导图社区 Java基础汇总、Web框架、分布式架构、数据结构与算法及核心知识(分布式、大数据、微服务)
- 921
- 45
- 17
- 举报
Java基础汇总、Web框架、分布式架构、数据结构与算法及核心知识(分布式、大数据、微服务)
Java基础知识、J2EE知识、Java Web框架、Java多线程知识、Java核心思想、 RPC、分布式架构、微服务、大数据Hive、Mysql优化,分布式锁、负载均衡,数据结构与算法等,P7级别Java核心知识总结,超强汇总。
编辑于2022-05-27 16:06:38- 微服务
- 分布式



Java基础汇总、Web框架、分布式架构、数据结构与算法及核心知识(分布式、大数据、微服务)
社区模板帮助中心,点此进入>>
- 相似推荐
- 大纲










Java基础及核心知识框架
底层原理
JVM(Java虚拟机)
原理
工作方式
跨平台原理
平台无关性如何实现 compile once,run any where
编译时
javac 编译指令
Javap 反编译指令
Java源码首先被编译成字节码,再由不同的平台的JVM 进行解析,Java在不同平台上运行时不需要重新编译,Java虚拟机执行字节码的时候,把字节码转换成具体平台上的机器指令
JVM为什么不直接将源码转换为机器码去执行
准备工作:每次执行都需要进行各种检查
兼容性: 也可以将其他的语言解析成字节码
内存模型
内存模型图
线程独占
程序计数器
一块较小的内存空间, 是当前线程所执行的字节码的行号指示器(字节码指令、分支、循环、跳转、异常处理等信息)
每条线程都要有一个独立的程序计数器,这类内存也称为“线程私有”的内存。
Java虚拟机栈
线程私有的,方法在执行的时候会创建一个栈帧(stack frame)的数据结构
主要用于存放局部变量表、操作栈、动态链接、方法出口等
每个线程创建时,JVM都会为其创建对应虚拟机栈
栈内存划分的大小直接决定一个JVM进程可以创建多少线程
线程共享
MetaSpace
元空间(MetaSpace) 和 永久代(PermGen JDK7版本之前) 区别
元空间使用本地内存,永久代使用JVM内存
MetaSpace比较PermGen的优势
字符串常量池存在永久代种,容易出现性能问题和内存溢出
类和方法的大小难以确定,给永久代指定大小带来困难
永久代会给GC带来不必要的复杂性
方便HotSpot与其他JVM如Jrockit的集成
堆 (Heap)
对象实例的分配区域
堆和栈的区别(内存分配策略)
Java的内存分配策略
静态存储
编译时确定每个数据目标在运行时的空间需求
栈式存储
数据区需求在编译时未知,运行时模块入口前确定
堆式存储
编译时或运行模块入口前时都无法确定,动态分配
Java内存模型中堆和栈的区别
联系:引用对象,数组时,栈里定义的变量保存堆中目标的首地址

区别
管理方式
栈自动释放
堆需要GC
空间大小
栈比堆小
碎片相关
栈产生的碎片远小于堆
分配方式
栈支持静态分配和动态分配
堆仅支持动态分配
效率
栈的效率比堆高
方法区
jdk1.8前
永久代(PermGen)
本地内存
jdk1.8
元空间(Meta Space)
JVM类加载机制
类加载器
启动类加载器
扩展类加载器
应用程序加载器
双亲委派模型
类编译到执行的过程
编译器将.java源文件编译成.class字节码文件
ClassLoader 将.class字节码文件转换为JVM中的Class<?>对象
JVM利用Class<?>对象实例化为?对象
什么是ClassLoader
ClassLoader在Java中有着非常重要的作用, 主要工作在Class文件装载的阶段,其主要的工作原理是从系统外部获得Class二进制数据流。它是Java的核心组件,所有的Class文件都是通过ClassLoader进行加载的,ClassLoader负责将Class文件中的二进制数据流装载进系统,然后交给Java虚拟机进行连接,初始化等操作
ClassLoader 种类(四种)
BootstrapClassLoader
C++编写,加载核心库Java.*
ExtClassLoader
Java编写,加载扩展库javax.*
AppClassLoader
Java编写,加载程序所在目录
自定义ClassLoader
Java编写,定制化加载

OSGI(动态模型系统)
垃圾回收(GC)
GC类型
Minor GC/Young GC
Major GC/Full GC
Full GC 比 Major GC 慢,但是执行频率低
触发Full GC 条件
老年代空间不足
永久代的空间不足(JDK7之前)
CMS GC 出现promotion failed,concurrent mode failure
Minor GC 晋升到老年代的平均大小大于老年代的剩余空间
在程序中System.gc() 显示调用,提醒JVM回收年轻代和老年代
堆内存
年轻代(Young Generation)
对象被创建时,内存的分配首先发生在年轻代
对象在创建后很快就不再使用,大部分很快被年轻代GC清理掉
年老代(Old Generation)
大对象可以直接被创建在年老代
对象如果在年轻代存活了足够长时间而没有被清理,则被复制到老年代
老年代的空间一般比年轻代大,能存放更多的对象
当年老代内存不足时,将执行Full GC
永久代
指内存的永久保存区域,主要存放Class和Meta(元数据)的信息
Class在被加载的时候被放入永久区域,GC不会对永久代的区域进行清理
永久代的区域会随着加载的Class的增多而胀满,最终抛出OOM(Out of Memory)异常。
在Java8中,永久代已经被移除,被一个称为“元数据区”(元空间)的区域所取代。
元空间并不在虚拟机中,而是使用本地内存。
示意图
逻辑图
回收算法
标记-清除算法
先标记,后清除, 不移动对象 优点是 执行快 缺点是 会导致内存碎片化,当需要分配较大对象时,找不到足够大的连续内存,而触发另一次的GC
复制算法
分为对象面和空闲面
对象在对象面创建
清理后,存活的对象会从对象面 复制到 空闲面
将对象面的所有对象清除
适用于年轻代
优点: 1.解决碎片化问题 2.顺序分配内存,简单高效 3.适用于对象存活率低的场景
缺点
要分一块出来做复制
标记-整理算法
避免内存的不连续性
不用设置两块互换
适用于对象存活率较高的场景
适合老年代
分代收集算法
垃圾回收算法的组合拳
按照对象的生命周期不同,划分不同区域采用不同的垃圾回收算法
目的:提高JVM的回收效率
对象存活判断
引用计数法
可达性分析
GC Roots
虚拟机栈中本地变量表引用的对象
方法区中
类静态变量引用的对象
常量引用的对象
本地方法栈中JNI引用的对象
不可达还会发生什么
finalize()
年轻代-尽可能的快速地收集掉那些生命周期短的对象
内存空间划分 Eden区 两个 Survivor区
每次使用一个 Eden区 和一个 Survivor区
每次触发一次 minor GC,年龄就会加1
当年龄 默认到 15岁时对象会 进入 老年代
可以通过 -XX:MaxTenuringThreshold 调整 老年代年龄
如果创建的对象 比较大,Enden 或者Survivor 放不下,也会直接进入老年代
对象如何晋升老年代
经历一定的Minor 次数依然存活的对象
Survivor 放不下的对象
Enden区放不下时会直接出发一次 MinorGC,Eden区的对象会被清空
新生成的大对象 通过 -XX: +PretenuerSizeThreshold 控制 大对象大小
常用的调优参数
-XX: SurvivorRatio
Eden区 和 Surivor的比值, 默认 8:1
-XX:NewRatio
老年代和 年轻代 内存大小的比例
-XX:MaxTenuringThreshold
对象从年轻代晋升到老年代经过GC次数 的最大阈值
新生代垃圾收集器
Stop-the-World
JVM由于要执行GC而停止了程序的执行
任何GC算法中都会发生
多数GC优化通过减少Stop-the-World发生的时间来提高程序性能
Safepoint 安全点
分析过程中对象引用关系不会发生变化的点
产生Savepoint的地方:方法调用、跳出循环、异常跳转等
安全点选择得适中,选太少让GC等待时间太长,太多会增加运行程序负荷
JVM的运行模式
Server
重量级虚拟机,对程序做了更多的优化。 启动较慢,运行较快
Client
轻量级 启动较快,运行较慢
年轻代常见的垃圾收集器
垃圾收集器之间关系

垃圾收集器之间有连线表示可以搭配使用
Serial收集器 (-XX:UseSerialGC,复制算法)
单线程收集,进行垃圾收集时,必须暂停所有的工作线程
简单 高效,Client模式下默认的年轻代收集器
ParNew收集器 (-XX:+UseParNewGC,复制算法)
多线程收集,其余行为,和特点,和 Serial收集器一样
单核执行效率不如Serial,在多核下执行才有优势
Parallel Scavenge 收集器 (-XX:UseParallelGC,复制算法)
先了解 吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
比起关注用户线程停顿时间,更关注 系统的吞吐量
在多核下执行才有优势,Server模式下默认的年轻代收集器
自适应调节策略 (-XX:UseAdaptiveSizePolicy)
把内存调优任务交给虚拟机去完成
老年代垃圾收集器
Serial Old收集器 (-XX:UseSerialOldGC,标记-整理算法)
多线程,吞吐量优先
SMS收集器(-XX:+UseConcMarkSweepGC,标记-清除算法)
垃圾回收线程几乎可以和工作线程同时工作, 是几乎,不是完全,尽可能缩短了停顿时间
初始化标记:Stop-the-World
需要短暂的暂停
并发标记:并发追溯标记,程序不回停顿
并发预清理:查找执行并发标记阶段从年轻代晋升到老年代的对象
重新标记:暂停虚拟机,扫描CMS堆中剩余的对象
需要短暂的暂停
并发清理:垃圾回收线程与用户线程并发执行,清理已经标记的垃圾。
清理垃圾对象,程序不会停顿。
并发重置:重置CMS收集器的数据结构
CMS收集器执行流程
三色标记法
如果当前结点及其所有孩子结点都完成标记,那么当前结点为黑色;如果当前结点完成标记并且所有的孩子未全部完成标记,那么当前结点为灰色;未标记的结点为白色。
会产生错标或者误标的现象
cms采用的是Incremental Update 算法
G1采用SATB(snapshot-at-the-beginning)简称快照
G1(Garbage first)收集器(-XX:+UseG1GC,复制+标记-整理算法)
Garbage First 收集器的特点
并行和并发
分代收集
空间整合
可预测的停顿
将整个Java内存划分为多个大小相等的Region
年轻代和老年代不再物理隔离
非常精确控制停顿时间,在不牺牲吞吐量前提下,实现低停顿垃圾回收。
避免全区域垃圾收集,它把堆内存划分为大小固定的几个独立区域,跟踪这些区域的垃圾收集进度
基于标记-整理算法,不产生内存碎片。
#修改默认使用的垃圾回收器 export JAVA_OPTS='-XX:+UseG1GC'
JDK11新出的垃圾收集器 Epsilon GC
JDK11新出的垃圾收集器 ZGC
Java垃圾收集器-常考问题
Object 的 finalize()方法的作用是否与C++的析构函数作用相同
与C++的析构函数不同,析构函数的调用确定,而它的是不确定的。
将未被引用的对象放置于F-Queue 队列
方法执行随时可能被终止
给予独享最后一次的重生机会
Java中的强引用,软引用,弱引用,虚引用有什么作用
强引用(Strong Reference)
最普片的引用: Object = new Object()
当内存空间不足时,会抛出OutOfMemoryError 来终止程序,也不回回收具有强引用的对象
通过将对象设置为 null 来弱化引用,使其被回收
软引用 ( Soft Reference)
对象处于有用但非必须的状态
只有当内存空间不足时,GC会回收该引用的对象的内存
可以用来实现内存敏感的告诉缓存
String str = new String("abc");//强引用 SfotReferenct<String> softRef = new SoftReference<String>(Str);//软引用
弱引用(Weak Reference)
非必须的对象,比软引用更弱一些
GC 时会被回收
被回收的概率也不大,因为GC线程优先级比较低
适用于引用偶尔被使用且不影响垃圾收集的对象
String str = new String("abc");//强引用 WeakReferenct<String> weakRef = new WeakReference<String>(Str);//弱引用
虚引用 (PhantomReference)
不会决定对象的生命周期
任何时候都可能被垃圾收集器回收
跟踪对象被垃圾收集器回收的活动,起哨兵作用
必须和引用队列ReferenceQueue联合使用
String str = new String("abc"); ReferenceQueue queue = new ReferenceQueue(); PhantomReference ref = new PhantomReference(str,queue);

引用队列(ReferenceQueue)
无实际存储结构,存储逻辑依赖内部节点之间的关系来表达
存储关联的且被GC的软引用、弱引用以及虚引用
JVM锁
锁的分类
synchronized
Lock 接口的实现类
模块
JMM (Java Memory Mode)
内存交互八大操作
lock (锁定):作用于主内存的变量,把一个变量标识为线程独占状态
unlock (解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
read (读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
load (载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中
use (使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令
assign (赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中
store (存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用
write (写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
八大规则
1. 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
2. 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存 (可见)
3. 不允许一个线程将没有assign的数据从工作内存同步回主内存
4. 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量实施use、store操作之前,必须经过assign和load操作
5. 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
6. 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
7. 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
8. 对一个变量进行unlock操作之前,必须把此变量同步回主内存
Linux内核原理
linux体系结构
内核、shell、文件系统和应用程序。内核、shell和文件系统一起形成了基本的操作系统结构

linux 文件系统
linux shell
shell是系统的用户界面,提供了用户与内核进行交互操作的一种接口。它接收用户输入的命令并把它送入内核去执行,是一个命令解释器。另外,shell编程语言具有普通编程语言的很多特点,用这种编程语言编写的shell程序与其他应用程序具有同样的效果。
1.Bourne Shell:是贝尔实验室开发的。
2.BASH:是GNU的Bourne Again Shell,是GNU操作系统上默认的shell,大部分linux的发行套件使用的都是这种shell。
3.Korn Shell:是对Bourne SHell的发展,在大部分内容上与Bourne Shell兼容。
4.C Shell:是SUN公司Shell的BSD版本。
linux内核
Linux内核是世界上最大的开源项目之一,内核是与计算机硬件接口的易替换软件的最低级别。它负责将所有以“用户模式”运行的应用程序连接到物理硬件,并允许称为服务器的进程使用进程间通信(IPC)彼此获取信息。 内核是操作系统的核心,具有很多最基本功能,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。 Linux 内核由如下几部分组成:内存管理、进程管理、设备驱动程序、文件系统和网络管理

内存管理
进程管理
文件系统
设备驱动程序
网络接口(NET)
用户态和内核态
应用程序是无法直接访问硬件资源的,需要通过通过内核SCI 层提供的接口来访问硬件资源。

网络原理
网络协议
HTTP
HTTP请求与响应格式
请求类型
GET
如何发出get请求
浏览器地址栏直接请求
超链接发出的请求
form表单method="get"
get请求的特点
请求的参数直接拼接在url后面. 拼接格式是url?key=value&key=value
由于请求参数放在url后面,所有请求携带的数据量有限,一般不超过4kb
由于请求参数直接放在url后面,所有相对的不安全
POSH
何如发出posh请求
form表单method="post"
posh请求的特点
请求的参数放在 请求体中
由于请求的参数放在请求体中: 所以请求的数据量一般不受限制
由于请求的参数放在请求体中: 相对的安全
GET 和 POST 请求 的区别
Http报文层面
GET请求将请求信息放在URL,POST将请求内容放在报文体中
数据库层面
GET 请求符合幂等和安全性,POST 不符合
其他方面
GET可以被缓存,被存储,而POST 不可以
http请求
请求行
请求头
Allow
服务器支持哪些请求方法
Content-Length
请求体的字节长度
Content-Type
MIME类型
Content-Encoding
设置数据使用的编码类型
Expires
响应体的过期时间,一个GMT时间,表示该缓存的有效时间
请求体
http 响应的构成
响应行 request line 协议 状态码 状态信息 响应头 request header key:value 把服务端的信息 传递给客户端 如 响应的格式和编码 响应体 request body 携带响应的html 数据
HTTP重定向与转发
重定向(页面跳转)
什么是重定向
当浏览器第一次请求web服务器时,web服务器给浏览器返回一个302状态码和一个url地址.当浏览器收到302状态码和后面的地址时会立即对302后的地址再次发出请求 服务器再次做出响应的过程. 302+location
response.sendRedirect("地址")
特点
本质上是浏览器上的一个行为,有两次请求,两次响应 地址栏的地址会发生改变
两次请求的 request和 response对象都是新的
重定向技术 不但可以定位项目内请求 还可以定位到项目外的请求
转发(页面跳转)
什么是转发
当浏览器向web服务器的一个servlet发出请求时,这个servlet把未完成的工作交给下一个servlet处理的过程.
获取转发器
RequestDispatcher DS=request.getRequestDispatcher("转发到的地址")
转发
ds.forward(request,response)
特点
本质上是服务器上的一个行为,有一次请求,一次响应 地址栏的地址不会发生改变
共享 request和 response对象
转发只能在项目内进行
HTTP缓存与代理服务器
Cookie机制
Cookie 和Session 区别
Cookie 是 服务端 发给客户端的 特殊信息,以文本方式存放在客户端 客户端再次请求的时候,会把Cookie回发 服务器收到后,会解析Cookie 生成与客户端相对应的内容
Session 是服务器端的机制,在服务器上保存信息 解析客户端请求并操作Session id,按需保存状态信息
Session 存在 服务器上,Cookie存放在客户端上 Session比Cookie安全 若考虑减轻服务器压力,应当使用Cookie
数字签名与认证
签名与证书
HTTPS中,服务器利用私钥签名,然后浏览器用证书的公钥验证
证书需要到CA那边先验证一次,后续需用公钥来保护客户端生成的对称密钥
SSL数字证书
3个比较重要的属性:组织信息,公钥,有效时间
用X.509的格式记录公钥及组织等信息
OpenSSL
用于传输层安全性(TLS)和安全套接字层(SSL)协议的健壮的、商业级别的和功能齐全的工具包
也是一个通用密码库,用于证书的格式转换
认证步骤
1)服务器证书认证(浏览器上报对称密钥)
2)加密通信(不需要再用到证书了)
HTTPS与SSL/TLS
SSL/TLS
HTTPS采用了SSL/TLS技术
其核心是对称加密和非对称加密技术
TLS建立在SSL 3.0协议规范之上,是SSL 3.0的后续版本
SSL技术
一种确保C/S模式中通信安全的技术,依赖于数字证书技术
可以确保防篡改,加密通信,压缩通信
通信过程
1)客户端发送通信请求
SSL版本号, 加密参数, session会话标识ID
2)服务器回复响应
SSL版本号, 加密参数, session会话标识ID等信息 + 公钥证书
3)客户端利用CA的公钥验证server端的公钥证书,如果server端的证书不合法,就抛出异常并拒绝继续会话
4)客户端发送会话的对称密钥 session key 给server端
5)双方利用sessionkey 进行加密通信
加密方式
对称加密
加密和解密都使用同一个密钥
非对称加密
加密使用的密钥和解密使用的密钥是不同的
哈希算法
将任意长度的数据转化为固定长度的值,算法不可逆
数字签名
证明某个消息或者文件是某个人发出/认同的
HTTPS数据传输流程
浏览器将支持的加密算法信息发送给服务器
服务器选择一套浏览器支持的加密算法,以证书的方式回发给浏览器
浏览器验证证书的合法性,并结合证书公钥加密信息发送给服务器
服务器使用私钥解密信息,验证哈希,加密响应消息回发浏览器
浏览器解密响应消息,并对消息进行验真,之后进行加密交互数据
HTTP 和 HTTPS区别
HTTPS需要到CA申请证书,HTTP不需要
HTTPS密文传输,HTTP 明文传输
连接方式不同,HTTPS 默认使用的是443端口,HTTP 默认使用80端口
HTTPS= HTTP + 加密 + 认证 + 完整性保护,比较HTTP 安全
HTTPS 真的安全吗
浏览器默认填充 http://,请求需要跳转,有被劫持的风险
HSTS(HTTP Strict Transport Security)优化
TCP
TCP协议与流量控制
TCP/IP 模型包含了 TCP、IP、UDP、Telnet、FTP、SMTP 等上百个互为关联的协议
其中 TCP 和 IP 是最常用的两种底层协议
TCP协议可靠性如何保证
TCP和UDP区别
UDP简介
UDP报文结构
Source Port
Destination Port
Length
Check Sum

