂枣,加减复脉滋阴饶。
固涩剂
固表止汗
1.牡蛎散(敛阴止汗,益气固表)(体虚自汗盗汗证)
牡砺散内用黄芪,麻黄根与小麦齐, 益气固表又敛阴,体虚自汗盗汗宜。
敛肺止咳
1.九仙散(敛肺止咳,益气养阴)(久咳肺虚证)
九仙罂粟乌梅味,参胶桑皮款桔贝, 敛肺止咳益气阴,久咳肺虚效堪谓。
涩肠固脱
1.真人养脏汤(涩肠固脱,温补脾肾)(久泻久痢,脾肾虚寒证)
真人养脏木香诃,当归肉蔻与粟壳, 术芍参桂甘草共,脱肛久痢服之瘥。
2.四神丸 (温肾暖脾,固肠止泻)(脾肾阳虚之肾泻证)
四神故纸与吴萸,肉蔻五味四般齐, 大枣生姜同煎合,五更肾泻最相宜。
涩精止遗
1.桑螵蛸散(调补心肾,涩精止遗)(心肾两虚之尿频或遗尿,遗精证)
桑螵蛸散龙龟甲,参归茯神菖远加, 调补心肾又涩精,心肾两虚尿频佳。
2.金锁固精丸 (涩精补肾)(肾虚不固之遗精)
金锁固精芡莲须,龙骨牡砺与蒺藜, 莲粉糊丸盐汤下,补肾涩精止滑遗。
3.缩泉丸 (温肾祛寒,缩尿止遗)(膀胱虚寒证)
缩泉丸治儿尿频,脬气虚寒约失灵, 山药台乌加益智,糊丸多服效显明。
固崩止带
1.固冲汤 (益气健脾,固冲摄血)(脾气虚弱,冲脉不固证)
固冲芪术山萸芍,龙牡倍榈茜海蛸, 益气健脾固摄血,脾虚冲脉不固疗。
2.固经丸 (滋阴清热,固精止血)(阴虚血热之崩漏)
固经龟板芍药芩,黄柏椿根香附应, 阴虚血热经量多,滋阴清热能固经。
3.易黄汤 (补益脾肾,清热祛湿,收涩止带)(脾肾虚弱,湿热带下)
易黄山药与芡实,白果黄柏车前子, 固肾清热又祛湿,肾虚湿热带下医。
4.清带汤 (滋阴收涩,化瘀止带)(妇女赤白带下)
清带汤中薯茜草,龙骨牡蛎海螵蛸, 赤带二钱芍苦参,白带三钱术鹿角。
安神剂
镇心安神
1.朱砂安神丸(镇心安神,清热养血)(心火亢盛,阴血不足)
朱砂安神东垣方,归连甘草合地黄, 怔忡不寐心烦乱,养阴清热可复康。
2.磁朱丸(重镇安神,潜阳明目)(心肾不交;癫痫)
磁朱丸中有神曲,安神潜阳又明目, 心悸失眠皆可治,癫狂痫证亦宜服。
3.珍珠母丸(滋阴养血,镇心安神)(阴血不足,肝阳偏亢)
珍珠母丸参地归,犀沉龙齿柏茯神, 更加酸枣宁神志,镇心平肝此方推。
补养安神
1.天王补心丹(滋阴养血,补心安神)(阴虚血少,神志不安证)
补心地归二冬仁,远茯味砂桔三参, 阴亏血少生内热,滋阴养血安心神。
2.酸枣仁汤(养血安神,清热除烦)(肝血不足,虚热内扰之虚烦不眠证)
酸枣仁汤治失眠,川芎知草茯苓煎, 养血除烦清虚热,安然入睡梦乡甜。
3.甘麦大枣汤(养心安神,和中缓急;亦补脾气)(脏躁)
甘草小麦大枣汤,妇人脏躁性反常, 精神恍惚悲欲哭,和肝滋脾自然康。
4.交泰丸 (交通心肾,清火安神)(心火偏亢,心肾不交)
心肾不交交泰丸,一份桂心六份连, 怔忡不寐心阳亢,心肾交时自然寐。
开窍剂
凉开