UDP 特点
面向非连接
不维护连接状态,支持向多个客户端发送相同的信息
数据报头很短,只有8个字节,额外开销小
吞吐量紧受限于数据生成速率,传输速率,以及机器性能
尽最大努力交付,但不保证可靠交付,不需要维持复杂的链接状态表
面向报文,不用对应用程序提交的报文进行拆分或者合并
TCP 和 UDP 区别
面向连接
TCP面向连接
UDP面向报文
可靠性
TCP通过三次挥手保证可靠性
UDP不保证数据可靠性
有序性
TCP有 sequence序列号保证数据传输的有序性
UDP 不保证
速度
TCP做了大量的工作保证 数据的可靠性有序性等,所以速度慢
UDP块
量级
TCP是重量级
UDP是轻量级
TCP的滑窗
RTT和 RTO
RTT
发送一个数据包到收到对方的ACK 所花费的时间
RTO
重传间隔
Socket(套接字)
与TCP、HTTP关系
TCP/IP协议用于传输流格式套接字,TCP 用来确保数据的正确性,IP用来控制数据如何从源头到达目的地
HTTP 协议就基于面向连接的套接字,因为必须要确保数据准确无误
底层实现原理
UNIX/Linux中的socket的返回值就是文件描述符,可使用普通的文件操作函数来传输数据
Windows 就把 socket 当做一个网络连接来对待,需要调用专门针对 socket 而设计的数据传输函数
种类
Internet套接字
Stream Sockets(流格式套接字)
含义
也叫“面向连接的套接字”,基于TCP协议
是一种可靠的、双向的通信数据流,数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送。
特征
数据传输过程中不会消失
数据是按照顺序传输的
数据的发送和接收不是同步的
流格式套接字的内部有一个缓冲区(也就是字符数组),socket 传输的数据将保存到缓冲区
接收端在收到数据后并不一定立即读取,接收端有可能在缓冲区被填满以后一次性地读取
传输
TCP套接字
缓冲区独立存在,在创建套接字时自动生成
关闭套接字也会继续传送输出缓冲区中遗留的数据
关闭套接字将丢失输入缓冲区中的数据
默认情况下是阻塞模式
Datagram Sockets(数据报格式套接字)
含义
也叫“无连接的套接字”,基于UDP协议
只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的
特征
强调快速传输而非传输顺序
传输的数据可能丢失也有可能损毁
限制每次传输的数据大小
数据的发送和接收是同步的
传输
使用IP协议作路由,使用 UDP 协议(User Datagram Protocol,用户数据报协议)传输数据
应用:QQ语音视频聊天、直播
比较
无连接套接字传输效率高,但是不可靠,有丢失数据包、捣乱数据的风险
有连接套接字非常可靠,万无一失,但是传输效率低,耗费资源多
Unix套接字(本地节点的路径名)
X.25 套接字(CCITT X.25地址)
数据传输过程
三次握手
使用 connect() 建立连接时,客户端和服务器端会相互发送三个数据包
四次握手
建立连接需要三次握手,断开连接需要四次握手
断开链接
优雅关闭请使用shutdown()
可能遇到的问题
数据粘包
高低位(大端和小端)
大端序(Big Endian):高位字节存放到低位地址(高位字节在前)
小端序(Little Endian):高位字节存放到高位地址(低位字节在前)
操作系统
分类
按实时性
分时操作系统
非实时
实时操作系统
软实时
能接受偶尔违反时间规定
硬实时
必需在绝对严格的规定事件内完成处理
其它
网络操作系统
分布式操作系统
个人计算机操作系统
windows、MaxOS、Linux、UNIX
类别
单片机
单片微型计算机(single-chip microcomputer),又称微控制器单元 MCU
中央处理器、存储器、定时/计数器、各种输入输出接口等都集成在一块集成电路芯片上的微型计算机
嵌入式系统(Embedded System)
一种嵌入机械或电气系统内部、具有专一功能和实时计算性能的计算机系统
常被用于高效控制许多常见设备,被嵌入的系统通常是包含数字硬件和机械部件的完整设备
嵌入式Linux
是一类嵌入式操作系统的概称,这类型的操作系统皆以Linux内核为基础,被设计来使用于嵌入式设备
与电脑端运行的linux系统本质上是一样的,主要利用 Linux 内核中的的任务调度、内存管理、硬件抽象等功能
RTOS(实时操作系统)
又称即时操作系统,它会按照排序运行、管理系统资源,并为开发应用程序提供一致的基础
编程框架
Spring全家桶
Spring Framework
特点
控制反转(IoC)
依赖注入(DI)
通过依赖注入和面向接口实现松耦合
面向切面(AOP)
基于切面和惯性进行声明式编程
通过切面和模板减少样板式代码
应用场景
权限认证
自动缓存
错误处理
调试
日志
事务
面向Bean(BOP)
基于POJO的轻量级和最小侵入性编程
从大小与开销两方面而言Sping都是轻量的,完整的Sping框架可以在一个大小只有 1M多
Spring所需的处理开销也是微不足道的
非侵入式的∶典型的,Spring应用中的对象不依赖于Spring的特定类
容器
高层视图
容器接口
BeanFactory
理解为就是个 HashMap,Key 是 BeanName,Value 是 Bean 实例
通常只提供注册(put),获取(get)这两个功能
支持单例模型及原型模型两种模型
ApplicationContext
“应用上下文”, 代表着整个大容器的所有功能
定义了一个 refresh 方法,用于刷新整个容器,即重新加载/刷新所有的 bean
框架
可以将简单的组件配置、组合成为复杂的应用
在Spring中,应用对象被声明式地组合,典型的是在一个XML文件里
提供了很多基础功能(事务管理、持久化框架集成等),将应用逻辑的开发留给开发者
常用模块
Spring Core
提供IOC容器对象的创建和处理依赖对象关系
核心
IOC
[Spring:源码解读Spring IOC原理](https://www.cnblogs.com/ITtangtang/p/3978349.html#a1)
常用注解
类级别注解
@Component
since 2.5
@Controller
since 2.5
@Service
since 2.5
@Repository
since 2.0
@Configuration
since 3.0
@ComponentsScan
since 3.1
@Bean
since 3.0
@Scope
@since 2.5
方法变量级别注解
@Autowire
@Qualifier
@Resource
@Value
@Cacheable
@since 3.1 - 当标记在一个方法上时表示该方法是支持缓存的 - 当标记在一个类上时则表示该类所有的方法都是支持缓存的 ``` @Cacheable(value="accountCache")// 使用了一个缓存名叫 accountCache public Account getUserAge(int id) { //这里不用写缓存的逻辑,直接按正常业务逻辑走即可, //缓存通过切面自动切入 int age=getUser(id); return age; } ```
@CacheEvict
@since 3.1 - 用来标记要清空缓存的方法,当这个方法被调用后,即会清空缓存。 - 参数列表 | 参数 | 解释 | 例子 | | ------ | ------ | ------ | | value | 名称 | @CachEvict(value={”c1”,”c2”} | | key | key | @CachEvict(value=”c1”,key=”#id”) | | condition | 缓存的条件,可以为空 | | allEntries | 是否清空所有缓存内容 | @CachEvict(value=”c1”,allEntries=true) | | beforeInvocation | 是否在方法执行前就清空 | @CachEvict(value=”c1”,beforeInvocation=true) |
三种注入方式
构造器注入
好处
官方解释; The Spring team generally advocates constructor injection as it enables one to implement application components as immutable objects and to ensure that required dependencies are not null. Furthermore constructor-injected components are always returned to client (calling) code in a fully initialized state.
保证依赖不可变(final关键字)
保证依赖不为空(省去了我们对其检查)
保证返回客户端(调用)的代码的时候是完全初始化的状态
避免了循环依赖
提升了代码的可复用性
接口注入
setter注入
AOP
定义: - 将那些与业务无关,却被业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。(通过预 编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能的一种技术) 实现: - 实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。 优秀博客 [Spring AOP 实现原理](https://blog.csdn.net/moreevan/article/details/11977115/)
实现原理
动态代理
JDK实现
需要实现至少一个接口
CGlib
ASM操作字节码实现生成目标类的子类
静态代理
编译时织入
类加载时织入
关键字
Join Point(连接点)
Poincut(切入点)
Advice(通知)
Before advice
执行在join point之前的advice,但是它不能阻止joint point的执行流程,除非抛出了一个异常(exception)。
After returning advice
执行在join point这个方法返回之后的advice。
After throwing advice
执行在join point抛出异常之后的advice。
After(finally) advice
执行在join point返回之后或者抛出异常之后的advice,通常用来释放所使用的资源。
Around advice
执行在join point这个方法执行之前与之后的advice。
Introduction
Target Object
AOP proxy
Aspect(切面)
Weaving
实现方式
注解
@AspectJ
@Pointcut
@Before
@After
@Around
配置文件
常见应用
事务
日志
权限
资源抽象
数据验证和转换
Spring表达式语言
核心容器
BeanFactory
BeanFactory 是 Spring 框架的基础设施,面向 Spring 本身
ApplicationContext 面向使用Spring 框架的开发者
BeanDefinitionRegistry 接口提供了向容器手工注册BeanDefinition 对象的方法
父子级联 IoC 容器的接口,子容器可以通过接口方法访问父容器
AutowireCapableBeanFactory 自动装配
SingletonBeanRegistry 运行期间注册单例 Bean
IOC控制反转实现的方式
XML配置方式
注解方式
自动装配方式
Spring Web模块
提供了对Struts、Springmvc的支持,支持WEB开发
SpringMVC
Servlet 3.0 的注解实现
ServletContainerInitializer 容器初始化
ServletRegistration注册
FilterRegisteration过滤器
ServletContext
性能实战
基于Servlet3.0异步
Callable异步
DeferredResult异步
Spring Web MVC
常用注解
类级别注解
@EnableWebMvc
since 3.1
@SessionAttributes
- 默认情况下Spring MVC将模型中的数据存储到request域中。当一个请求结束后,数据就失效了。如果要跨页面使用。那么需要使用到session。而@SessionAttributes注解就可以使得模型中的数据存储一份到session域中 - 参数: 1. names:这是一个字符串数组。里面应写需要存储到session中数据的名称。 2. types:根据指定参数的类型,将模型中对应类型的参数存储到session中 3. value:和names是一样的。 ``` @Controller @SessionAttributes(value={"names"},types={Integer.class}) public class ScopeService { @RequestMapping("/testSession") public String test(Map<String,Object> map){ map.put("names", Arrays.asList("a","b","c")); map.put("age", 12); return "hello"; } } ```
方法变量级别注解
@RequestBody
@ResponseBody
@RequestMapping
@GetMapping
spring 4.3新增
@PostMapping
spring 4.3新增
@PutMapping
spring 4.3新增
@DeleteMapping
spring 4.3新增
@PatchMapping
spring 4.3新增
@ModelAttribute
@RequestParam
@RequestHeader
@RestController
为一个组合注解,相当于@Controller和@ResponseBody的组合,注解在类上,意味着,该Controller的所有方法都默认加上了@ResponseBody。
@PathVariable
@ControllerAdvice
切面通知@ControllerAdvice(assignableTypes = xxx.class)
@CookieValue
@CrossOrigin
@Valid
校验参数
@Validated
校验参数
@ExceptionHandler
全局异常处理@ExceptionHandler(Throwable.class)
核心组件
DispatcherServlet
HandlerMapping
HandlerAdapter
ViewResolver
···
Spring Web Flux
Reactor基础
Lambda
Mono
Flux
核心
Web MVC注解
函数式声明
RouteFunction
异步非阻塞
使用场景
数据访问
事务处理
JDBC模板
测试
单元测试
集成测试
Spring Data
JPA
Redis
Mongodb
Couchbase
Cassandra
ElasticSearch
Neo4j
……
Spring Security
OAuth2.0
CAS
WEB安全
授权
身份验证
加密
……
Spring AOP
Spring提供面向切面的编程,可以给某一层提供事务管理,例如在Service层添加事物控制
Spring DAO
为JDBC DAO 抽象层提供了有意义的异常层次结构
Spring ORM
插入了多个ORM框架,包括 JDO、Hibernate和iBatis SQL Map
Spring JEE
J2EE开发规范的支持,包括企业服务,例 JNDl、EJB、电子部件、国际化、校验和调度功能
Spring上下文
是一个配置文件,向Spring 框架提供上下文信息
Spring Session
Spring Integration
Spring REST Docs
Spring AMQP
FanoutExchange(发布/订阅)
Exchange的类型
Fanout
广播,将消息交给所有绑定到交换机的队列
Direct
定向,把消息交给符合指定routing key 的队列
Topic
通配符,把消息交给符合routing pattern(路由模式) 的队列
Headers
通过headers 来决定把消息发给哪些queue(这个很少用)
Data Access
transactions
DAO support
JDBC
ORM
Marshalling XML
主要jar包
beans
Spring IOC的基础实现,包含访问配置文件、创建和管理bean等
context
在基础IOC功能上提供扩展服务,此外还提供许多企业级服务的支持
core
Spring的核心工具包 ,其他包依赖此包
expression
Spring表达式语言
Instrument
Spring对服务器的代理接口
orm
整合第三方的orm实现,如hibernate,ibatis,jdo以及spring 的jpa实现
Spring websocket
提供 Socket通信, web端的推送功能
Spring test
对JUNIT等测试框架的简单封装
常用注解
bean的注解
@Component 组件,没有明确的角色
@Service 在业务逻辑层使用(service层)
@Repository 在数据访问层使用(dao层)
@Controller 在展现层使用,控制器的声明(C)
Java配置类
@Configuration 声明当前类为配置类,相当于xml形式的Spring配置(类上)
@Bean 注解在方法上,声明当前方法的返回值为一个bean,替代xml中的方式(用在方法上)
@ComponentScan 用于对Component进行扫描,相当于xml中的(类上)
@WishlyConfiguration 为@Configuration与@ComponentScan的组合注解,可以替代这两个注解
切面(AOP)相关
@Aspect 声明一个切面(类上)
@After 在方法执行之后执行(方法上)
@Before 在方法执行之前执行(方法上)
@Around 在方法执行之前与之后执行(方法上)
@PointCut 声明切点
@Enable注解
@EnableAspectJAutoProxy
开启Spring对AspectJ代理的支持(类上)
@EnableAsync 开启异步方法的支持
@EnableScheduling 开启计划任务的支持
@EnableWebMvc 开启Web MVC的配置支持
@EnableConfigurationProperties 开启对@ConfigurationProperties注解配置Bean的支持
@EnableJpaRepositories 开启对SpringData JPA Repository的支持
@EnableTransactionManagement 开启注解式事务的支持
@EnableTransactionManagement 开启注解式事务的支持
@EnableCaching 开启注解式的缓存支持
Spring全景图
SpringBoot
[SpringBoot源码分析之---SpringBoot项目启动类SpringApplication浅析](https://www.yizhuxiaozhan.site/2018/09/06/SpringApplication-analyze/)
包含模块
单体应用
嵌入式容器
依赖管理
约定大于配置
环境管理
日志管理
配置管理
自动配置
管理功能
断点
打点
监控
开发者工具&CLI
常用注解
类级别注解
@SpringBootApplication
@RestController
@EnableAutoConfiguration
@EntityScan
方法变量级别注解
三大特性
组件自动装配
web MVC
支持的模板引擎
FreeMarker
Groovy
Thymeleaf
Mustache
JSP
不推荐 [官网给出一些已知的限制](https://docs.spring.io/spring-boot/docs/2.1.1.RELEASE/reference/htmlsingle/#boot-features-jsp-limitations)
web Flux
支持的模板引擎
FreeMarker
Thymeleaf
Mustache
JDBC
···
嵌入式Web容器(不需要部署War文件)
Tomcat
Jetty
Undertow
生产准备特性
提供固化的starter依赖,简化构建配置
提供运维特性
健康检查
指标信息
外部化配置
无代码生成,不需要XML配置
自动装配
实现方法
激活自动装配-@EnableAutoConfiguration/@SpringBootApplication
实现自动装配-XXXAutoConfiguration
配置自动装配实现-META-INFO/spring.factories
扩展点
SpringApplication
自动配置(Auto-Configuration)
诊断分析(Diagnostics Analyzer)
嵌入式容器(Embedded Container)
工厂加载机制(Factories Loadding Mechanism)
配置源(Property Sources)
端点(Endpoints)
监控和管理(JMX)
事件/监听器(Event/Listener)
SpringCloud
常用组件
Spring Cloud GateWay
服务网关
spring-cloud-starter-gateway
Route
Predicate
Filter
Spring Cloud Config
服务配置
Config Server
spring-cloud-config-server
@EnableConfigServer
Client
spring-cloud-starter-config
Spring Cloud Consul
服务注册/服务配置
Spring Cloud Stream
事件驱动
Source
Sink
Processor
Binders
spring-cloud-binder-rabbit
spring-cloud-binder-kafka
spring-cloud-binder-kafka-streams
( 函数及服务)Spring Cloud Function
Function
Consumer
Supplier
Applications
spring-cloud-function-web
spring-cloud-function-stream
Spring Cloud Security
服务安全
Spring Cloud Sleuth
服务调用链跟踪、可配合Zipkin进行可视化
client
spring-cloud-starter-sleuth
spring-cloud-starter-zipkin
Zipkin Server
io.zipkin.java.zipkin-server
@EnableZipkinServer
Spring Cloud OpenFeign
用于服务间的Restful调用(REST客户端)
spring-cloud-starter-openfegin
@EnableFeginClient
Spring Cloud Netflix
服务治理
Eureka服务发现
Client(Service)
spring-cloud-starter-netflix-eureka-client
@EnableEurekaClient
EurekaServer
spring-cloud-starter-netflix-eureka-server
@EnableEurekasServer
Hystrix 熔断器
Client
spring-cloud-starter-netflix-hystrix-client
@EnableCircuitBreaker
Turbine 聚合服务
spring-cloud-starter-netflix-turbine
@EnableTurbine
DashBoard 后台
spring-cloud-starter-netflix-hystrix-dashboard
@EnableHystrixDashboard
Zuul 网关服务
Spring-cloud-starter-netflix-zuul
@EnableZuulProxy > @EnableZuulServer
SideCar 边车服务
spring-cloud-starter-netflix-sidecar
@EnableSidecar
Ribbion 客户端负载均衡
spring-cloud-starter-netflix-ribbion
负载规则
随机规则
RandomRule
最可用规则
BestAvailableRule
轮训规则
RoundRobinRule
重试实现
RetryRule
客户端配置
ClientConfigEnabledRoundRobinRule
可用性过滤规则
AvailabilityFilteringRule
RT权重规则
WeightedResponseTimeRule
规避区域规则
ZoneAvoidanceRule
(任务框架)Spring Cloud Task
spring-cloud-starter-task
@EnableTask
( 消息总线)Spring Cloud Bus
spring-cloud-starter-bus-amqp
spring-cloud-starter-bus-kafka
Spring Cloud Circuit Breaker
服务容错
(管理台)Spring Cloud Admin
de.codecentric.spring-boot-admin-starter-server
@EnableAdminServer
Spring Cloud Data Flow
DashBoard
Application
Spring Cloud Stream App Starters
Spring Cloud Task App Starters
Server
Deployer
(微服务契约)Spring Cloud Contract
spring-cloud-starter-contract-verifier
spring-cloud-starter-contract-stub-runner
ORM框架
JDBC
数据库驱动类型
JDBC-ODBC桥接器
本机API Java驱动程序
JDBC网络纯Java驱动程序
本地协议纯Java驱动
MyBatis
定义
支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架
避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集
架构图
使用
[官网帮助文档](http://www.mybatis.org/mybatis-3/zh/index.html) **什么是Mybatis** MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
两种sql配置方式
XML配置方式
优点: - 跟接口分离、统一管理 - 复杂语句可以不影响接口的可读性 缺点: - 过多的xml文件
Annotation注解方式
优点: - 接口就能看到sql语句,可读性高,不需要再去找xml文件,方便 缺点: - 复杂的联合查询语句不好维护,代码可读性差
configuration 配置各个元素
properties
setting
typeAliases
typeHandlers
objectFactory
plugins
environments
databaseProvider
mapper
分页
pageHelper
批量操作
联合查询
可能遇到的坑
jdbcType与数据库字段类型的匹配
Hibernate(Nhibernate)
可以在 Java 的客户端程序使用
可以在 Servlet/JSP 的 Web 应用中使用
Hibernate 框架可以在应用 EJB 的 Jave EE 架构中取代 CMP
SpringData
Spring Data JDBC
Spring Data JPA
sql生成
通过方法名拼接sql
- 匹配正则:^(find|read|get|query|stream|count|exists|delete|remove)((\p{Lu}.*?))??By
查询
正则匹配:(find|read|get|query|stream)(Distinct)?(First|Top)(\d*)?(\p{Lu}.*?)??By
find
```javaList<User> findByName(String name);```
read
get
query
stream
First
```java List<User> findFirst10ByName(String name); ```
Top
```java List<User> findTop10ByName(String name); ```
count
exists
Distinct
```java List<User> findDistinctByName(String name) ```
OrderBy
删除
remove
delete
其他
IsBetween/Between
```java List<User> findByAgeBetween(Integer fromAge, Integer endAge); ```
IsNotNull/NotNull
IsNull/Null
IsLessThan/LessThan
IsLessThanEqual/LessThanEqual
IsGreaterThan/GreaterThan
IsGreaterThanEqual/GreaterThanEqual
IsBefore/Before
IsAfter/After
IsNotLike/NotLike
IsLike/Like
IsStartingWith/StartingWith/StartsWith
IsEndingWith/EndingWith/EndsWith
IsNotEmpty/NotEmpty
IsEmpty/Empty
IsNotContaining/NotContaining/NotContains
IsContaining/Containing/Contains
IsNotIn/NotIn
IsIn/In
IsNear/Near
IsWithin/Within
MatchesRegex/Matches/Regex
IsTrue/True
IsFalse/False
IsNot/Not
Is/Equals
@Query
JPQL
```java @Query(value = "select u from User u where u.name= :name") List<User> findUsersByName(@Param("name") String name); @Query(value = "select u from User u where u.name= ?1") List<User> findUsersByName(String name); ```
原生SQL
```java @Query(value = "select * from t_user where name = :name", nativeQuery = true) List<User> findAllByName(@Param("name") String name); @Query(value = "select * from t_user where name = ?1", nativeQuery = true) List<User> findAllByName(@Param("name") String name); ```
编程式
```java public class UserSpecs { public static Specification<User> listQuerySpec(UserQueryDto userQueryDto){ return (root, query, builder) -> { List<Predicate> predicates = new ArrayList<>(); Optional.ofNullable(userQueryDto.getId()).ifPresent(i -> predicates.add(builder.equal(root.get("id"), i))); Optional.ofNullable(userQueryDto.getUserName()).ifPresent(n -> predicates.add(builder.equal(root.get("userName"), n))); Optional.ofNullable(userQueryDto.getUserAge()).ifPresent(a -> predicates.add(builder.equal(root.get("userAge"), a))); Optional.ofNullable(userQueryDto.getOrgId()).ifPresent(oi -> predicates.add(builder.equal(root.get("orgId"), oi))); Optional.ofNullable(userQueryDto.getOrgName()).ifPresent(on -> { Join<User, Organization> userJoin = root.join(root.getModel().getSingularAttribute("org", Organization.class), JoinType.LEFT); predicates.add(builder.equal(userJoin.get("orgName"), on)); }); return builder.and(predicates.toArray(new Predicate[predicates.size()])); }; } } ``` ```java @Service public class UserService { @Autowired private UserRepository userRepository; public List<User> findUsersDynamic(UserQueryDto userQueryDto){ return userRepository.findAll(UserSpecs.listQuerySpec(userQueryDto)); } } ```
JPA自带常用API
JpaRepository<T, ID>
findAll
```java List<T> findAll(); List<T> findAll(Sort var1); <S extends T> List<S> findAll(Example<S> var1); <S extends T> List<S> findAll(Example<S> var1, Sort var2); ```
findAllById
```java List<T> findAllById(Iterable<ID> var1); ```
saveAll
```java <S extends T> S saveAndFlush(S var1); ```
saveAndFlush
```java void deleteAllInBatch(); ```
deleteInBatch
```java void deleteInBatch(Iterable<T> var1); ```
deleteAllInBatch
```java void deleteAllInBatch(); ```
getOne
```java T getOne(ID var1); ```
PagingAndSortingRepository<T, ID>
findAll
```java Iterable<T> findAll(Sort var1); Page<T> findAll(Pageable var1); ```
CrudRepository<T, ID>
save
```java <S extends T> S save(S var1); ```
saveAll
```java <S extends T> Iterable<S> saveAll(Iterable<S> var1); ```
findAll
```java Iterable<T> findAll(); ```
findById
```java Optional<T> findById(ID var1); ```
existsById
```java boolean existsById(ID var1); ```
count
```java long count(); ```
deleteById
```java void deleteById(ID var1); ```
delete
```java void delete(T var1); ```
deleteAll
```java void deleteAll(Iterable<? extends T> var1); void deleteAll(); ```
其他
flush
```java void flush(); ```
Spring Data Mongodb
Spring Data Redis
Spring Data Elasticsearch
Spring Data Apache Solr
Spring Data Apache Hadoop
其他
EclipseLink
iBATIS
MyBatis的前身
JFinal
Morphia
MongoDB的一个ORM框架
JavaWeb开发框架
网络框架
Netty
是一款用于高效开发网络应用的 NIO 网络框架
线程模型
架构图
与Tomcat区别
Netty 不仅支持 HTTP 协议,还支持 SSH、TLS/SSL 等多种应用层的协议
Tomcat 需要遵循 Servlet 规范,在 Servlet 3.0 之前采用的是同步阻塞模型
Netty 与 Tomcat 侧重点不同,不需要受到 Servlet 规范的约束,最大化发挥 NIO 特性
Mina
是 Apache Directory 服务器底层的 NIO 框架(Netty 是 Mina的升级版)
Grizzly
MVC框架
Struts
Struts2
JSF(Java Server Faces)
WebWork
Xwork1
WebWork2
框架组合
SSM框架
SpringMVC + Spring + Mybatis
web层(springmvc),service层(spring)和DAO层(mybatis)
SSMM框架
Spring + SpringMVC + Mybatis + MySQL
SSH框架
Structs + Spring + Hibernate
数据库连接池
C3P0
DBCP
druid
HikariCP
proxool
Tomcat jdbc pool
tomcat7.0引入
BoneCP
Tapestry
其它框架
缓存框架
Ehcache
[Ehcache官网](http://www.ehcache.org/)
提供了用内存,磁盘文件存储,以及分布式存储方式等
快速,简单,低消耗,依赖性小,扩展性强,支持对象或序列化缓存,支持缓存或元素的失效
结构图
每个CacheManager可以管理多个Cache,每个Cache可以采用hash的方式管理多个Element
Element:用于存放真正缓存内容
缓存策略
TTL
LRU
redis
caffeine
github地址:[caffeine](https://github.com/ben-manes/caffeine)
Infinispan
官网:[Infinispan](http://infinispan.org/)
日志处理
Log4j
sl4j
持久层框架
Hibernate
Hibernate对JDBC访问数据库的代码做了轻量级封装,大大简化了数据访问层繁琐的重复性代码
Mybatis
安全框架
Spring Security
Shiro
计算框架
Storm
[Storm:最火的流式处理框架](https://www.cnblogs.com/langtianya/p/5199529.html) [Storm 入门的Demo教程](https://www.cnblogs.com/xuwujing/p/8584684.html)
Nimbus
Supervisor
Worker
Executor
Task
Topology
Spout
Bolt
Tuple
Stream分组
Shuffle
Fields
All
Global
None
Direct
Local or shuffle
JStorm
[JStorm中文开发文档](https://github.com/alibaba/jstorm/wiki/JStorm-Chinese-Documentation)
Spark Streaming
[Spark 编程指南简体中文版](https://legacy.gitbook.com/book/aiyanbo/spark-programming-guide-zh-cn/details)
Flink
Blink
job框架(定时任务)
Quartz
[Quartz官网](http://www.quartz-scheduler.org/)
常用注解
@DisallowConcurrentExecution
禁止并发执行同一个 Job Definition(由 JobDetail 定义),但是可以同时执行多个不同的 JobDetail
组件
JobDetail
Trigger
SimpleTrigger
CronTrigger
Calendar
Schedule
ElasticJob
Spring-Task
校验框架
Hibernate validator
Oval
分布式架构
缓存
缓存级别
缓存技术
【服务器】分布式缓存
【CDN】动态缓存技术
CSI (Client Side Includes)
通过iframe、javascript、ajax等方式将另外一个页面的内容动态包含进来
页面依然可以静态化为html页面,在需要动态的地方则通过iframe,javascript或ajax来动态加载
相对比较简单,不需要服务器端做改变和配置
不利于搜索引擎优化(iframe方式), javascript兼容性问题,以及客户端缓存问题可能导致更新不及时
SSI(Server Side Includes)
通过注释行SSI命令加载不同模块,构建为html,实现整个网站的内容更新
通过SSI调用各模块的对应文件,最后组装为html页面,需要服务器模块支持
不受具体语言限制,比较通用,只需要Web服务器或应用服务器支持即可,Ngnix、Apache、IIS等
SSI只能在当前服务器上包含加载,不能够直接包含其他服务器上的文件(即不能跨域包含)
ESI(Edge Side Includes)
通过使用简单的标记语言来对那些可以加速和不能加速的网页中的内容片断进行描述
可用于缓存整个页面或页面片段,多在缓存服务器或代理服务器上执行
目前支持ESI的软件还比较少,官方更新也略显缓慢,因此使用不是很广
缓存算法(页面置换算法)
FIFO(First in First out)
先进先出
LFU(Least Frequently Used)
利用一个数组存储 数据项,用hashmap存储每个数据项在数组中对应的位置,然后为每个数据项设计一个访问频次,当数据项被命中时,访问频次自增,在淘汰的时候淘汰访问频次最少的数据
LRU
缓存的元素有一个时间戳,当缓存容量满了,又需要腾出地方来缓存新的元素时,现有缓存元素中时间戳离当前时间最远的元素将被清出缓存
使用场景
1)和数据库中的数据结构保持一致,原样缓存
2)列表排序分页场景的缓存
3)计数缓存
4)重构维度缓存
5)较大的详情内容数据缓存
缓存问题
缓存穿透,是指查询一个数据库一定不存在的数据
解决方案
对key的规范进行检测,拦截恶意攻击
从数据库查询的对象为空,也放入缓存,设定较短的缓存过期时间,比如设置为60秒
缓存雪崩,是指在某一个时间段,缓存集中过期失效
不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子
缓存击穿,是指一个key非常热点,大并发集中对这一个点进行访问
当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库
可让缓存永不过期
缓存解决方案实战
缓存的概念
SpringCache的用法
缓存的一致性策略
缓存雪崩方案
缓存穿透方案
三大矛盾
缓存实时性和一致性问题
实时策略
应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中
写入的过程,把数据存到数据库中,成功后,再让缓存失效
缓存的穿透问题
异步策略
读取
1)当读取的时候读不到的时候,不直接访问数据库,返回一个fallback数据
2)往消息队列里面放入一个数据加载的事件,异步读取数据库更新到缓存
更新
先更新数据库,然后异步更新缓存
先更新缓存,然后异步更新数据库
缓存对数据库高并发访问
定时策略
应用只访问缓存,不访问数据库
将一整块数据拆分成几部分进行缓存,而且区分更新频繁的和不频繁的
分布式存储
传统网络存储
NAS
提供了存储功能和文件系统的网络服务器
协议
SMB
NFS
AFS
SAN
只提供了块存储,而把文件系统交给客户端管理
协议
FibreChannel
iSCSI
ATA over Etherent(AoE)
HyperSCSI
对象存储
访问形式
通过REST网络服务对象访问
通过HTTP预定义的方法处理
GET
获取某个网络资源
PUT
创建或替换某个网络资源
POST
用于创建某个资源,如果已存在则报错
DELETE
删除某个网络资源
元数据服务
对象的散列值
对象存储将对象的散列值作为全局唯一标识符
使用高位数散列函数进行散列值的计算,确保内容不同的数据散列值不同
服务架构
ElasticSearch
断点续传
断点上传
高可用数据储存
MySQL高性能储存实战
Mycat进阶实战
FastDFS分布式文件储存实战
文件储存实战
文件同步实战
文件查询实战
分布式部署实战
分布式事务
隔离级别
默认使用数据库的隔离级别
mysql 默认可重复读
Oracle 默认已提交读(read commited)
ACID
Atomicity 原子性
原子性指的是一个事物是一个不可分割的工作单位,事物中的操作要么都发生,要么都不发生
Consistency 一致性
事物前后的数据的完整性必须保持一致
Isolation 隔离性
多个用户访问数据库时,数据库为每个用户开启的事物,不能被其他事物操作的数据所干扰,多个并发事物之间要相互隔离
Durability 持久性
一个事物一旦提交,它对数据库中的数据改变是永久性的,接下来就算是数据库有故障也不会对数据有任何影响
事务传播特性
保证同一个事务中 PROPAGATION_REQUIRED 支持当前事务,如果不存在 就新建一个(默认) PROPAGATION_SUPPORTS 支持当前事务,如果不存在,就不使用事务 PROPAGATION_MANDATORY 支持当前事务,如果不存在,抛出异常 保证没有在同一个事务中 PROPAGATION_REQUIRES_NEW 如果有事务存在,挂起当前事务,创建一个新的事务 PROPAGATION_NOT_SUPPORTED 以非事务方式运行,如果有事务存在,挂起当前事务 PROPAGATION_NEVER 以非事务方式运行,如果有事务存在,抛出异常 PROPAGATION_NESTED 如果当前事务存在,则嵌套事务执行
分布式事务框架
2PC
3PC
JOTM
JOTM(java open transaction manager)
Atomikos
分布式集群
横向扩展:从根本上(单机的硬件处理能力有限)提升数据库性能 。由此而生的相关技术:==读写分离、负载均衡==
主从复制
读写分离
负载均衡
分布式锁
分布式锁特点
互斥性
同时只有一个线程持有锁
可重入性
同一节点的同一线程获取锁后能再次获取锁
锁超时
和JUC包中的锁一样支持锁超时,防止死锁
高性能和高可用
加锁和解锁要保证高效,同时也要保证高可用,防止分布式锁失效
具备阻塞和非阻塞特性
能够及时从阻塞状态中被唤醒
分布式锁实现方式
基于数据库
自己查看实现
基于redis
基于zoolKeeper
自己查看实现
redis实现方式
加锁实现方式
利用setnx+expire命令 (错误的做法)
因为setnx + expire 操作不是原子的
public boolean tryLock(String key,String requset,int timeout) { Long result = jedis.setnx(key, requset); // result = 1时,设置成功,否则设置失败 if (result == 1L) { return jedis.expire(key, timeout) == 1L; } else { return false; } }
使用Lua脚本(包含setnx和expire两条指令)
public boolean tryLock_with_lua(String key, String UniqueId, int seconds) { String lua_scripts = "if redis.call('setnx',KEYS[1],ARGV[1]) == 1 then" + "redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end"; List<String> keys = new ArrayList<>(); List<String> values = new ArrayList<>(); keys.add(key); values.add(UniqueId); values.add(String.valueOf(seconds)); Object result = jedis.eval(lua_scripts, keys, values); //判断是否成功 return result.equals(1L); }
使用 set key value [EX seconds][PX milliseconds][NX|XX] 命令 (正确做法)
Redis在 2.6.12 版本开始,为 SET 命令增加一系列选项: SET key value[EX seconds][PX milliseconds][NX|XX] EX seconds: 设定过期时间,单位为秒 PX milliseconds: 设定过期时间,单位为毫秒 NX: 仅当key不存在时设置值 XX: 仅当key存在时设置值
public boolean tryLock_with_set(String key, String UniqueId, int seconds) { return "OK".equals(jedis.set(key, UniqueId, "NX", "EX", seconds)); }
value必须要具有唯一性,我们可以用UUID来做,设置随机字符串保证唯一性,至于为什么要保证唯一性?假如value不是随机字符串,而是一个固定值,那么就可能存在下面的问题: 1.客户端1获取锁成功 2.客户端1在某个操作上阻塞了太长时间 3.设置的key过期了,锁自动释放了 4.客户端2获取到了对应同一个资源的锁 5.客户端1从阻塞中恢复过来,因为value值一样,所以执行释放锁操作时就会释放掉客户端2持有的锁,这样就会造成问题
所以通常来说,在释放锁时,我们需要对value进行验证
使用 set key value [EX seconds][PX milliseconds][NX|XX] 命令看上去很ok,但在redis集群模式下,还是有可能出现问题的
客户端A在Master上拿到锁,此时 Master 还没有将key同步到slave节点,Master节点挂了,某个Slave被选举为Master,此时客户端再来获取锁同样会成功,会出现多个客户端都拿到锁的局面。
解锁实现方式
解锁我们需要验证value的值,不能直接粗暴的使用del key,因为这样任何一个客户端都可以解锁。所以解锁时,我们要校验value值是否是自己的,基于value值来判断。
public boolean releaseLock_with_lua(String key,String value) { String luaScript = "if redis.call('get',KEYS[1]) == ARGV[1] then " + "return redis.call('del',KEYS[1]) else return 0 end"; return jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(value)).equals(1L); }
redssion
redlock
实现原理
获取当前Unix时间,以毫秒为单位。
依次尝试从5个实例,使用相同的key和
具有唯一性的value (例如UUID)获取锁。当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个Redis实例请求获取锁。
客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。
当且仅当从大多数 (N/2+1,这里是3个节点) 的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功
如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在
所有的Redis实例上进行解锁 (即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。
使用方式
引入pom
<!-- https://mvnrepository.com/artifact/org.redisson/redisson --> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.3.2</version> </dependency>
获取锁
获取锁的代码为redLock.tryLock()或者redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS),两者的最终核心源码都是下面这段代码,只不过前者获取锁的默认租约时间(leaseTime)是LOCK_EXPIRATION_INTERVAL_SECONDS,即30s:
Config config = new Config(); config.useSentinelServers().addSentinelAddress("127.0.0.1:6369","127.0.0.1:6379", "127.0.0.1:6389") .setMasterName("masterName") .setPassword("password").setDatabase(0); RedissonClient redissonClient = Redisson.create(config); // 还可以getFairLock(), getReadWriteLock() RLock redLock = redissonClient.getLock("REDLOCK_KEY"); boolean isLock; try { isLock = redLock.tryLock(); // 500ms拿不到锁, 就认为获取锁失败。10000ms即10s是锁失效时间。 isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS); if (isLock) { //TODO if get lock success, do something; } } catch (Exception e) { } finally { // 无论如何, 最后都要解锁 redLock.unlock(); }
KEYS[1]就是Collections.singletonList(getName()),表示分布式锁的key,即REDLOCK_KEY; ARGV[1]就是internalLockLeaseTime,即锁的租约时间,默认30s; ARGV[2]就是getLockName(threadId),是获取锁时set的唯一值,即UUID+threadId:
唯一ID
实现分布式锁的一个非常重要的点就是set的value要具有唯一性,redisson的value是怎样保证value的唯一性呢?答案是UUID+threadId
protected final UUID id = UUID.randomUUID(); String getLockName(long threadId) { return id + ":" + threadId; }
解锁
释放锁的代码为redLock.unlock()
负载均衡
四层负载均衡vs 七层负载均衡
四层负载均衡(目标地址和端口交换)
F5:硬件负载均衡器,功能很好,但是成本很高。
Ivs:重量级的四层负载软件。
nginx:轻量级的四层负载软件,带缓存功能,正则表达式较灵活。
haproxy:模拟四层转发,较灵活。
七层负载均衡(内容交换)
haproxy:天生负载均衡技能,全面支持七层代理,会话保特,标记,路经转移:
nginx:只在http 协议和mail 协议上功能比较好,性能与haproxy 差不多:
apache:功能较差
Mysql proxy:功能尚可。
负载均衡算法/策略
轮循均衡 (Round Robin)
权重轮循均衡 (Weighted Round Robin)
随机均衡 (Random)
权重随机均衡 (Weighted Random)
响应速度均衡 (Response Time探测时间)
最少连接数均衡 (Least Connection)
处理能力均衡 (CPU、内存)
DNS响应均衡 (Flash DNS)
哈希算法
IP地址散列(保证客户端服务器对应关系稳定)
URL散列
LVS
LVS原理
LVS NAT 模式
①.客户端将请求发往前端的负载均衡器,请求报文源地址是 CIP(客户端 IP),后面统称为 CIP),目标地址为VIP(负载均衡器前端地址,后面统称为 VIP)。
②.负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将客户端请求报文的目标地址改为了后端服务器的 RIP 地址并将报文根据算法发送出去。
⑧.报文送到 Real Server 后,由于报文的目标地址是自己,所以会响应该请求,并将响应报文返还给 LVS。
④.然后 lvs 将此报文的源地址修改为本机并发送给客户端。
特点
1.NAT 技术将请求的报文和响应的报文都需要通过 LB 进行地址改写,因此网站访问量比较大的时候 LB负载均衡调度器有比较大的瓶颈,一般要求最多之能 10-20台节点
2.只需要在LB 上配置一个公网1P 地址就可以了。
3、每台内部的 realserver 服务器的网关地址必须是调度器 LB 的内网地址。
4、NAT 模式支持对IP 地址和端口进行转换。即用户请求的端口和真实服务器的端口可以不一致。
优点
集群中的物理服务器可以使用任何支持 TCP/IP 操作系统,只有负载均衡器需要一个合法的 IP 地址
缺点
扩展性有限。当服务器节点(普通 PC 服务器)增长过多时,负载均衡器将成为整个系统的瓶颈,因为所有的请求包和应答包的流向都经过负载均衡器。
当服务器节点过多时,大量的数据包都交汇在负载均衡器那,速度就会变慢!
LVS DR 模式(局域网改写mac地址)
①.客户端将请求发往前端的负载均衡器,请求报文源地址是 CIP,目标地址为VIP。
②.负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将客户端请求报文的源MAC 地址改为自己 DIP 的MAC地址,目标 MAC改为了 RIP的MAC地址,并将此包发送给 RS。
③.RS 发现请求报文中的目的 MAC 是自己,就会将次报文接收下来,处理完请求报文后,将响应报文通过 lo 接口送给 ethO 网卡直接发送给客户端。
特点
1.通过在调度器 LB 上修改数据包的目的 MAC 地址实现转发。注意源地址仍然是 CIP,目的地址仍然是 VIP 地址。
2、请求的报文经过调度器,而 RS响应处理后的报文无需经过调度器 LB,因此并发访问量大时使用效率很高(和 NAT 模式比)
3、因为 DR模式是通过 MAC 地址改写机制实现转发,因此所有 RS 节点和调度器 LB 只能在一个局域网里面
4、 RS 主机需要绑定 VIP 地址在 LO 接口(掩码32 位)上,并且需要配置 ARP抑制。
5、 RS 节点的默认网关不需要配置成 LB,而是直接配置为上级路由的网关,能让 RS 直接出网就可以。
优点
和 TUN(隧道模式)一样,负载均衡器也只是分发请求,应答包通过单独的路由方法返回给客户端。与VS-TUN 相比,VS-DR 这种实现方式不需要隧道结构,因此可以使用大多数操作系统做为物理服务器。
DR 模式的效率很高,但是配置稍微复杂一点,因此对于访问量不是特别大的公司可以用haproxy/nginx取代。日1000-2000W PV或者并发请求1万一下都可以考虑用haproxy/nginx。
缺点
所有 RS 节点和调度器 LB 只能在一个局域网里面
LVS TUN 模式(P封装、跨网段)
① 客户端将请求发往前端的负载均衡器,请求报文源地址是 CIP,目标地址为 VIP。
②.负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将在客户端请求报文的首部再封装一层IP 报文,将源地址改为 DIP,目标地址改为 RIP,并将此包发送给 RS。
③.RS 收到请求报文后,会首先拆开第一层封装,然后发现里面还有一层 IP 首部的目标地址是自己lo 接口上的VIP,所以会处理次请求报文,并将响应报文通过lo 接口送给 ethO 网卡直接发送给客户端。
特点
1.TUNNEL 模式必须在所有的 realserver 机器上面绑定 VIP 的IP 地址
2.TUNNEL 模式的 vip------>realserver 的包通信通过 TUNNEL模式,不管是内网和外网都能通信,所以不需要 /vs vip 跟 realserver 在同一个网段内。
3.TUNNEL 模式 realserver 会把 packet 直接发给 client 不会给 Ivs 了
4.TUNNEL 模式走的隧道模式,所以运维起来比较难,所以一般不用。
优点
负载均衡器只负责将请求包分发给后端节点服务器,而 RS 将应答包直接发给用户。
减少了负载均衡器的大量数据流动,负载均衡器不再是系统的瓶颈,就能处理很巨大的请求量,这种方式,一台负载均衡器能够为很多 RS进行分发。而且跑在公网上就能进行不同地域的分发。
缺点
隧道模式的 RS 节点需要合法 IP,这种方式需要所有的服务器支持〞 IP Tunneling" (IPEncapsulation)协议,服务器可能只局限在部分 Linux 系统上。
LVS FULLNAT模式
1.在包从 LVS 转到 RS 的过程中,源地址从客户端 1P 被替换成了 LVS 的内网IP。内网IP 之间可以通过多个交换机跨 VLAN 通信。目标地址从 VIP 修改为 RS IP.
2.当 RS 处理完接受到的包,处理完成后返回时,将目标地址修改为 LVS ip,原地址修改为 RSIP,最终将这个包返回给 LVS 的内网IP,这一步也不受限于 VLAN。
3.LVS 收到包后,在 NAT 模式修改源地址的基础上,再把RS 发来的包中的目标地址从 LVS 内网IP 改为客户端的1P,并将原地址修改为 VIP。
总结
1.FULL NAT 模式不需要 LBIP 和 realserver ip 在同一个网段;
2.full nat 因为要更新 sorce ip 所以性能正常比 nat 模式下降 10%
Keepalive
keepalive 起初是为 LVS 设计的,专门用来监控 lvs 各个服务节点的状态 ,后来加入了 vrrp 的功能,因此除了 lvs,也可以作为其他服务(nginx,haproxy)的高可用软件
VRRP 是 virtual router redundancy protocal(虚拟路由器冗余协议)的缩写。VRRP 的出现就是为了解决静态路由出现的单点故障,它能够保证网络可以不间断的稳定的运行。
Nginx反向代理负载均衡
upstream_module和健康检测
pproxy_pass请求转发
HAProxy
分布式协调和分流
Zookeeper分布式环境指挥官
zk的入门
zk开发基础
zookeeper应用实战
协议及算法分析
Nginx高并发分流进阶实战
nginx安装
正反向代理
nginx进程模型
核心配置结构
日志配置及签个
location规则
rewrite的使用
动静分离
跨域配置
缓存配置,Gzip配置
https配置
横向扩展带来的问题
LVS
keepalived
分布式一致性
Raft算法
特点
基于Quorum写入数据库
一半从库写入成功则意味着操作成功
主库写入日志,并向从库推送
三种日志:BinLog、RedoLog、UndoLog
基于日志比较的选举
判断谁的日志最新(依据其他节点的投票请求中的日志索引和自己的日志索引来确定)
角色分类
Leader
Candidate(Leader候选人)
Follower
消息种类
RequestVote
请求其他节点为自己投票(一般由Candidate发出)
AppendEntries
用于日志复制,表示日志增加的条目,当条目数为0时用于心跳
由Leader发出
分布式常见常见方案实战
事务概念
事务与锁
分布式事务产生背景
X/OpenDTP事务模型
标准分布式事务
分布式事务解决方案
两阶段提交
BASE理论与柔性事务
TCC方案
补偿性方案
异步确保与最大努力型
单点登陆方案
单点登陆的问题背景
页面跨域问题
Session跨域共享方案
Session的扩展
分布式任务调度方案
Quartz调度的用法
Elastic-Job示例
分布式调度的疑难点
Quartz集群定制化分布式调度
分布式框架及中间件
分布调用
RPC(远程调用)
Restful
中间件
缓存/持久化
分布式缓存
Redis(Remote Dictionary Server)
对象关系
结构图
内存分类
对象内存
缓冲内存
客户端缓冲
AOF缓冲区
复制积压缓冲区
主要用于主从同步。
自身内存
AOF/RDB 的时候 Redis 创建子进程内存的消耗
内存碎片
可选的分配器有 jemalloc、glibc、tcmalloc,默认 jemalloc
高内存碎片解决方法:数据对齐,安全重启(高可用/主从切换)
内存回收策略
惰性删除
不会主动删除过期的键值对,而是等待客户端读取键,如果已经超时则删除该键值对对象,然后返回空
定时任务删除
Pipeline(管道)
Redis 使用的是客户端-服务器(CS)模型和请求/响应协议的 TCP 服务器。这意味着通常情况下一个请求会遵循以下步骤:
客户端向服务端发送一个查询请求,并监听 Socket 返回,通常是以阻塞模式,等待服务端响应。
服务端处理命令,并将结果返回给客户端。
Redis 客户端与 Redis 服务器之间使用 TCP 协议进行连接,一个客户端可以通过一个 socket 连接发起多个请求命令。每个请求命令发出后 client 通常会阻塞并等待 redis 服务器处理,redis 处理完请求命令后会将结果通过响应报文返回给 client,因此当执行多条命令的时候都需要等待上一条命令执行完毕才能执行