1.安宫牛黄丸(清热解毒,豁痰开窍)(邪热内陷心包证)
安宫牛黄开窍方,芩连栀郁朱雄黄, 犀角真珠冰麝箔,热闭心包功用良。
2.紫雪(清热开窍,息风止痉)(热闭心包,热盛动风证)
紫雪犀羚朱朴硝,硝石金寒滑磁膏, 丁沉木麝升玄草,热陷痉厥服之消。
3.至宝丹(化浊开窍,清热解毒)(痰热内闭心包证)
至宝朱珀麝息香,雄玳犀角与牛黄, 金银两箔兼龙脑,开窍清热解毒良。
温开
1.紫金锭<玉枢丹>(化痰开窍,辟秽解毒,消肿止痛)(感受秽恶痰浊之邪)
紫金锭有朱雄菇,五倍千金一并入, 大戟麝香共为末,霍乱痧胀米汤服。
2.苏合香丸<吃力伽丸>(芳香开窍,行气止痛)(寒闭证;心腹猝痛,甚则昏厥,属寒凝气滞者)
苏合香丸麝息香,木丁熏陆荜檀襄, 犀冰术沉诃香附,再加龙脑温开方。
理气剂
行气
1.半夏厚朴汤(行气散结,降逆化痰)(梅核气)
半夏厚朴与紫苏,茯苓生姜共煎服, 痰凝气聚成梅核,降逆开郁气自舒。
2.越鞠丸(行气解郁)(六郁证)
行气解郁越鞠丸,香附芎苍栀曲研, 气血痰火湿食郁,随证易君并加减。
3.金铃子散(疏肝泻热,活血止痛)(肝郁化火证)
金铃延胡等分研,黄酒调服或水煎, 疏肝泄热行气血,肝郁化火诸痛蠲。
4.枳实薤白桂枝汤(通阳散结,祛痰下气)(胸阳不振,痰气互结之胸痹)
枳实薤白桂枝汤,厚蒌合治胸痹方, 胸阳不振痰气结,通阳散结下气强。
5.瓜蒌薤白白酒汤(通阳散结,行气祛痰)(胸阳不振,痰气互结之胸痹轻证)
瓜萎薤白白酒汤,胸痹胸闷痛难当, 喘息短气时咳唾,难卧仍加半夏良。
6.天台乌药散(行气疏肝,散寒止痛)(肝经寒凝气滞证)
天台乌药木茴香,青姜巴豆制楝榔, 行气疏肝散寒痛,寒滞疝痛酒调尝。
7.暖肝煎(温补肝肾,行气止痛)(肝肾不足,寒滞肝脉证)
暖肝煎中桂茴香,归杞乌沉茯加姜, 温补肝肾散寒气,肝肾虚寒疝痛康。
8.枳实消痞丸(消痞除满,健脾和胃)(脾虚气滞,寒热互结证)
枳实消痞四君全,麦芽夏曲朴姜连, 脾虚痞满结心下,痞消脾健乐天年。
9.厚朴温中汤(行气除满,温中燥湿)(脾胃气滞寒湿证)
厚朴温中苓陈草,干姜生姜一齐熬, 行气燥湿蔻木香,脘腹胀痛服之消。
10.橘核丸(行气止痛,软坚散结)(寒湿疝气<颓疝证>)
橘核丸中楝桂存,枳朴延胡藻带昆, 桃仁木通木香合,癞疝顽痛盐酒吞。
11.柴胡疏肝散 (疏肝行气,活血止痛)(肝气郁滞证)
柴胡疏肝芍川芎,枳壳陈皮草香附, 疏肝行气兼活血,胁肋疼痛立能除。
12.加味乌药汤 (行气活血,调经止痛)(主治肝郁气滞之痛经)
加味乌药汤砂仁,香附木香姜草伦, 配入延胡共七味,经前胀痛效堪珍。
降气
1.苏子降气汤(降气平喘,祛痰止咳)(上实下虚之喘咳证)
苏子降气祛痰方,夏朴前苏甘枣姜, 肉桂纳气归调血,上实下虚痰喘康。
2.定喘汤(宣降肺气,清热化痰)(痰热内蕴,风寒外束之哮喘)
定喘白果与麻黄,款冬半夏白皮桑, 苏子黄芩甘草杏,宣肺平喘效力彰。
3.旋覆代赭汤(降逆化痰,益气和胃)(胃虚痰气逆阻证)
旋覆代赭重用姜,半夏人参甘枣尝, 降逆化痰益胃气,胃虚痰阻痞嗳康。
4.橘皮竹茹汤(降逆止呃,益气清热)(胃虚有热之呃逆)
橘皮竹茹重姜枣,参草益气共煎熬, 降逆止呃又清热,胃虚有热呃逆疗。
5.四磨汤 (补气降逆,宽胸散结)(主治七情所伤,肝气郁结证)
四磨饮子七情侵,人参乌药及槟沉, 浓磨煎服调滞气,实者枳壳易人参。
去参加入木香枳,五磨饮子白酒斟,
六磨饮子入大黄,降气通便效为尊。
理血剂
活血祛瘀
1.桃核承气汤(逐瘀泻热)(下焦蓄血证)
桃核承气硝黄草,少佐桂枝温经妙, 下焦蓄血小腹胀,泻热破瘀微利效。
2血府逐瘀汤(活血化瘀,行气止痛)(胸中血瘀证)
血府当归生地桃,红花甘草壳赤芍, 柴胡芎桔牛膝等,血化下行不作劳。
附:通窍全凭好麝香,桃红大枣老葱姜,归芎黄酒赤芍药,表里通经第一方。(活血通窍)(瘀阻头面证) 膈下逐瘀桃牡丹,赤芍乌药玄胡甘,归芎灵脂红花壳,香附开郁血亦安。(活血祛瘀,行气止痛)(瘀血阻滞膈下证) 少腹茴香与炒姜,元胡灵脂没芎当,蒲黄官桂赤芍药,调经种子第一方。(活血祛瘀,温经止痛)(寒凝血瘀证) 身痛逐瘀桃归芎,香附羌秦脂地龙,牛膝红花没药草,通络止痛力量雄。 (活血行气,祛瘀通络,通痹止痛)(瘀血组滞经络证)
3.补阳还五汤(补气活血通络)(气虚血瘀之中风)
补阳还五赤芍芎,归尾通经佐地龙, 四两黄芪为主药,血中瘀滞用桃红。
4.复元活血汤(活血祛瘀,疏肝通络)(跌打损伤,淤血阻滞证)
复元活血酒军柴,桃红归甲蒌根甘, 祛瘀疏肝又通络,损伤瘀痛加酒煎。
5.温经汤(温经散寒,养血祛瘀)(冲任虚寒,淤血阻滞证)
温经汤用萸桂芎,归芍丹皮姜夏冬, 参草益脾胶养血,调经重在暖胞宫。
6.生化汤(养血活血,温经止痛)(血虚寒凝,瘀血阻滞证)
生化汤是产后方,归芎桃草酒炮姜, 消瘀活血功偏擅,止痛温经效亦彰。
7.七厘散(活血定痛,散瘀止血)(跌打损伤,筋断骨折之瘀血肿痛或刀伤出血;一切无名肿毒、烧伤、烫伤)
七厘散治跌打伤,血竭红花冰麝香, 乳没儿茶朱共末,外敷内服均见长。
8.失笑散(活血祛瘀,散结止痛)(瘀血停滞证)
失笑灵脂蒲黄同,等量为散酽醋冲, 瘀滞心腹时作痛,祛瘀止痛有奇功。
9.桂枝茯苓丸(活血化瘀,缓消癥块)(瘀阻胞宫证)
金匮桂枝茯苓丸,桃仁芍药与牡丹, 等分为末蜜丸服,缓消癥块胎可安。
10.活络效灵丹(活血祛瘀,通络止痛)(气血凝滞证)
活络效灵主丹参,当归乳香没药存: 癥瘕积聚腹中痛,活血祛瘀通络痛。
11.大黄廑虫丸(活血消癥,祛瘀生新)(五劳虚极<瘀血内停之干血痨>)
大黄廑虫芩芍桃,地黄杏草漆蛴螬, 虻虫水蛭和丸服,祛淤生新功独超。
12.丹参饮 (活血祛瘀,行气止痛)(主血瘀气滞,心胃诸痛)