而管道(pipeline)可以一次性发送多条命令并在执行完后一次性将结果返回,pipeline 通过减少客户端与 redis 的通信次数来实现降低往返延时时间,而且 Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。 Pipeline 的默认的同步的个数为53个,也就是说 arges 中累加到53条数据时会把数据提交。其过程如下图所示:client 可以将三个命令放到一个 tcp 报文一起发送,server 则可以将三条命令的处理结果放到一个 tcp 报文返回。

需要注意到是用 pipeline 方式打包命令发送,redis 必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。具体多少合适需要根据具体情况测试。
由于通信会有网络延迟,假如 client 和 server 之间的包传输时间需要0.125秒。那么上面的三个命令6个报文至少需要0.75秒才能完成。这样即使 redis 每秒能处理100个命令,而我们的 client 也只能一秒钟发出四个命令。这显然没有充分利用 redis 的处理能力。
适用场景
有些系统可能对可靠性要求很高,每次操作都需要立马知道这次操作是否成功,是否数据已经写进 redis 了,那这种场景就不适合。
还有的系统,可能是批量的将数据写入 redis,允许一定比例的写入失败,那么这种场景就可以使用了,比如10000条一下进入 redis,可能失败了2条无所谓,后期有补偿机制就行了,比如短信群发这种场景,如果一下群发10000条,按照第一种模式去实现,那这个请求过来,要很久才能给客户端响应,这个延迟就太长了,如果客户端请求设置了超时时间5秒,那肯定就抛出异常了,而且本身群发短信要求实时性也没那么高,这时候用 pipeline 最好了
管道(Pipelining) VS 脚本(Scripting)
大量 pipeline 应用场景可通过 Redis 脚本(Redis 版本 >= 2.6)得到更高效的处理,后者在服务器端执行大量工作。脚本的一大优势是可通过最小的延迟读写数据,让读、计算、写等操作变得非常快(pipeline 在这种情况下不能使用,因为客户端在写命令前需要读命令返回的结果)。
应用程序有时可能在 pipeline 中发送 EVAL 或 EVALSHA 命令。Redis 通过 SCRIPT LOAD 命令(保证 EVALSHA 成功被调用)明确支持这种情况。
Redis集群方案
twemproxy
redis集群(redis-cluster)
Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
结构特点
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。(hash环) 2的14次方
Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
redis cluster节点分配
现在我们是三个主节点分别是:A, B, C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式来分配16384个slot 的话,它们三个节点分别承担的slot 区间是
节点A覆盖0-5460;
节点B覆盖5461-10922;
节点C覆盖10923-16383.
获取数据
如果存入一个值,按照redis cluster哈希槽的算法: CRC16('key')384 = 6782。 那么就会把这个key 的存储分配到 B 上了。同样,当我连接(A,B,C)任何一个节点想获取'key'这个key时,也会这样的算法,然后内部跳转到B节点上获取数据
新增主节点
新增一个节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot到D上
节点A覆盖1365-5460
节点B覆盖6827-10922
节点C覆盖12288-16383
节点D覆盖0-1364,5461-6826,10923-12287
删除主节点
同样删除一个节点也是类似,移动完成后就可以删除这个节点了。
Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉
Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。
redis集群的搭建
集群中至少应该有奇数个节点,所以至少有三个节点,每个节点至少有一个备份节点
Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。
主从同步
数据可以从主服务器向任意从服务器上同步,从服务器可以是关联其他服务器的主服务器。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布 记录。同步对读取操作的可扩展性和数据冗余很有帮助。
工作原理
全量同步
redis 全量同步一般发生在slave 初始化阶段,这时需要将Master上的数据都复制一份
1.从服务器连接主服务器,发送SYNC命令;
2.主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3.主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4.从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5.主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6.从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;

完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
增量同步
redis增量同步指的是redis slave初始化完成后,开始正常工作时主服务器发生的写操作同步到从服务器的过程
增量复制 主要是 主服务器每接收一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行相同的写命令。
redis主从同步策略
主从开始链接时候,进行全量同步,同步结束后,进行增量同步
如果有需要,slave可以在任意时刻发起全量同步
redis策略是,先进行增量同步,同步失败在进行全量同步
注意点:当多个slave 断线了,需要重启,重启时会自动发送sync请求主服务器进行全量同步,当多个同时出现的时候,会导致 Master IO 剧增 宕机
Redis Sentinel(哨兵) 架构下高可用
当Master 挂掉后,需要人工将从节点晋升到主节点,同时通知业务方变更主节点地址,对于很对的应用场景这样的故障处理方式是不能接受的。redis 在2.8版本提供了 sentinel 架构解决了这个问题
实现原理
三个定时监控任务
每隔10s,每个 sentinel节点 会向 主节点 和从节点发送 info命令获取最新拓扑结构
每隔2s,每个sentinel 节点会Redis数据节点的_sentinel_:hello 频道 发送 当前sentinel节点 对主节点的判断以及当前sentinel节点的信息,同时每个sentinel节点也会订阅该频道,来了解其他sentinel节点以及它们对主节点的判断
每隔1秒,sentinel会向主节点,从节点发送一次ping 命令做一次心跳检测,来确认这些节点当前是否可达
主观下线
因为每隔一秒,每个Sentinel节点会向主节点、从节点、其余Sentinel节点发送一条ping命令做一次心跳检测,当这些节点超过down-after-milliseconds没有进行有效回复,Sentinel节点就会对该节点做失败判定,这个行为叫做主观下线。
客观下线
当Sentinel主观下线的节点是主节点时,该Sentinel节点会向其他Sentinel节点询问对主节点的判断,当超过<quorum>个数,那么意味着大部分的Sentinel节点都对这个主节点的下线做了同意的判定,于是该Sentinel节点认为主节点确实有问题,这时该Sentinel节点会做出客观下线的决定。
领导者sentinel节点选举
Raft算法假设s1(sentinel-1)最先完成客观下线,它会向其余Sentinel节点发送命令,请求成为领导者;收到命令的Sentinel节点如果没有同意过其他Sentinel节点的请求,那么就会同意s1的请求,否则拒绝;如果s1发现自己的票数已经大于等于某个值,那么它将成为领导者。
故障转移
1.领导者Sentinel节点在从节点中选出一个节点作为新的主节点
2.上述的选取方式是与主节点复制相似度最高的从节点
3.领导者Sentinel节点 让其他的从节点成为新主节点的从节点
4.Sentinel集合会将原来的主节点变为从节点,并对其保持关注,当其恢复后命令它去复制新的主节点
Redis Cluster(集群)下的高可用
实现原理
主观下线
集群中每个节点都会定期向其他节点发送ping消息,接受节点回复ping消息作为响应。如果在cluster-node-timeout时间内通信一直失败,则发送节点会认为接收节点存在故障,把接受节点标记为主观下线(pfail)状态。
客观下线
当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。
假设节点a标记节点b为主观下线,一段时间后节点a通过消息把节点b的状态发送到其他节点,当其他节点收到消息并解析出消息体中含有b的pfail状态,把节点b加入下线报告链表;
当某一节点c收到节点b的pfail状态时,此时有超过一半的槽主节点都标记了节点b为pfail状态时,则标记故障节点b为客观下线;
向集群广播一条pfail消息,通知集群内的所有节点标记故障节点b为客观下线状态并立刻生效,同时通知故障节点b的从节点触发故障转移流程。
故障恢复
资格检查
若从节点与主节点断线时间超过一定时间,则不具备资格
准备选举时间
当从节点符合故障转移资格后,要等待一段选举时间后才开始选举
在故障节点的所有从节点中,复制偏移量最大的那个从节点最先开始(与主节点的数据最一致)进行选举,然后是次大的节点开始选举.....剩下其余的从节点等待到它们的选举时间到达后再进行选举
发起选举
只有持有槽的主节点才具有一张唯一的选票,从从节点收集到N/2 + 1个持有槽的主节点投票时,从节点可以执行替换主节点操作
选举投票
替换主节点
当从节点收集到足够的选票之后,触发替换主节点操作
当前从节点取消复制变为主节点
撤销故障主节点负责的槽,并把这些槽委派给自己
向集群广播自己的pong消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息
异步队列
使用list作为队列
RPUSH作为生产者生产消息,LPOP作为消费者消费消息
缺点:没有等待队列,有值就直接消费 弥补:可以在应用层通过sleep机制去调用LOOP进行重试 如果不用sleep机制,可以使用BLPOP key[key..] timeout 阻塞直到队列有消息或者超时
一个生产者对应一个消费者
如何做到生产一次,能让多个消费者消费
pub/sub:主题订阅模式
发送者(pub)发送消息,订阅者(sub)接受消息
订阅者可以订阅任意数量的频道
缺点:消息无状态,无法保证可达
如何实现延时队列
使用sortset
拿时间戳作为score
消息内容作为key调用zadd生产消息
消费者使用zrangeBysocre指令获取N秒之前的数据轮询进行处理
Redis持久化
持久化方式RDB (redis database)
原理
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。

优势
1.一旦你采用这种方式,你的整个redis库只包含一个文件,这对于文件备份而言是十分完美的。比如你打算每小时同步一下24小时的数据,每天同步下30天数据。通过这样配置,遇到灾难性故障,我们很容易进行数据恢复。
2.对于灾难恢复而言,RDB是一个非常不错的选择,因为我们可以很轻松的将一个单独的文件压缩 再拷贝到其他存储介质上。
3.性能最大化,对于Redis服务进程而言,在开始持久化时,唯一要做的就是fork出一个子进程,其余交给子进程完成持久化操作,极大的避免服务进程进行IO操作
4.相比较AOF机制,如果数据集很大,那么RDB启动效率会更高
缺点
1.如果你想保证数据的高可用性,即最大程度避免数据丢失,RDB不是最好的选择,因为在系统在 特定持久化时间之前出现宕机,那么没来得及保存到磁盘上的数据将会丢失。
2.由于是fork子进程 来协助 进行磁盘持久化操作的,当数据集比较大时,可能会导致服务器停止服务几百毫秒,甚至1秒
配置
Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开6379.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
bgsave命令执行过程中,只有fork子进程时会阻塞服务器;而对于save命令,整个过程都会阻塞服务器;因此save已基本被废弃,线上环境要杜绝save的使用;
持久化方式AOF (append only file)
原理
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

优势
该机制可以带来更高的安全性,即数据的持久性
提供了三种同步策略
每秒同步
每秒同步也是 异步操作,效率非常高,如果出现服务宕机,那么只会丢失上一秒的数据。
每修改同步
可以理解为同步持久化,效率偏低
不同步
由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
缺点
对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
配置
在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
持久化方式混合模式
redis4.0开始支持该模式
为了解决的问题
redis在重启时通常是加载AOF文件,但加载速度慢 因为RDB数据不完整,所以加载AOF 开启方式: aof-use-rdb-preamble true 开启后,AOF在重写时会直接读取RDB中的内容
运行过程
通过bgrwriteaof完成,不同的是当开启混合持久化后, 1 子进程会把内存中的数据以RDB的方式写入aof中, 2 把重写缓冲区中的增量命令以AOF方式写入到文件 3 将含有RDB个数和AOF格数的AOF数据覆盖旧的AOF文件 新的AOF文件中,一部分数据来自RDB文件,一部分来自Redis运行过程时的增量数据
优点
混合持久化结合了RDB持久化 和 AOF 持久化的优点, 由于绝大部分都是RDB格式,加载速度快,同时结合AOF,增量的数据以AOF方式保存了,数据更少的丢失。
缺点
兼容性差,一旦开启了混合持久化,在4.0之前版本都不识别该aof文件,同时由于前部分是RDB格式,阅读性较差
持久化(双开)
只打算用Redis 做缓存,可以关闭持久化 打算使用Redis 的持久化。建议RDB和AOF都开启。其实RDB更适合做数据的备份,留一后手。AOF出问题了,还有RDB。
默认RDB指定的时间间隔内,执行指定次数的写操作,则将数据写入到磁盘中
适合大规模的数据恢复,数据一致性和完整性较差
AOF每秒将写操作日志追加到AOF文件中
AOF文件大,数据完整性比RDB高
与memcached比较
memcached所有的值均是简单的字符串,redis支持更为丰富的数据类型
redis的速度比memcached快且可以持久化数据
适用场景
会话缓存(Session Cache)
全页缓存(FPC)
队列
排行榜/计数器
发布/订阅
Redis和Memcache区别
Memcached 是一个高性能的分布式内存对象缓存系统
一个单一key-value内存Cache
用于动态Web应用以减轻数据库负载,可缓存图片、视频等
Redis则是一个数据结构内存数据库
支持数据持久化和数据恢复,允许单点故障
可以在服务器端直接对数据进行丰富的操作,减少网络IO次数和数据体积
Redis的Java客户端
Lettuce
springboot默认使用的客户端
基于Netty框架的事件驱动的通信层,其方法调用是异步的
线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器
Redisson
基于Netty实现,采用非阻塞IO,性能高
支持异步请求
支持连接池
不支持事务
支持读写分离,支持读负载均衡
可以与Spring Session集成,实现基于Redis的会话共享
Jedis
轻量,简洁,便于集成和改造
支持连接池
支持pipelining、事务、LUA Scripting、Redis Sentinel、Redis Cluste
不支持读写分离,需要自己实现
常见问题
redis 为什么是单线程的
因为Redis是基于内存的操作,CPU不是Redis的瓶颈
避免了不必要的上下文切换和竞争条件,也不存在多进程或多线程切换而消耗 CPU
使用多路I/O复用模型,非阻塞IO
Redis直接自己构建了VM 机制
如何保证Redis与数据库的一致性
更新的时候,先删除缓存,然后再更新数据库
读的时候,先读缓存;如果没有的话,就读数据库,同时将数据放入缓存,并返回响应
特别情况设置缓存失效时间
redis 怎么实现分布式锁
SET key value [EX seconds] [PX milliseconds] [NX|XX]
EX second :设置键的过期时间为second秒
NX :只在键不存在时,才对键进行设置操作
SET操作成功完成时,返回OK ,否则返回null
PX millisecond :设置键的过期时间为millisecond毫秒
XX:只在键已经存在时,才对键进行设置操作
仅在单实例的场景下是安全的
多个Client可能同时获取到了锁
异步获取,节点异常
Redis的内存优化
存储编码的优化
Redis存储的数据都使用redisObject结构体来封装
共享对象池
指Redis内部维护了[0-9999]的整数对象池,用于节约内存
除了整数值对象,其它类型如list、hash、set和zset内部元素也可以使用整数对象池
字符串优化
控制键的数量,使用hash代替多个key value
缩减键值对象,键值越短越好
Redis常见的性能问题
避免master写内存快照
master AOF持久化,AOF文件过大会影响master重启时的恢复速度
避免master调用BGREWRITEAOF重写AOF文件,出现短暂的服务暂停现象
redis主从复制的性能问题
为了主从复制的速度和连接的稳定性,slave和master最好在同一个局域网内
淘汰策略有哪些
volatile-lru:从设置了过期时间的数据集中
选择最近最久未使用的数据释放
allkeys-lru:从数据集中(包括设置过期时间以及未设置过期时间的数据集中)
选择最近最久未使用的数据释放
volatile-random:从设置了过期时间的数据集中
随机选择一个数据进行释放
allkeys-random:从数据集中(包括了设置过期时间以及未设置过期时间)
随机选择一个数据进行入释放
volatile-ttl:从设置了过期时间的数据集中
选择马上就要过期的数据进行释放操作
noeviction:不删除任意数据(但redis还会根据引用计数器进行释放)
这时如果内存不够时,会直接返回错误
如何从海量的key中查找某固定前缀的key
keys pattern 命令
会返回全部匹配的key
阻塞的,当查询大量的key 会对正在运行的服务造成影响,因为一次性返回数据量比较大的时候会使得服务变得卡顿
SCAN cursor [MATCH pttern] [Count count]命令
SCAN是无阻塞模式的提取指令列表,每次只会返回少量元素
cursor指的是游标,MATCH pattern值得是指令,count参数指定返回的数据个数,但是count并无法严格控制数量。
scan 0 match k1* count 10 //该命令指的是大概率的返回数量为count的且以k1开头的数据
此命令只有当以0作为游标的开始依次进行新的迭代,直至命令返回的游标为0为止,即当返回的游标为0的时候表示整个迭代过程都完成了。
SCAN增量式迭代命令,并不能保证每次执行都返回某个给定数量的元素,可能为0个,当时命令返回的游标不是零,则应用程序就会继续使用上一个游标进行迭代,直至游标值为0,对于较大的数据集每次可能返回数十个数据,对于较小的数据集可能会直接返回所有数据集。
SCAN命令查出的所有命令可能对存在重复的值,所以我们可以利用hashset来实现数据去重。
Memcached
结构图
分布式存储
MongoDB
FastDFS
Elasticsearch
全量缓存
Binlog
是 MySQL 及大部分主流数据库的主从数据同步方案
其他缓存框架/数据库
SSDB
RocksDB
消息队列(MQ)
[Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能](http://jm.taobao.org/2016/04/01/kafka-vs-rabbitmq-vs-rocketmq-message-send-performance/?utm_source=tuicool&utm_medium=referral) 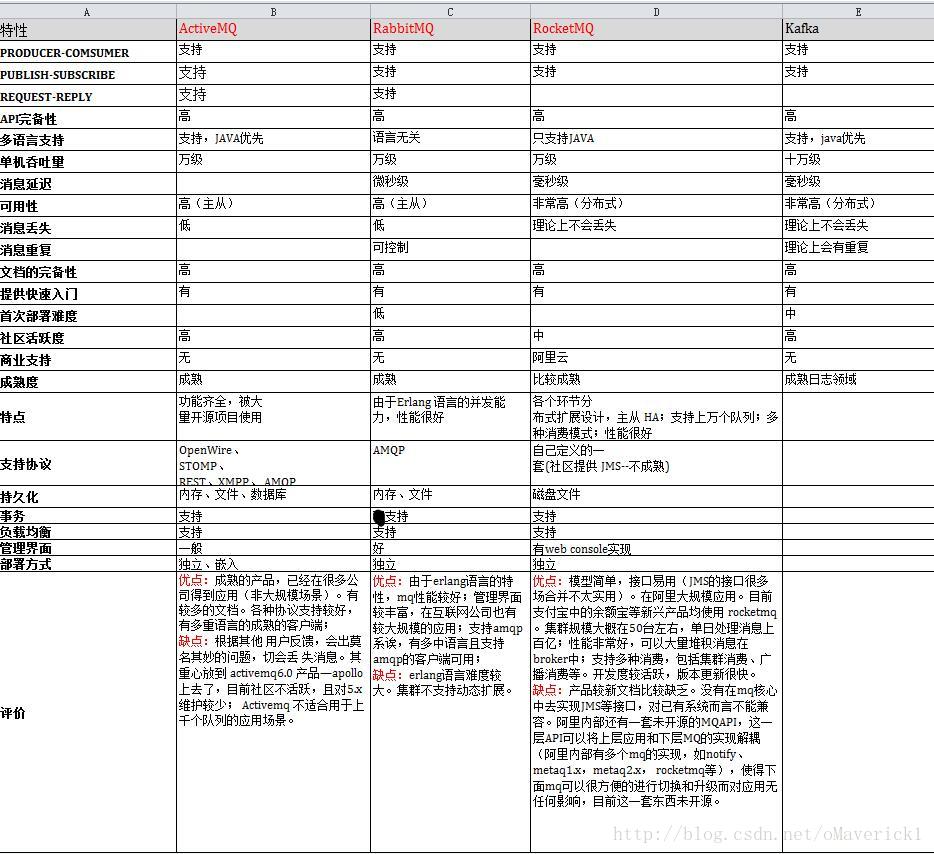
Kafka/Jafka
优点
时间复杂度O(1)
TPS高
缺点
不支持定时消息
Kafka Streams
ActiveMQ
RabbitMQ
优点
高并发(erlang语言实现特性导致)
高可靠、高可用
缺点
重量级
发布订阅模式
RabbitMQ的发布订阅模式
交换器(Exchange)
生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定
临时队列
queueDeclare()来创建一个非持久化、专有的、自动删除的、名字随机生成的队列
绑定(Binding)
RocketMQ
[十分钟入门RocketMQ](http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/)
java语言实现
组件
nameserver
broker
producer
consumer
两种消费模式
PULL
DefaultMQPullConsumer
PUSH
DefaultMQPushConsumer
优点
数据可靠性高
支持同步刷盘、异步实时刷盘、同步复制、异步复制
消息投递实时性
支持消息失败重试
高TPS
单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节
严格的消息顺序
支持定时消息
支持按照时间回溯消息
亿级消息堆积
缺点
消费过程要做到幂等(去重)
ZeroMQ
优点
TPS高
缺点
不支持持久化消息
可靠性、可用性较差
JMS
API
ConnectionFactory
Connection
Session
Destination
MessageProducer/consumer
消息组成
消息头
消息体
TextMessage
MapMessage
BytesMessage
StreamMessage
ObjectMessage
消息属性
JMS可靠机制
消息被确认才认为是被成功消费。消息的 消费包含三个阶段:客户端接收消息,客户端处理消息,消息被确认
事务性会话
消息在session.commit后自动提交
非事务性会话
应答模式
AUTO_ACKNOWLEDGE
自动确认
CLIENT_ACKNOWLEDGE
textMessage.acknowledge()确认消息
DUPS_OK_ACKNOWLEDGE
延迟确认
点对点(P2P模式)
发布订阅(Pub/Sub模式)
持久订阅
非持久订阅
数据库中间件
分库分表
ShardingSphere
架构图
SJDBC(sharding-jdbc)
Mycat
其它
Disque
[Disque 使用教程](http://disque.huangz.me/)
Cassandra
Neo4j
InfoGrid
分布式框架
Dubbo
Spring Cloud
Nacos
阿里开源分布式配置中心
Apollo
携程开源分布式配置中心 [Apollo github地址](https://github.com/ctripcorp/apollo)
Disconf
百度开源分布式配置中心
分布式架构
服务组件
注册中心
Zookeeper
[Zookeeper官网]()
数据模型
节点类型
持久化节点
持久化有序节点
临时节点
临时有序节点
命令
创建和删除节点有顺序,创建时需要先创建父节点,删除时反过来,需先删除子节点
创建节点
create [-s] [-e] path data acl
获取节点
get path [watch]
zookeeper提供了分布式数据发布/订阅,zookeeper允许客户端向服务器注册一个watcher监听。当服务器端的节点出发事件的时候会触发watcher。服务端会向客户端发送一个事件通知 `watcher的通知是一次性的,一旦触发一次后,watcher就失效`
列出节点
ls [path]
修改节点
set path data [version]
version实现乐观锁
删除节点
delete path [version]
适用场景
订阅发布/配置中心
watcher机制实现
实现配置信息的集中式管理和数据的动态更新
服务发现
分布式锁
临时有序节点及watcher机制实现
排他锁
临时节点实现
共享锁
临时有序节点实现
负载均衡
请求/数据分摊多个计算机单元上
ID生成器
分布式队列
统一命名服务
master选举
可以避免脑裂问题
限流
Euraka
consul
文件系统
NFS
FTP
Ceph
AWS S3
网格服务
Service Mesh
Service Mesh(服务网格)是一个基础设施层,让服务之间的通信更安全、快速和可靠。
Linkerd
[官网](https://linkerd.io/)
Istio
[官网](https://istio.io)
Envoy
被部署为`sidecar`
动态服务发现
负载均衡
轮询
随机
带权重的最少请求
TLS 终止
HTTP/2 & gRPC 代理
熔断器
健康检查、基于百分比流量拆分的灰度发布
故障注入
丰富的度量指标
Mixer
访问控制
使用策略
收集数据
Pilot
服务发现
弹性(超时、重试、熔断器等)流量管理
智能路由
Citadel
Galley
Envoy
nginmesh
工具类库
Apache Commons
Google Guava
lombok
字节码操作类库
ASM
Cglib
Javassist
官网:[Javassist](http://www.javassist.org/)
Byteman
官网:[Byteman](http://byteman.jboss.org/)
Byte Buddy
官网:[Byte Buddy](http://bytebuddy.net/#/)
bytecode-viewer
github地址:[bytecode-viewer](https://github.com/Konloch/bytecode-viewer)
json
FastJson
Gson
Jackson
Json-lib
其他框架
reactive框架
Vert.x
[官网](https://vertx.io/)
异步框架
Netty
Tiles
核心算法
一致算法
负载均衡算法
限流算法
分布式任务调度
分布式ID生成
分布式协调与同步
过滤算法
哈希算法
应用:文件校验、数字签名、鉴权协议
类型
MD5(信息-摘要算法5)
用于确保信息传输完整一致,输出固定长度128bits的算法
SHA-1
常用于HTTPS传输和软件签名
SHA-2
SHA-224/SHA-256/SHA-384/SHA-512并成为SHA-2
SHA-3
之前名为Keccak算法,是一个加密杂凑算法
问题与方法
构建高性能读服务
缓存中的数据经过筛选,有业务含义且会被查询的才进行存储
缓存中的数据可以进行压缩
Gzip、Snappy 等压缩算法
JSON序列化时字段用替代标识符替代
可以在字段上添加替代标识,表示在序列化后此字段的名称用替代标识进行表示
Redis 且使用了 Hash 结构存储数据,也可使用标识替代
异步并行化读取
构建高可用数据写服务
分库分表/数据分片
全局唯一标识
使用算法随机生成
基于数据库主键构建一个 ID 生成服务
分库中间件
Mycat
无状态存储,随时切库
按可用库的权重大小随机写入
数据写入随机存储成功后,主动将数据写入缓存中
兜底同步,扫库创建时间大于5秒(可配置)且未同步的数据
缓存降级
主动降级到数据库进行一次兜底查询,并将查询到的值存储至缓存中
消息队列
可以读取到缓存中异步写入数据库
高可用架构
缓存多机热备,避免缓存丢失等问题
利用应用内的前置缓存
负载均衡
HAProxy
Nginx
网络模型
epoll(多路复用IO)
降级保护
读写分离
动静流量分离
异构数据一致性如何保证
多线程与并发
基础原理
synchronized
线程安全问题诱因
存在共享数据(又称作离线资源)
存在多个线程共同操作这些共享数据
解决办法:同时只允许一个线程在操作共享资源,其他线程必须等待该线程处理完,才能操作共享资源
互斥锁的特性
互斥性
同一时间内只允许一个线程持有某个对象锁,通过这种特性来实现多线程的协调机制,这样在同一时间内只有一个线程对需要同步的代码块(复合操作)进行访问。互斥性也称为操作的原子性
可见性
必须确保在锁被释放之前,对共享变量所作的修改,对于随后要操作该变量的线程 时可见的,即在获得锁的时应获得最新共享变量的值,否则另一个线程肯呢个在本地缓存的某个副本继续操作,从而引起不一致
synchronized锁的不是代码,锁的时对象
获取对象锁的两种方法
同步代码块
同步代码块,synchronized(this),synchronized(实例对象),锁的时括号内的实例对象
同步非静态方法
synchronized method,锁的时当前实例对象
根据获取锁的分类
获取对象锁
同步代码块
synchronized(this),synchronized(类实例对象),锁的是()中的实例对象
同步非静态方法
synchronized method 锁的是当前对象的实例
获取类锁
同步代码块 synchronized(类.class),锁的是小括号内的 Class对象
同步静态方法 synchronized static method 锁的是当前类对象(Class对象)
synchronized 底层实现原理
对象在内存中的布局
对象头
Mark World
默认存储对象的hashCode,分代年龄。锁类型,锁标志位等信息
锁状态
无锁状态
轻量级锁
重量级锁
GC标记
偏向锁
Class Metadata Address
类型指针指向对象的类元数据,JVM通过该指针确定对象是 哪个类的数据
实例数据
对齐填充
什么是重入
从互斥锁的设计上来说,当一个线程试图进入另一个线程持有的对象锁的临界资源是,将会处于阻塞状态。当一个线程再次请求自己持有的对象锁的临界资源是时,这种情况属于重入
为什么会对synchronized 嗤之以鼻
早期版本中,synchronized 属于重量级锁,依赖Mutex Lock实现
线程之间切换需要从用户态转换到内核态,开销较大
Java6 之后 synchronized 性能有较大的提升
自旋锁
自旋锁
许多情况下,共享数据的锁定状态持续时间较短,切换线程不值得
通过让线程执行忙循环等待锁的释放,不让出CPU
缺点:若锁被其他线程长时间占用,会带来许多性能上的开销
自适应自旋锁
自旋时间不再固定
由前一次在同一个锁上面自旋时间 和锁的拥有者的状态来定
锁消除
更彻底的优化
JIT编译时,会进行上下文扫描,去除不可能存在竞争的锁
锁粗化
通过扩大锁的范围,避免反复的加锁和解锁
synchronized锁四种状态
无锁
偏向锁
减少同一线程获取锁的代价。大多数情况下,锁资源不存在多线程竞争,总是由同一线程多次获得和
核心思想:如果一个线程获得了锁,那么锁就进入偏向模式,此时的Mark Word的结构就变成了偏向结构。当该线程再次请求锁时,无需在做任何同步动作,即获取锁的过程只需检查Mark Word 锁的标记位时 偏向锁,以及当前线程的Id 等于 mark word 的ThreadID 即可,这样可以省去大量有关于锁的申请操作
轻量级锁
轻量级锁由偏向锁升级而来。当第二个线程加入锁竞争的时候,偏向锁就会升级为轻量级锁
适应场景:线程交替执行同步代码块 若存在同一时间访问同一锁情况,则会膨胀为重量级锁
重量级锁
synchronized 和 ReenTrantLock 区别
Reentrant:Lock (再入锁) 介绍
位于 j.U.C 包下
和 CountDownLatch、FutureTask、Semaphore 一样基于AQS实现
能够实现比synchronized更细颗粒度的控制,如控制 fairness
调用lock()后,必须调用unlock()解锁
性能未必比synchronized高,并且也是可重入的
ReentrantLock公平性的设置
创建公平锁例子 ReentrantLock fairLock = new ReetrantLock(true);
参数为true 时,倾向于将锁赋予等待时间最久的线程
公平锁
获取锁的顺序按先后调用lock方法的顺序(慎用)
非公平锁
抢占的顺序不一定,看运气
公平锁 和非公平锁
synchronized是非公平锁
ReentrantLock 将锁对象化
判断是否有线程,或者某个特定线程,在排队等待获取锁
带超时的获取锁的尝试
感知有没有成功获取锁
能否将wait/notify/notifyAll对象化
java.util.concurrent.locks.Condition
ArrayBlockingQueue 底层数组实现的 线程安全的,有界的 阻塞队列
总结
synchronized是关键字,ReentrantLock是类
ReentrantLock可以对获取锁的等待时间进行设置,避免死锁
ReentrantLock可以获取各种锁的信息
ReentrantLock可以灵活的实现多路通知
机制: sync 操作的是对象头的 Mark Word,lock 调用 Unsafe类的park()方法
jmm内存可见性
什么是Java 内存模型中的 happen-before
Java 的 内存 模型 JMM
Java的内存模型(Java Memory Model,简称JMM)本身是一种抽象的概念,并不真实存在,它描述的是一组规则或者规范,通过对这组规范定义了程序的各个变量(包括实例字段,静态字段 和构成数组对象的元素)的访问方式。