丹参饮中用檀香,砂仁合用成妙方, 血瘀气滞两相结,心胃诸通用之良。
止血
1.十灰散(凉血止血)(血热妄行之上部出血证)
十灰散用十般灰,柏茅茜荷丹榈煨, 二蓟栀黄各炒黑,上部出血势能摧。
2.咳血方(清肝宁肺,凉血止血)(肝火犯肺之咳血证)
咳血方中诃子收,瓜蒌海粉山栀投, 青黛蜜丸口噙化,咳嗽痰血服之瘳。
3.小蓟饮子(凉血止血,利水通淋)(热结下焦之血淋、尿血)
小蓟饮子藕蒲黄,木通滑石生地襄, 归草黑栀淡竹叶,血淋热结服之凉。
4.槐花散(清肠止血,疏风行气)(风热湿毒,壅遏肠道,损伤血络便血证)
槐花侧柏荆枳壳,等分为末米饮调, 清肠止血又疏风,血热肠风脏毒疗。
5.黄土汤(温阳健脾,养血止血)(脾阳不足,脾不统血)
黄土汤中芩地黄,术附阿胶甘草尝, 温阳健脾能摄血,便血崩漏服之康。
6.胶艾汤(养血止血,调经安胎)(妇人冲任虚损血虚有寒证;妊娠胞阻,胎漏)
胶艾汤中四物先,更加炙草一同煎, 暖宫养血血行缓,胎漏崩中自可痊。
治风剂
疏散外邪
1.川芎茶调散(疏风止痛)(外感风邪头痛)
川芎茶调有荆防,辛芷薄荷甘草羌, 目昏鼻塞风攻上,偏正头痛悉能康。
2.大秦艽汤(祛风通络,养血活血)(风邪初中经络证)
大秦艽汤羌独防,辛芷芎芍二地当, 苓术石膏黄芩草,风邪初中经络康。
3.消风散(疏风养血,清热除湿)(风疹、湿疹)
消风散中有荆防,蝉蜕胡麻苦参苍, 知膏蒡通归地草,风疹湿疹服之康。
4.牵正散(祛风化痰,通络止痉)(风痰阻于头面经络所致口眼斜)
牵正散治口眼斜,白附僵蚕合全蝎, 等分为末热酒下,祛风化痰痉能解。
5.小活络丹(祛风除湿,化痰通络,活血止痛)(风寒湿痹)
小活络祛风湿寒,化痰活血三者兼, 二乌南星乳没龙,寒湿痰瘀痹痛蠲。
6.玉真散 (祛风化痰,定搐止痉)(破伤风)
玉真散治破伤风,牙关紧急反张弓, 星麻白附羌防芷,外敷内用一方通。
平息内风
1.羚角钩藤汤(凉肝息风,增液舒筋)(肝热生风证)
羚角钩藤菊花桑,地芍贝茹茯草襄, 凉肝熄风又养阴,肝热生风急煎尝。
2.镇肝熄风汤(镇肝息风,滋阴潜阳)(类中风)
镇肝熄风芍天冬,玄参龟板赭茵从, 龙牡麦芽膝草楝,肝阳上亢能奏功。
3.天麻钩藤饮(平肝息风,清热活血,补益肝肾)(肝阳偏亢,肝风上扰证)
天麻钩藤石决明,栀杜寄生膝与芩, 夜藤茯神益母草,主治眩晕与耳鸣。
4.大定风珠(滋阴息风)(阴虚风动证)
大定风珠鸡子黄,麦地胶芍草麻襄, 三甲并同五味子,滋阴熄风是妙方。
5.阿胶鸡子黄汤(滋阴养血,柔肝息风)(邪热久羁,阴血不足,虚风内动)
阿胶鸡子黄汤好,地芍钩藤牡蛎草, 决明茯神络石藤,阴虚风动此方保。
治燥剂
清宣外燥
1.杏苏散(清宣凉燥,理肺化痰)(外感凉燥证)
杏苏散内夏陈前,枳桔苓草姜枣研, 轻宣温润治凉燥,咳止痰化病自痊。
2.桑杏汤(清宣温燥,润肺止咳)(外感温燥证)