JMM中的主内存
存储Java实例对象
包括成员变量、类信息、常亮、、静态变量等
属于数据共享的区域,多线程并发操作时会引发线程安全问题
JMM的工作内存
存储当前方法的所有的本地变量信息,本地变量对其他线程不可见
字节码行号指示器、Native方法信息
属于线程私有数据区域,不存在线程安全问题
JMM和Java内存区域划分是不同的概念层次
JMM描述的是一组规则,围绕原子性,有序性,可见性展开
相似点:存在共享区域和私有区域
主内存与工作内存的数据存储类型以及操作方式归纳
方法里的基本数据类型本地变量将直接存储在工作内存的栈帧结构中
引用类型的本地变量:引用存储在工作内存中,实例存储在主内存中
成员变量、static变量、类信息均会被存储在主内存中
主内存共享的方式是 线程各拷贝一份数据到工作内存,操作完成后刷新回主内存
JMM 如何解决 内存可见性问题

指令重排序 需要满足的条件
单线程环境下不能改变运行的结果
存在数据依赖关系的不允许进行重排序
即无法通过happens-before 原则推导出来的,才能进行指令的重排序
A 操作的记过需要对B操作课件,则A和B存在happens-before关系
happen-before 原则
判断数据是否存在竞争、判断线程是否安全的主要依据
程序次序规则
一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
锁定规则
一个unLock操作先行发生于后面对同一个锁的lock操作
volatile 变量规则
对一个变量的写操作先行发生于后面对这个变量的读操作
传递规则
如果操作A先行发生于操作B,而操作B又先行发生于C,则可以得出 操作A先行发生于C
线程启动规则
Thread对象的start()方法先行发生于此线程的每一个动作
线程终端规则
对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
线程终结规则
线程中所有的操作都先行发生于线程的终止检测,我们可以通过 Thread.join()方法结束、Thread.isAlive()的返回值手段检测线程已终止执行
对象终结规则
一个对象的初始化完成先行发生于它的finalize()方法的开始
如果两个操作不满足上述的任意一个happens-before规则,那么这两个操作就没有顺序的保障,JVM可以对这两个操作进行重排序;
如果操作A happens-before 操作B,那么操作A在内存上所做的操作对操作B都是可见的。
volatile
JVM提供的轻量级同步机制
保证被volatile修饰的共享变量对所有的线程总是可见的
禁止指令的重排序优化
volatile在多线程情况下,并不能保证安全性

线程不安全

线程安全

线程安全
volatile变量和为何立即可见
当写一个volatile变量时,JMM会把该线程对应的工作内存中的共享变量值刷新到主内存中
当读取一个volatile 变量时,JMM 会把该线程对应的工作内存置为无效
volatile 如禁止重排优化
内存屏障 (Memory Barrier)
保证特定操作的执行顺序
保证某些变量的内存可见性
通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化
强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本
单例的双重检测实现

使用 volatile 禁止重排优化
volatile 和synchronized 区别
volatile 本质是告诉JVM当前变量在寄存器(工作内存)中的值不确定的,需要从主存中读取;synchronized 则是锁定当前变量,只有当前的线程可以访问该变量,其他线程被阻塞知道该线程完成变量操作为止
volatile仅能作用在变量级别,synchronized可以使用在变量、方法、类级别
volatile仅能实现变量的修改可见性,不能保证原子性,而synchronized 则可以保证变量修改的可见性和原子性
volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞
volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
CAS无锁技术 (Compare and Swap)
synchronized 是悲观锁,CAS是乐观锁设计
一种高效实现线程安全性的方法
支持原子更新操作,适用于计数器,序列发生器等场景
属于乐观锁机制,号称lock-free
感知上是,实际底层还是有加锁行为
CAS操作失败由开发者决定是否继续尝试,还是执行别的操作
所以不会被 阻塞挂起
CAS思想
包含三个操作数
内存位置(V)
预期原值(A)
新值(B)
执行CAS操作时,会将内存位置的值和预期原值进行比较,如果相等,处理器会自动的将该位置的值设置为新值,否则处理器不做任何处理。内存位置的值 即主内存的值
CAS多数情况下对开发者是透明的
J.U.C 的atomic包提供了常用的原子性数据类型以及引用、数组等相关原子类型 和更新操作工具,是很多线程安全程序的首选
Unsafe类虽然提供CAS服务,但因能够任意操纵内存地址读写而有隐患,所以不要轻易去手动实现
非得需要调用Unsafe,Java9以后,提供了Variable Handke API来替代Unsafe
CAS缺点
弱循环时间长,则开销很大
只能保证一个共享变量的原子操作
ABA问题
一个变量值为A,期间被另外一个线程改为了B,又被改回了A,此时会被CAS操作认为这个值没有被改变不过
解决方案: 提供了 AtomicStampedeReference 控制变量的版本解决CAS 的ABA问题
进程
多进程
特点
内存隔离,单个进程的异常不会导致整个应用的崩溃,方便调试
进程间调用、通信和切换的开销大
常使用在目标子功能间交互少的场景,弱相关性的、可扩展到多机分布(Nginx负载均衡)的场景
进程的分类
守护进程
Daemon Thread(守护线程)
为其他线程的运行提供服务
GC线程
非守护进程
User Thread(用户线程)
创建进程的方式
使用Runtime的exec(String cmdarray[])方法,在虚拟机实例中创建
任何进程只会运行在一个虚拟机实例当中(底层源码采用 单例模式)
使用ProcessBuilder的start()方法创建操作系统进程
进程和线程的区别
程序是一组指令的有序集合,它本身没有任何运行的含义,它只是一个静态的实体。而进程可以请求资源和调度,是一个动态的概念。 进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。 程序是指令、数据及其组织形式的描述,进程是程序的实体,一个程序可能有多个进程。 线程有时被称为轻量级进程,是程序执行流的最小单元。线程是程序中一个单一的顺序控制流程。进程内一个相对独立、可调度的执行单元,是系统独立调度和分派CPU的基本单位,也指运行中的程序的调度单位。 整个outlook应用程序代码是一个程序;打开一个outlook是一个进程,打开一个word是另一个进程;而发邮件是outlook进程的一个线程,收邮件又是另一个线程。
Process/进程
是程序的实体
程序是指令、数据及其组织形式的描述
是计算机中的程序关于某数据集合上的一次运行活动
是系统进行资源分配和调度的基本单位
是操作系统结构的基础
是线程的容器
进程的特点
独立性
动态性
并发性
通过进程调起计算机、文本编辑器等
线程
是依附于进程而存在的,每一个线程必须有父进程
线程拥有自己的堆栈、程序计数器和局部变量,线程和其他线程共享进程的系统资源
进程不能共享内存,而线程之间可以轻松地共享内存
线程基础
线程父子关系
一个线程的创建肯定是由另外一个线程完成的
被创建的线程的父线程是创建它的线程
创建线程
实现Runnable接口run方法
重写Thread类的run方法
守护线程
线程join
interrupt 中断函数
1.调用 interrupt() ,通知线程应该中断了
如果线程处于阻塞状态,则会立即退出被阻塞状态,并且抛出一个InterruptedException
目前使用方法
需要被调用的线程配合中断
正常执行任务时,需要经常检查本线程的中断标志位,如果被设置了中断标志就自行停止线程
如果处于正常活动的状态,那么将线程的中断标志位设置位true,被设置的线程将正常运行,不受影响
Thread 和 Runable 区别
Runable是接口
Thread是类 实现了Runable 接口
因为类的单一继承原则,推荐使用Runnable接口
sleep和wait区别
sleep()
Thread.sleep()
sleep方法 可以在任何地方被使用
sleep只会让出CPU,不会导致锁行为改变
wait()
Object.wait()
wait只能在synchronized方法 或者 synchronized代码块中使用
不仅让出CPU,还会释放当前已经占有的同步资源锁
notify 和notifyAll区别
锁池和等待池
锁池
假设线程A已经拥有了某个对象(不是)的锁,,而其他线程B、C想调用这个对象synchronized方法或者 synchronized 代码块,由于B、C线程 进入对象synchronized方法(或者代码块)时必须要持有该对象锁的拥有权,此时锁被A持有,那么B、C线程会被阻塞,进入一个地方去等待锁的释放,这个地方便是对象的锁池
等待吃
假设线程A调用了某个对象的wait()方法,线程A会释放该对象的锁,此时A会进入该对象的等待池中,进入到等待池的线程,不会去竞争该对象的锁
notify
会随机选择等待池中的 某一线程,进入锁池中 去竞争获取锁的机会
notifyAll
notifyAll会让所有等待池中的线程 进入 锁池中 去竞争获取锁的机会
yield 出让函数
当调用Thread.yield()函数时,会给线程调度器一个暗示,表示当前线程愿意让出CPU,但是线程调度器可能会忽略这个暗示
线程的状态
new 新建
创建后尚未启动的线程状态
进入方式:new 之后,start 之前
runnable 可运行
Running/Ready
Running:线程调度程序从可运行池中选择一个线程作为当前线程时线程所处的状态
线程调度程序从可运行池中选择一个线程作为当前线程时线程所处的状态。这也是线程进入运行状态的唯一一种方式。
线程调度程序从可运行池中选择一个线程作为当前线程时线程所处的状态。
1.就绪状态只是说你资格运行,调度程序没有挑选到你,你就永远是就绪状态。 2.调用线程的start()方法,此线程进入就绪状态。 3.当前线程sleep()方法结束,其他线程join()结束,等待用户输入完毕,某个线程拿到对象锁,这些线程也将进入就绪状态。 4.当前线程时间片用完了,调用当前线程的yield()方法,当前线程进入就绪状态。 5.当线程时间片用完了,调用当前线程的yeid()方法,当前线程会进入就绪状态 6.锁池里线程拿到对象锁后,进入就绪状态
blocked 阻塞
等待获取排他锁
waiting 无限等待
不会被分配CPU执行时间 ,需要被显示的唤醒
Timed Waiting 限期等待
过一段时间后会由系统自动唤醒
terminated
已终止状态,线程已经结束运行
1.当一个线程run方法执行结束,或者main函数执行完毕后,我们认为这个线程就是终止了。这个线程对象也许是活的,但是已经不再是一个单独执行的线程。线程一旦终止了,就不能复生。 2.在一个已终止的线程上调用start方法,会抛出java.lang.IllegalThreadStateExecption 异常
多线程
多线程的意义
发挥处理器最大性能
创建线程的方式
继承Thread类
实现Runnable接口
避免多继承局限
可以更好的体现共享的概念
实现Callable接口
通过线程池启动多线程
runnable 和 callable 有什么区别
Runnable 接口 run 方法无返回值
只能抛出运行时异常,且无法捕获处理
Callable 接口 call 方法有返回值,支持泛型
允许抛出异常,可以获取异常信息
如何进行信息交互
void notify()
随机唤醒在此对象的等待池(监视器)上等待的单个线程,进入锁池
void notifyAll()
唤醒在此对象的等待池(监视器)上等待的所有线程,进入锁池
void wait()
导致当前的线程等待,直到其他线程调用此对象的notify()方法或notifyAll()方法
void wait(long timeout)
同上+或者超过指定的时间量
void wait(long timeout, int nanos)
同上+或者其他某个线程中断当前线程
JMM
原子性
一个或者多个操作在 CPU 执行的过程中不被中断的特性
Atomic开头的原子类
CAS 原理
CAS 包含 3 个参数,CAS(V, E, N)。V 表示需要更新的变量,E 表示变量当前期望值,N 表示更新为的值。只有当变量 V 的值等于 E 时,变量 V 的值才会被更新为 N。如果变量 V 的值不等于 E ,说明变量 V 的值已经被更新过,当前线程什么也不做,返回更新失败。 当多个线程同时使用 CAS 更新一个变量时,只有一个线程可以更新成功,其他都失败。失败的线程不会被挂起,可以继续重试 CAS,也可以放弃操作。 CAS 操作的原子性是通过 CPU 单条指令完成而保障的。JDK 中是通过 Unsafe 类中的 API 完成的。 在并发量很高的情况,会有大量 CAS 更新失败,所以需要慎用。
AtomicLong >> LongAdder
AtomicLong 是基于 CAS 方式自旋更新
LongAdder 是把 value 分成若干cell
AtomicLong 是基于 CAS 方式自旋更新的;LongAdder 是把 value 分成若干cell,并发量低的时候,直接 CAS 更新值,成功即结束。并发量高的情况,CAS更新某个cell值和需要时对cell数据扩容,成功结束;更新失败自旋 CAS 更新 cell值。取值的时候,调用 sum() 方法进行每个cell累加。 AtomicLong 包含有原子性的读、写结合的api;LongAdder 没有原子性的读、写结合的api,能保证结果最终一致性。 低并发场景AtomicLong 和 LongAdder 性能相似,高并发场景 LongAdder 性能优于 AtomicLong。
可见性
各个线程对主内存共享变量操作,需要先将之拷贝到线程各自的工作内存中,然后进行操作,最后写回主内存。 主内存的某一共享变量值发生改变,将改变后的值推送给所有该变量的副本。
一个线程对共享变量的修改,另外一个线程能够立刻看到
volatile
有序性
程序执行的 顺序按照 代码的 先后顺序执行
Happens-Before 规则
程序次序规则
在一个线程内,按照程序控制流顺序,书写在前面的操作先行发生于书写在后面的操作
管程锁定规则
一个unlock操作先行发生于后面对同一个锁的lock操作
volatile变量规则
对一个volatile变量的写操作先行发生于后面对这个变量的读操作
线程启动规则
Thread对象的start()方法先行发生于此线程的每一个动作
线程终止规则
线程中的所有操作都先行发生于对此线程的终止检测
线程中断规则
对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
对象终结规则
一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始
ThreadLocal 线程本地存储
每个线程可以访问自己内部 ThreadLocalMap 对象内的 value
例如:每个线程分配一个 JDBC 连接 Connection
线程池
利用Executors创建不同的线程池满足不同场景的需求
newFixedThreadPool(int nThreads)
指定工作线程数量的线程池
newCachedThreadPool(
处理大量短时间工作任务的线程池
试图缓存线程并重用,当无缓存线程可用时,就会创建新的工作线程
如果线程闲置的时间超过阈值,则会被终止并移出缓存
系统长时间闲置的时候,不会消耗什么资源
newSingleThreadPool()
创建唯一的工作线程来执行任务,如果线程异常结束,会有另一个线程取代它
newSingleThreadScheduledExecutor()和newScheduledThreadPool(int corePoolSize)
定时或周期性的工作调度,区别在于单一工作线程还是多线程
newWorkStealingPool()
内部会构建ForkJoinPool,利用work-stealing算法,并行地处理任务,不保证处理
Fork/jion框架
Java7提供的并行任务框架
把大任务分割成若干个小任务并行执行,最终汇总每个小任务结果后得到大任务结果的框架
work-stealing算法
某个线程从其他队列里窃取任务来执行

Fork会将任务分到不同的队列里,并为每个队列,创建单独的线程去执行
当某个线程执行自己的任务队列完成后,会窃取其他线程的队列里的任务去执行
队列采取双端队列,被窃取的线程永远从双端队列的头部拿任务执行,窃取的线程永远从双端队列的尾部拿任务执行
Executor框架
是将任务的提交 和任务的运行分离开的框架

J.U.C的三个Executor接口
Executor
运行新任务的简单接口,将任务提交和任务执行细节
ExecutorService
具备管理执行器和任务声明周期的方法,提交任务机制更完善
ScheduledExecutorService
支持Future和定期执行任务
ThreadPoolExecutor的构造函数
corePoolSize
核心线程数量
maximumPoolSize
线程不够用时能够创建的最大线程数量
workQueue
任务等待队列
keepAliveTime
除了核心线程数量外,其他线程空闲时候的存活时间
抢占的顺序不一定,看运气
threadFactory
创建新线程
默认使用的是Executors.defaultThreadFactory
handler
饱和策略
AbortPolicy
直接抛出异常,这是默认策略
CallerRunsPolicy
用调用者所在的线程来执行任务
DiscardOldestPolicy
丢弃队列中最靠前的任务
discardPolicy
直接丢弃任务
实现RejectedExecutionHandler接口的自定义handler,来实现自己的业务需求
新任务提交execute执行后的判断
如果运行的线程少于corePoolSize,则会创建新线程来处理任务,即使线程池中其他线程是空闲的
如果线程池中得到线程数量大于等于corePoolSize,且小于 maximumPoolSize,则只有当workQueue满时才会创建新线程去处理,否则,塞入 workQueue
如果设置的corePoolSize 和maximumPoolSize相同,则创建的线程池大小是固定的 这时候如果有新任务提交,若workQueue未满,则将任务放入workQueue中,等待有空闲线程去从workQueue中去提取任务处理
如果运行的线程数量大于等于 maximunPoolSize,且如果workQueue已经满了 则通过handler所制定的策略来处理任务

线程池的状态
RUNNING
能接受新任务 并且能处理 workQueue中的任务
SHUDOWN
不再接受新任务,但是可以处理存量任务
STOP
不再接受新任务,也不出存量任务
TIDYING
所有任务已终止
TERMINATED
terminated(),方法执行后进入该状态