桑杏汤中浙贝宜,沙参栀豉与梨皮, 干咳鼻涸又身热,清宣凉润温燥医。
3.清燥救肺汤(清燥润肺,益气养阴)(温燥伤肺证)
清燥救肺桑麦膏,参胶胡麻杏杷草, 清宣润肺养气阴,温燥伤肺气阴耗。
滋阴润燥
1.麦门冬汤(滋养肺胃,降逆下气)(虚热肺痿;胃阴不足证)
麦门冬汤用人参,枣草粳米半夏存, 肺痿咳逆因虚火,清养肺胃此方珍。
2.养阴清肺汤(养阴清肺,解毒利咽)(阴虚肺燥之白喉)
养阴清肺是妙方,玄参草芍冬地黄, 薄荷贝母丹皮入,时疫白喉急煎尝。
3.百合固金汤(滋养肺阴,止咳化痰)(肺肾阴亏,虚火上炎证)
百合固金二地黄,玄参贝母桔草藏, 麦冬芍药当归配,喘咳痰血肺家伤。
4.琼玉膏(滋阴润肺,益气补脾)(肺肾阴亏之肺痨)
琼玉膏用生地黄,人参茯苓白蜜糖, 合成膏剂缓缓服,干咳咯血肺阴伤。
5.玉液汤(益气滋阴,固肾止渴)(气阴两虚之消渴)
玉液汤中芪葛根,鸡金知味药花粉, 饮一溲一消渴证,益气生津显效能。
6.增液汤(增液润燥)(阳明温病,津亏便秘证)
增液玄参与地冬,热病津枯便不通, 补药之体作泻剂,若非重用不为功。
7.益胃汤 (滋养胃阴)(主治阳明温病,胃阴损伤证)
益胃汤能养胃阴,冰糖玉竹与沙参, 麦冬生地同煎服,温病须虑热伤阴。
祛湿剂
化湿和胃
1.平胃散(燥湿运脾,行气和胃)(湿滞脾胃证)
平胃散内君苍术,厚朴陈草姜枣煮, 燥湿运脾又和胃,湿滞脾胃胀满除。
2.藿香正气散(解表化湿,理气和中)(外感风寒,内伤湿滞证)
藿香正气大腹苏,甘桔陈苓术朴俱, 夏曲白芷加姜枣,风寒暑湿并能除。
清热祛湿
1.茵陈蒿汤(清热利湿退黄)(湿热黄疸)
茵陈蒿汤治阳黄,栀子大黄组成方, 栀子柏皮加甘草,茵陈四逆治阴黄。
2.八正散(清热泻火,利水通淋)(湿热淋证)
八正木通与车前,萹蓄大黄栀滑研, 草梢瞿麦灯心草,湿热诸淋宜服煎。
3.三仁汤(宣畅气机,清利湿热)(湿温初起或暑温夹湿之湿重于热证)
三仁杏蔻薏苡仁,朴夏通草滑竹存, 宣畅气机清湿热,湿重热轻在气分。
4.连朴饮(清热化湿,理气和中)(湿热霍乱)
连朴饮用香豆豉,菖蒲半夏焦山栀, 芦根厚朴黄连入,湿热霍乱此方施。
5.甘露消毒丹(利湿化浊,清热解毒)(湿温时疫之湿热并重证)
甘露消毒蔻藿香,茵陈滑石木通菖, 芩翘贝母射干薄,湿热时疫是主方。
6.二妙散 (清热燥湿)(主湿热下注证)
二妙散中苍柏兼,若云三妙牛膝添, 再加苡仁名四妙,湿热下注痿痹痊。
7.当归拈痛汤 (利湿清热,疏风止痛)(湿热相搏,外受风邪证)
当归拈痛羌防升,猪泽茵陈芩葛人, 二术苦参知母草,疮疡湿热服皆应。
利水渗湿
1.五苓散(利水渗湿,温阳化气)(①膀胱气化不利之蓄水证;②水湿内停;③痰饮:脐下动悸)
五苓散治太阳腑,白术泽泻猪苓茯, 桂枝化气兼解表,小便通利水饮逐。
2.猪苓汤(利水渗湿,养阴清热)(水热互结伤阴证)
猪苓汤内有茯苓,泽泻阿胶滑石并, 小便不利兼烦渴,滋阴利水症自平。
3.防己黄芪汤(益气祛风,健脾利水)(表虚不固之风水或风湿)
金匮防己黄芪汤,白术甘草加枣姜, 益气祛风行水良,表虚风水风湿康。
4.五皮散 (利水消肿,行气祛湿)(脾虚湿盛,气滞水泛之皮水)
五皮散用五般皮,陈茯姜桑大腹齐, 或以五加易桑白,脾虚肤胀此方施
温化寒湿
1.苓桂术甘汤(温阳化饮,健脾利水)(中阳不足之痰饮)
苓桂术甘仲景剂,温阳化饮又健脾, 中阳不足饮停胃,胸胁支满悸眩施。
2.真武汤(温阳利水)(阳虚水泛证;太阳病发汗太过阳虚水泛证)
真武汤壮肾中阳,茯苓术芍附生姜, 少阴腹痛有水气,悸眩瞤惕保安康。
3.实脾散(温阳健脾,行气利水)(脾肾阳虚,水气内停之阴水)
实脾苓术与木瓜,甘草木香大腹加, 草果姜附兼厚朴,虚寒阴水效堪夸。
祛湿化浊
1.萆解分清饮(温肾利湿,分清化浊)(下焦虚寒之膏淋、白浊)
萆薢分清益智仁,菖蒲乌药盐煎成, 下焦虚寒得温利,分清化浊效如神。
祛风胜湿
1.羌活胜湿汤(祛风胜湿止痛)(风湿犯表之痹证)
羌活胜湿独防风,蔓荆藁本草川芎, 祛风胜湿止痛良,善治周身风湿痛。
2.独活寄生汤(祛风湿,止痹痛,益肝肾,补气血)(痹证日久,肝肾两虚,气血不足证)
独活寄生艽防辛,归芎地芍桂苓均, 杜仲牛膝人参草,顽痹风寒湿是因。
祛痰剂
燥湿化痰
1.二陈汤(燥湿化痰,理气和中)(湿痰证)
二陈汤用半夏陈,苓草梅姜一并存; 理气祛痰兼燥湿,湿痰为患此方珍。
2.温胆汤(理气化痰,清胆和胃)(胆胃不和,痰热内扰证)
温胆夏茹枳陈助,佐以茯草姜枣煮, 理气化痰利胆胃,胆郁痰扰诸证除。
润燥化痰
1.贝母瓜蒌散(润肺清热,理气化痰)(燥痰咳嗽)
贝母瓜蒌臣花粉,橘红茯苓加桔梗, 肺燥有痰咳难出,润肺化痰此方珍。
清热化痰
1.清气化痰丸(清热化痰,理气止咳)(痰热咳嗽)
清气化痰胆星蒌,夏芩杏陈枳实投, 茯苓姜汁糊丸服,气顺火清痰热瘳。
2.小陷胸汤(清热化痰,宽胸散结)(痰热互结之小结胸证)
小陷胸汤连半蒌,宽胸开结涤痰优, 膈上热痰痞满痛,舌苔黄腻服之休。
3.滚痰丸 (泻火逐痰)(主治实热老痰证)
滚痰丸用青礞石,大黄黄芩与沉香, 百病多因痰作祟,顽痰怪症力能匡。
温化寒痰
1.三子养亲汤(温化寒痰,降气消食)(痰壅气逆食滞证)
三子养亲祛痰方,芥苏萊菔共煎汤, 大便实硬加熟蜜,冬寒更可加生姜。
2.小半夏汤 (和胃降逆,消痰蠲饮)(痰饮呕吐)
半夏+生姜
3.苓甘五味姜辛汤(温肺化饮)(寒饮内停之咳嗽)
苓甘五味姜辛汤,温肺化饮常用方, 半夏杏仁均可加,寒痰水饮咳嗽康。
治风化痰
1.半夏白术天麻汤(化痰息风,健脾祛湿)(风痰上扰证)
半夏白术天麻汤,苓草橘红枣生姜, 眩晕头痛风痰盛,痰化风熄复正常。
2.止嗽散(宣利肺气,祛痰止咳)(风邪犯肺之咳嗽)
止嗽散桔草白前,紫菀荆陈百部研, 镇咳化痰兼解表,姜汤调服不必煎。
3.定癫丸 (涤痰息风,清热定痫)(痰热内扰之痫病;亦用于癫狂)
定痫二茯贝天麻,丹麦陈莆远半夏, 胆星全蝎蚕琥珀,竹沥姜汁草朱砂。
消食剂
消食化滞
1.保和丸(消食化滞,理气和胃)(食积证)
保和山楂莱菔曲,夏陈茯苓连翘取, 炊饼为丸白汤下,消食和胃食积去。
2.枳术丸(健脾消痞)(脾虚气滞,饮食停聚)
枳术丸是消补方,荷叶烧饭作丸尝, 若加麦芽与神曲,消食化滞力更强。
3.枳实导滞丸(消食导滞,清热祛湿)(湿热食积证)
枳实导滞曲连芩,大黄术泽与茯苓, 食湿两滞生郁热,胸痞便秘效堪灵。
4.木香槟榔丸(行气导滞,攻积泻热)(痢疾,食积)
木香槟榔青陈皮,枳柏黄连莪术齐, 大黄牵牛加香附,热滞泻痢皆相宜。
健脾消食
1.健脾丸(健脾和胃,消食止泻)(脾虚食积证)
健脾参术苓草陈,肉蔻香连合砂仁, 楂肉山药曲麦炒,消补兼施不伤正。
2.葛花解醒汤(分消酒湿,理气健脾)(酒积伤脾证)
葛花解醒泽二苓,砂蔻青陈木香并, 姜曲参术温健脾,分消寒化酒湿灵。
散结
1.鳖甲煎丸 (行气活血,祛湿化痰,软坚散结)(胁下癥块<疟母>)
鳖甲煎丸疟母方,蟅虫鼠妇及蜣螂,蜂窠石韦人参射,桂朴紫葳丹芍姜, 瞿麦柴芩胶半夏,桃仁葶苈和硝黄,疟疾日久胁下硬,癥消积化保安康。
2.海藻玉壶汤 (化痰软坚,理气散结,滋阴泻火)(瘿瘤初起)
海藻玉壶带昆布,青陈半夏草贝母; 川芎独活当归翘,化痰散结瘿瘤除。
3.消瘰丸 (清润化痰,软坚散结)(痰火凝结之瘰疬痰核)
消瘰牡蛎贝玄参,消痰散结并滋阴, 肝肾素亏痰火结,临时加减细端寻。
驱虫剂
1.乌梅丸(温脏安蛔)(脏寒蛔厥证;久泻久痢)
乌梅丸用细辛桂,黄连黄柏及当归, 人参椒姜加附子,温肠清热又安蛔。
2.肥儿丸(杀虫消积,健脾清热)(虫积腹痛,消化不良)
肥儿丸内用使君,豆蔻香连曲麦槟; 猪胆为丸热水下,虫疳食积一扫清。
3.化虫丸 (杀肠中诸虫)(肠中诸虫)
化虫丸中用胡粉,鹤虱槟榔苦棟根, 少加枯矾面糊丸,专治虫病未虚人。
4.布袋丸 (驱蛔消疳,补养脾胃)(小儿虫疳)
参草苓术明砂荟,使君芜荑布袋丸。 小儿虫疳用此方,补养脾胃功效良。
5.伐木丸 (消积,燥湿,泻肝,杀虫)(黄肿病<多见于钩虫病>)
伐木方中有绿矾,苍术酒曲醋糊丸, 泻肝益脾消黄肿,钩虫为患效可观。
涌吐剂
瓜蒂散
瓜蒂散中赤小豆,豆豉汁调酸苦凑, 逐邪涌吐功最捷,胸脘痰食服之瘳。
涌吐痰涎宿食
痰涎、宿食雍滞胸脘证
痈疡剂
1.犀黄丸
犀黄丸内用麝香,乳香没药黄米饭, 乳岩横痃或瘰疬,正气未虚均可尝。
2.透脓散(《外科正宗》)
透脓散治毒成脓,芪归山甲皂刺芎, 程氏又加银蒡芷,更能速奏破溃功。
3.小金丹
小金丹用麝草乌,灵脂胶香与乳没, 木鳖地龙归墨炭,诸疮肿痛最宜服。