工作线程的生命周期

为什么使用线程池
降低资源消耗
提高线程的可管理性
线程池的大小如何选定
CPU密集型
线程数= 按照核数或者 核数+1来设定
I/O密集型
线程数= CPU核数*(1+平均等待时间/平均工作时间)
线程执行器executor
状态
Executor框架
Executors
newFixedThreadPool
定长线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量
newScheduledThreadPool
定长线程池,可执行周期性的任务
能够根据需要安排在给定延迟后运行命令或者定期地执行
newCachedThreadPool
可缓存的线程池,如果线程池的容量超过了任务数,自动回收空闲线程
任务增加时可以自动添加新线程,线程池的容量不限制
newSingleThreadExecutor
单线程的线程池,线程异常结束,会创建一个新的线程,能确保任务按提交顺序执行
newSingleThreadScheduledExecutor
单线程可执行周期性任务的线程池
newWorkStealingPool
任务窃取线程池,不保证执行顺序,适合任务耗时差异较大
默认创建的并行 level 是 CPU 的核数。 主线程结束,即使线程池有任务也会立即停止
ForkJoinTask
解决 CPU 负载不均衡的问题
使用分治法充分利用多核CPU
任务切分
结果合并
ThreadPoolExecutor 线程池基类
corePoolSize
核心线程数
maximumPoolSize
最大线程数
keepAliveTime
空闲线程存活时间
unit
存活时间单位
workQueue
任务阻塞队列
threadFactory
创建新线程时所需要的工厂
handler
拒绝策略
AbortPolicy
默认,队列满了丢弃任务,抛出异常
DiscardPolicy
队列满了丢弃任务,不抛异常
DiscardOldestPolicy
将最早进入队列的任务删除,然后再尝试加入队列
CallerRunPolicy
如果添加到线程池失败,那主线程会自己去执行该任务
四种拒绝策略
SecheduleThreadPoolExecutor
主要用于给定延迟之后运行任务,或定期执行的任务
ExecutorCompletionService
内部管理者一个已经完成任务的阻塞队列
submit()
提交任务,最终会委托给内部的executor去执行任务
参数 (Runnable) 或 (Runnable 和 结果 T) 或 (Callable)
返回值 Future 调用get方法时,可以捕获处理异常
take()
如果阻塞队列中已经有已完成的任务,则返回任务结果,否则阻塞等待任务完成
poll()
如果队列中有任务完成就返回,否则返回null
pull(long,TimeUnit)
如果队列中有任务完成则返回任务的结果,否则等待指定的时间, 如果还是没有任务完成,则返回null
Fork/Join框架
ForkJoinPool
是ExecutorService的一个补充,而不是替代品,特别适合用于分而治之,递归计算的算法
RecursiveTask
有返回结果的任务
RecursiveAction
无返回结果的计算
线程框架
JUC
【 java.util.concurrent开发包 】
核心类
TimeUnit工具类
ThreadFactory线程工厂类
CAS
是java.util.concurrent.autimic包基础
atomic (原子变量类)
原子类建立在CAS和volatile之上,CAS是非阻塞算法的一种常用实现,相对于synchronized这种阻塞算法,性能更好
普通原子类
AtomicBoolean
AtomicLong
AtomicInteger
AtomicIntegerArray
AtomicLongArray
Reference原子类
AtomicReference
AtomicReferenceArray
解决ABA
AtomicMarkableReference
AtomicStampedReference
增强原子类
LongAccumulator
自定义实现的long类型累加器,其构造函数接受一个双目运算器接口,根据输入的两个参数返回一个计算值,另外一个参数则是累加器的初始值
DoubleAccumulator
自定义实现的double类型的累加器,同LongAccumulator
LongAdder
long类型的原子操作,并发比LongAtomic好,优先使用 LongAdder是LongAccumulator的一个特例
DoubleAdder
double类型的原子操作,同LongAdder
核心组件
锁机制
Lock
ReadWriteLock
AQS(队列同步器)
是java.util.concurrent.locks包,以及一些常用类Semophore,ReentratLock等类基础
AbstractOwnableSynchronizer(排它锁)
为实现依赖于先进先出FIFO等待队列的阻塞锁和相关 同步器<信号量、事件,等>提供一个框架
AbstractQueuedLongSynchronizer(64位同步器)
ReentrantLock 互斥锁
ReadWriteLock 读写锁
Condition 控制队列
LockSupport 阻塞原语
Semaphore 信号量
CountDownLatch 闭锁
CyclicBarrier 栅栏
Exchanger 交换机
CompletableFuture 线程回调
并发集合collections
并发队列
ArrayBlockingQueue
数组结构的有界阻塞队列
LinkedBlockingDueue
链表结构的阻塞队列,不指定大小为无界的
LinkedBlockingQueue
链表结构的双向阻塞队列.不指定大小为无界的
PriorityBlockingQueue
数组结构带优先级的有界阻塞队列,堆排序
DelayQueue
延迟阻塞队列
内部使用了PriorityQueue实现延迟
SynchronousQueue
同步阻塞队列,没有容量,put操作会一直阻塞, 直到有take操作才能继续往下执行
LinkedTransferQueue
组合了SychronousQueue和LinkedBlockingQueue的 无边界阻塞队列
阻塞队列BlockQueue,提供了阻塞的入队和出队的操作 主要用于生产者和消费者模式 在多线程的情况下 生产者在队列的尾部添加元素 消费者在队列的头部消费元素 从而达到将任务的 产生和消费隔离的目的
ConcurrentLinkedDeque
链表结构的线程安全队列
ConcurrentLinkedQueue
链表结构的线程安全双向队列
非阻塞队列
并发集合
ConcurrentHashMap
线程安全的Map,数组+链表/红黑树结构
ConcurrentHashMap.newKeySet()
线程安全的操作
ConcurrentSkipListMap
线程安全,按照key排序的Map,跳表结构
ConcurrentSkipListSet
线程安全,有序的Set,跳表结构
CopyOnWriteArrayList
写使复制的List,读多写少的场景
CopyOnWriteArraySet
写时复制的Set,读多写少的场景
并发工具类tools
CountDownLatch
闭锁,能够使一个线程在等另外一些线程完成各自的工作后在,再继续的执行
CyclicBarrier
栅栏,能使多个线程等待一个条件达成之后,再继续执行
Semaphore
信号量,一个计数的信号量,必须由获取它的线程释放,常用于限制可以访问某些资源的线程数
Exchanger
交换器,用于两个工作线程之间交换数据的封装工具类
其他
TimeUnit
ThreadLocalRandom
多线程下随机数生成性能的提升,避免竞争同一个seed(种子)
线程安全与数据同步
CountDownLatch
让一个线程或多个线程等待
Semaphore
线程同步的辅助类,可以维护当前访问自身的线程个数,并提供了同步
CyclicBarrier
实现一组线程相互等待,当所有线程都到达某个屏障点后再进行后续操作
volatile
JVM提供的轻量级同步机制
作用
只能作用于变量
表示变量在 CPU 的寄存器中是不确定的,必须从主存中读取
特点
保证可见性
不保证原子性
禁止指令重排
线程阻塞
锁
偏向锁 轻量级锁 重量级锁 适用场景 只有一个线程进入同步块 虽然很多线程,但是没有冲突:多条线程进入同步块,但是线程进入时间错开因而并未争抢锁 发生了锁争抢的情况:多条线程进入同步块并争用锁 本质 取消同步操作 CAS操作代替互斥同步 互斥同步 优点 不阻塞,执行效率高(只有第一次获取偏向锁时需要CAS操作,后面只是比对ThreadId) 不会阻塞 不会空耗CPU 缺点 适用场景太局限。若竞争产生,会有额外的偏向锁撤销的消耗 长时间获取不到锁空耗CPU 阻塞,上下文切换,重量级操作,消耗操作系统资源
级别分类
无锁
无锁:没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功,其他修改失败的线程会不断重试直到修改成功。
偏向锁
偏向锁:对象的代码一直被同一线程执行,不存在多个线程竞争,该线程在后续的执行中自动获取锁,降低获取锁带来的性能开销。偏向锁,指的就是偏向第一个加锁线程,该线程是不会主动释放偏向锁的,只有当其他线程尝试竞争偏向锁才会被释放。 偏向锁的撤销,需要在某个时间点上没有字节码正在执行时,先暂停拥有偏向锁的线程,然后判断锁对象是否处于被锁定状态。如果线程不处于活动状态,则将对象头设置成无锁状态,并撤销偏向锁; 如果线程处于活动状态,升级为轻量级锁的状态。
轻量级锁
轻量级锁:轻量级锁是指当锁是偏向锁的时候,被第二个线程 B 所访问,此时偏向锁就会升级为轻量级锁,线程 B 会通过自旋的形式尝试获取锁,线程不会阻塞,从而提高性能。 当前只有一个等待线程,则该线程将通过自旋进行等待。但是当自旋超过一定的次数时,轻量级锁便会升级为重量级锁;当一个线程已持有锁,另一个线程在自旋,而此时又有第三个线程来访时,轻量级锁也会升级为重量级锁。
重量级锁
重量级锁:指当有一个线程获取锁之后,其余所有等待获取该锁的线程都会处于阻塞状态。 重量级锁通过对象内部的监视器(monitor)实现,而其中 monitor 的本质是依赖于底层操作系统的 Mutex Lock 实现,操作系统实现线程之间的切换需要从用户态切换到内核态,切换成本非常高。
产生原因
交叉锁
内存不足
数据库锁
一问一答式数据交换
死循环
死锁
线程死锁是指由于两个或者多个线程互相持有所需要的资源,导致这些线程一直处于等待其他线程释放资源的状态,无法前往执行,如果线程都不主动释放所占有的资源,将产生死锁。 当线程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。 产生原因: 持有系统不可剥夺资源,去竞争其他已被占用的系统不可剥夺资源,形成程序僵死的竞争关系。(不可剥夺资源如打印机等) 持有资源的锁,去竞争锁已被占用的其他资源,形成程序僵死的争关系。 信号量使用不当。 ...
四个必要条件
互斥条件
一段时间内某资源仅为一个线程所占有,其他请求该资源的线程只能等待
不剥夺条件
线程所获得的资源在未使用完毕之前,不能被其他线程强行夺走
只能由获得该资源的线程自己主动释放
请求和保持条件
线程已经保持了至少一个资源,但又提出了新的资源请求
而该资源已被其他线程占有,此时请求线程被阻塞
对自己已获得的资源保持不放
循环等待条件
存在一种线程资源的循环等待链
每一个线程已获得的资源同时被链中下一个线程所请求
避免死锁的方式
加锁顺序
线程按照一定的顺序加锁
加锁时限
线程尝试获取锁的时候加上一定的时限
超过时限则放弃对该锁的请求,并释放自己占有的锁
死锁检测
诊断
jstack
jvisualvm
自旋锁
线程反复检查锁变量是否可用
自旋锁:线程获取锁的时候,如果锁被其他线程持有,则当前线程将循环等待,直到获取到锁。 自旋锁等待期间,线程的状态不会改变,线程一直是用户态并且是活动的(active)。 自旋锁如果持有锁的时间太长,则会导致其它等待获取锁的线程耗尽CPU。 自旋锁本身无法保证公平性,同时也无法保证可重入性。 基于自旋锁,可以实现具备公平性和可重入性质的锁。 TicketLock:采用类似银行排号叫好的方式实现自旋锁的公平性,但是由于不停的读取serviceNum,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。 CLHLock和MCSLock通过链表的方式避免了减少了处理器缓存同步,极大的提高了性能,区别在于CLHLock是通过轮询其前驱节点的状态,而MCS则是查看当前节点的锁状态。 CLHLock在NUMA架构下使用会存在问题。在没有cache的NUMA系统架构中,由于CLHLock是在当前节点的前一个节点上自旋,NUMA架构中处理器访问本地内存的速度高于通过网络访问其他节点的内存,所以CLHLock在NUMA架构上不是最优的自旋锁。
TicketLock锁主要解决公平性问题
CLH锁是一种基于链表的可扩展、高性能、公平的自旋锁
MCSLock则对本地变量的节点进行循环
CAS实现
CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B
当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做
深入原理
CAS票据
锁优化
JVM优化
优化的方向就是减少线程的阻塞
在 Java SE 1.6 中,锁一共有4个状态
无锁状态,偏向锁状态, 轻量级锁状态,重量级锁状态
状态会随着竞争情况逐渐升级
锁升级之后不能降级
锁消除
JIT 编译器对一些没有必要同步的代码却同步了的锁进行消除
逃逸分析
就是观察某一个变量是否 会逃出某一个作用域
锁粗化
如果一系列连续操作都对同一个对象反复加锁和解锁
JVM将会把加锁同步的范围扩展(粗化)到整个操作序列的外部
程序优化
减小锁的持有时间
减小锁的粒度
使用读写锁替换独占锁
锁分离
无锁
CAS
synchronized同步锁
作用
修饰一个代码块
同步语句块
其作用的范围是大括号{}括起来的代码
作用的对象是调用这个代码块的对象
修饰一个方法
修饰一个静态的方法
修饰一个类
分类
方法锁
对象锁 synchronized(this)
类锁 synchronized(Demo.Class)
特点
保证线程间的有序性、原子性和可见性
线程阻塞
原理
字节码加标识
同步代码块是通过 monitorenter 和 monitorexit 指令获取线程的执行权
同步方法通过加 ACC_SYNCHRONIZED 标识实现线程的执行权的控制
Lock
代码实现
lock()以阻塞方式获得锁,且阻塞态会忽略interrupt方法
lockInterruptibly()不同于lock()不会忽略interrupt方法
tryLock()以非阻塞方式获得锁,可以加时间参数
Lock和synchronized
相同点:Lock能完成synchronized所实现的所有功能
不同点:Lock有比synchronized更精确的线程语义和更好的性能
Lock的锁定是通过代码实现的
程序员手工释放,并且必须在finally从句中释放
synchronized是在JVM层面上实现的
自动释放锁
Lock锁的范围有局限性,块范围
synchronized可以锁住块、对象、类
ReetrantLock
可重入锁,互斥锁
ReeTrantReadWriteLock
可重入读写锁,读读共享,读写互斥,写写互斥
StampedLock
带时间戳的读写锁,不可重入
ReadWriteLock 读写锁
一种实现ReentrantReadWriteLock
特点: 包含一个 ReadLock 和 一个 WriteLock 对象 读锁与读锁不互斥;读锁与写锁,写锁与写锁互斥 适合对共享资源有读和写操作,写操作很少,读操作频繁的场景 可以从写锁降级到读锁。获取写锁->获取读锁->释放写锁 无法从读锁升级到写锁 读写锁支持中断 写锁支持Condition;读锁不支持Condition
synchronized 和 ReentrantLock 的区别
synchronized 竞争锁时会一直等待;ReentrantLock 可以尝试获取锁,并得到获取结果 synchronized 获取锁无法设置超时;ReentrantLock 可以设置获取锁的超时时间 synchronized 无法实现公平锁;ReentrantLock 可以满足公平锁,即先等待先获取到锁 synchronized 控制等待和唤醒需要结合加锁对象的 wait() 和 notify()、notifyAll();ReentrantLock 控制等待和唤醒需要结合 Condition 的 await() 和 signal()、signalAll() 方法 synchronized 是 JVM 层面实现的;ReentrantLock 是 JDK 代码层面实现 synchronized 在加锁代码块执行完或者出现异常,自动释放锁;ReentrantLock 不会自动释放锁,需要在 finally{} 代码块显示释放
wait和notify
wait
1)释放当前的对象锁
2)使得当前线程进入阻塞队列
notify
唤醒一个线程
高并发场景实战
Redis与JVM多级缓存架构
消息中间件流量削峰与异步处理
限流策略实现
Nginx限流
计数器
滑动时间窗口
令牌桶、漏桶算法
Sentinel/Hystrix限流
服务高峰降级实现
系统安全防刷策略
性能调优
JVM GC调优
GC
避免使用finalize()对象终结方法
Tomcat调优
Nginx调优
Java算法
二分查找
public static int biSearch(int []array,int a){ int lo=0; int hi=array.length-1; int mid; while(lo<=hi){ mid=(lo+hi)/2;//中间位置 if(array[mid]==a){ return mid+1; }else if(array[mid]<a){ //向右查找 lo=mid+1; }else{ //向左查找 hi=mid-1; } } return -1; }
冒泡排序算法
public static void bubbleSort1(int [] a, int n){ int i, j; for(i=0; i<n; i++){//表示 n 次排序过程。 for(j=1; j<n-i; j++){ if(a[j-1] > a[j]){//前面的数字大于后面的数字就交换 //交换 a[j-1]和 a[j] int temp; temp = a[j-1]; a[j-1] = a[j]; a[j]=temp; } } } }
插入排序算法
public void sort(int arr[]) { for(int i =1; i<arr.length;i++) { //插入的数 int insertVal = arr[i]; //被插入的位置(准备和前一个数比较) int index = i-1; //如果插入的数比被插入的数小 while(index>=0&&insertVal<arr[index]) { //将把 arr[index] 向后移动 arr[index+1]=arr[index]; //让 index 向前移动 index--; } //把插入的数放入合适位置 arr[index+1]=insertVal; } }
在已排序序列中从后向前扫描,找到相应的位置并插入。
插入排序非常类似于整扑克牌。
快速排序算法
快速排序的原理:选择一个关键值作为基准值。 比基准值小的都在左边序列(一般是无序的),
比基准值大的都在右边(一般是无序的)。一般选择序列的第一个元素。
一次循环:从后往前比较,用基准值和最后一个值比较,如果比基准值小的交换位置,如果没有继续比较下一个,直到找到第一个比基准值小的值才交换。找到这个值之后,又从前往后开始比较,如果有比基准值大的,交换位置,如果没有继续比较下一个,直到找到第一个比基准值大的值才交换。
直到从前往后的比较索引>从后往前比较的索引,结束第一次循环,此时,对于基准值来说,左右两边就是有序的了。
public void sort(int[] a,int low,int high){ int start = low; int end = high; int key = a[low]; while(end>start){ //从后往前比较 while(end>start&&a[end]>=key) //如果没有比关键值小的,比较下一个,直到有比关键值小的交换位置,然后又从前往后比较 end--; if(a[end]<=key){ int temp = a[end]; a[end] = a[start]; a[start] = temp; } //从前往后比较 while(end>start&&a[start]<=key) //如果没有比关键值大的,比较下一个,直到有比关键值大的交换位置 start++; if(a[start]>=key){ int temp = a[start]; a[start] = a[end]; a[end] = temp; } //此时第一次循环比较结束,关键值的位置已经确定了。左边的值都比关键值小,右边的 值都比关键值大,但是两边的顺序还有可能是不一样的,进行下面的递归调用 } //递归 if(start>low) sort(a,low,start-1);//左边序列。第一个索引位置到关键值索引-1 if(end<high) sort(a,end+1,high);//右边序列。从关键值索引+1 到最后一个 } }
希尔排序算法
思想:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序〞时,再对全体记录进行依次直接插入排序。
1. 操作方法:选择一个增量序列 t1,t2,…,tk,其中 ti>t, tk=1;
2. 按增量序列个数k,对序列进行 k趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
private void shellSort(int[] a) { int dk = a.length/2; while( dk >= 1 ){ ShellInsertSort(a, dk); dk = dk/2; } } private void ShellInsertSort(int[] a, int dk) { //类似插入排序,只是插入排序增量是 1,这里增量是 dk,把 1 换成 dk 就可以了 for(int i=dk;i<a.length;i++){ if(a[i]<a[i-dk]){ int j; int x=a[i];//x 为待插入元素 a[i]=a[i-dk]; for(j=i-dk; j>=0 && x<a[j];j=j-dk){ //通过循环,逐个后移一位找到要插入的位置。 a[j+dk]=a[j]; } a[j+dk]=x;//插入 } } }
归并排序算法
public class MergeSortTest { public static void main(String[] args) { int[] data = new int[] { 5, 3, 6, 2, 1, 9, 4, 8, 7 }; print(data); mergeSort(data); System.out.println("排序后的数组:"); print(data); } public static void mergeSort(int[] data) { sort(data, 0, data.length - 1); } public static void sort(int[] data, int left, int right) { if (left >= right) return; // 找出中间索引 int center = (left + right) / 2; // 对左边数组进行递归 sort(data, left, center); // 对右边数组进行递归 sort(data, center + 1, right); // 合并 merge(data, left, center, right); print(data); }
/** * 将两个数组进行归并,归并前面 2 个数组已有序,归并后依然有序* * @param data * 数组对象 * @param left * 左数组的第一个元素的索引 * @param center * 左数组的最后一个元素的索引,center+1 是右数组第一个元素的索引 * @param right * 右数组最后一个元素的索引 */ public static void merge(int[] data, int left, int center, int right) { // 临时数组 int[] tmpArr = new int[data.length]; // 右数组第一个元素索引 int mid = center + 1; // third 记录临时数组的索引 int third = left; // 缓存左数组第一个元素的索引 int tmp = left; while (left <= center && mid <= right) { // 从两个数组中取出最小的放入临时数组 if (data[left] <= data[mid]) { tmpArr[third++] = data[left++]; } else { tmpArr[third++] = data[mid++]; } } // 剩余部分依次放入临时数组(实际上两个 while 只会执行其中一个) while (mid <= right) { tmpArr[third++] = data[mid++]; 13/04/2018 Page 240 of 283 } while (left <= center) { tmpArr[third++] = data[left++]; } // 将临时数组中的内容拷贝回原数组中 // (原 left-right 范围的内容被复制回原数组) while (tmp <= right) { data[tmp] = tmpArr[tmp++]; } } public static void print(int[] data) { for (int i = 0; i < data.length; i++) { System.out.print(data[i] + "\t"); } System.out.println(); } }
桶排序算法
桶排序的基本思想是:把数组 arr 划分为 n个大小相同子区间(桶),每个子区间各自排序,最后合并。计数排序是桶排序的一种特殊情况,可以把计数排序当成每个桶里只有一个元素的情况。
1.找出待排序数组中的最大值 max、最小值 min
2.我们使用 动态数组 ArrayList 作为桶,桶里放的元素也用 ArrayList 存储。桶的数量为(max-min)/arr.length+1
3.遍历数组 arr,计算每个元素 arrd] 放的桶
4.每个桶各自排序
public static void bucketSort(int[] arr){ int max = Integer.MIN_VALUE; int min = Integer.MAX_VALUE; for(int i = 0; i < arr.length; i++){ max = Math.max(max, arr[i]); min = Math.min(min, arr[i]); } //创建桶 int bucketNum = (max - min) / arr.length + 1; ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum); for(int i = 0; i < bucketNum; i++){ bucketArr.add(new ArrayList<Integer>()); } //将每个元素放入桶 for(int i = 0; i < arr.length; i++){ int num = (arr[i] - min) / (arr.length); bucketArr.get(num).add(arr[i]); } //对每个桶进行排序 for(int i = 0; i < bucketArr.size(); i++){ Collections.sort(bucketArr.get(i)); }}
基数排序算法
public class radixSort { inta[]={49,38,65,97,76,13,27,49,78,34,12,64,5,4,62,99,98,54,101,56,17,18,23,34,15,35,2 5,53,51}; public radixSort(){ sort(a); for(inti=0;i<a.length;i++){ System.out.println(a[i]); } } public void sort(int[] array){ //首先确定排序的趟数; int max=array[0]; for(inti=1;i<array.length;i++){ if(array[i]>max){ max=array[i]; } } int time=0; //判断位数; while(max>0){ max/=10; time++; } //建立 10 个队列; List<ArrayList> queue=newArrayList<ArrayList>(); for(int i=0;i<10;i++){ ArrayList<Integer>queue1=new ArrayList<Integer>(); queue.add(queue1); } //进行 time 次分配和收集; for(int i=0;i<time;i++){ //分配数组元素; for(intj=0;j<array.length;j++){ //得到数字的第 time+1 位数; int x=array[j]%(int)Math.pow(10,i+1)/(int)Math.pow(10, i); ArrayList<Integer>queue2=queue.get(x); queue2.add(array[j]); queue.set(x, queue2); } int count=0;//元素计数器; //收集队列元素; for(int k=0;k<10;k++){ while(queue.get(k).size()>0){ ArrayList<Integer>queue3=queue.get(k); array[count]=queue3.get(0); queue3.remove(0); count++; } } } } }
剪枝算法
在搜索算法中优化中,剪枝,就是通过某种判断,避免一些不必要的遍历过程,形象的说,就是剪去了搜索树中的某些〞枝条〞,故称剪枝。应用剪枝优化的核心问题是设计剪枝判断方法,即确定哪些枝条应当舍弃,哪些枝条应当保留的方法。
回溯算法
回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。
最短路径算法
从某顶点出发,沿图的边到达另一顶点所经过的路径中,各边上权值之和最小的一条路径叫做最短路径。解决最短路的问题有以下算法,Dijkstra 算法,Bellman-Ford 算法,Floyd 算法和 SPFA算法等。
最大子数组算法
最长公共子序算法
最小生成树算法
构造最小生成树有很多算法,但是他们都是利用了最小生成树的同一种性质:MST 性质(假设N=(V,{E})是一个连通网,U 是顶点集 V 的一个非空子集,如果(u,v)是一条具有最小权值的边,其中 u 属于 U,v 属于 V-U,则必定存在一颗包含边(u,v)的最小生成树),下面就介绍两种使用 MST 性质生成最小生成树的算法:普里姆算法和克鲁斯卡尔算法。
我们有 n 个顶点的连通网可以建立不同的生成树,每一颗生成树都可以作为一个通信网,当我们构造这个连通网所花的成本最小时,搭建该连通网的生成树,就称为最小生成树。
Java基础
面向对象
特征
封装
隐藏对象属性来保护对象内部状态
提高了代码的可用性和可维护性
禁止对象之间不良交互,提高模块化
继承
给对象提供了从基类获取字段和方法的能力
多态
给不同底层数据类型做相同的接口展示的能力
抽象
把类的行为和具体实现分离
面向对象基础
定义类与创建实例
理解类与实例 面向对象编程,是一种通过对象的方式,把现实世界映射到计算机模型的一种编程方法。 现实世界中,我们定义了“人”这种抽象概念,而具体的人则是“小明”、“小红”、“小军”等一个个具体的人。所以,“人”可以定义为一个类(class),而具体的人则是实例(instance)。 class是一种对象模版,它定义了如何创建实例,因此,class本身就是一种数据类型。 而instance是对象实例,instance是根据class创建的实例,可以创建多个instance,每个instance类型相同,但各自属性可能不相同。 定义class 在Java中,创建一个类,例如,给这个类命名为Person,就是定义一个class: class Person { public String name; public int age; } 一个class可以包含多个字段(field),字段用来描述一个类的特征。上面的Person类,我们定义了两个字段,一个是String类型的字段,命名为name,一个是int类型的字段,命名为age。因此,通过class,把一组数据汇集到一个对象上,实现了数据封装。 public是用来修饰字段的,它表示这个字段可以被外部访问。 我们再看另一个Book类的定义: class Book { public String name; public String author; public String isbn; public double price; } 请指出Book类的各个字段。 创建实例 定义了class,只是定义了对象模版,而要根据对象模版创建出真正的对象实例,必须用new操作符。 new操作符可以创建一个实例,然后,我们需要定义一个引用类型的变量来指向这个实例: Person ming = new Person(); 上述代码创建了一个Person类型的实例,并通过变量ming指向它。 注意区分Person ming是定义Person类型的变量ming,而new Person()是创建Person实例。 有了指向这个实例的变量,我们就可以通过这个变量来操作实例。访问实例变量可以用变量.字段,例如: ming.name = "Xiao Ming"; // 对字段name赋值 ming.age = 12; // 对字段age赋值 System.out.println(ming.name); // 访问字段name Person hong = new Person(); hong.name = "Xiao Hong"; hong.age = 15; 两个instance拥有class定义的name和age字段,且各自都有一份独立的数据,互不干扰。
方法
定义方法的语法是: 修饰符 方法返回类型 方法名(方法参数列表) { 若干方法语句; return 方法返回值; } 方法返回值通过return语句实现,如果没有返回值,返回类型设置为void,可以省略return。
构造方法
目的:在创建对象实例时就把内部字段全部初始化为合适的值
能否在创建对象实例时就把内部字段全部初始化为合适的值?完全可以。这时,我们就需要构造方法。 创建实例的时候,实际上是通过构造方法来初始化实例的。我们先来定义一个构造方法,能在创建Person实例的时候,一次性传入name和age,完成初始化: // 构造方法 public class Main { public static void main(String[] args) { Person p = new Person("Xiao Ming", 15); System.out.println(p.getName()); System.out.println(p.getAge()); } } class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return this.name; } public int getAge() { return this.age; } } 运行结果: Xiao Ming 15 由于构造方法是如此特殊,所以构造方法的名称就是类名。构造方法的参数没有限制,在方法内部,也可以编写任意语句。但是,和普通方法相比,构造方法没有返回值(也没有void),调用构造方法,必须用new操作符。
默认构造方法
是不是任何class都有构造方法?是的。那前面我们并没有为Person类编写构造方法,为什么可以调用new Person()?原因是如果一个类没有定义构造方法,编译器会自动为我们生成一个默认构造方法,它没有参数,也没有执行语句,类似这样: class Person { public Person() { } } 要特别注意的是,如果我们自定义了一个构造方法,那么,编译器就不再自动创建默认构造方法: // 构造方法 public class Main { public static void main(String[] args) { Person p = new Person(); // 编译错误:找不到这个构造方法 } } class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return this.name; } public int getAge() { return this.age; } } 运行结果: Main.java:4: 错误: 无法将类 Person中的构造器 Person应用到给定类型; Person p = new Person(); // 编译错误:找不到这个构造方法 ^ 需要: String,int 找到: 没有参数 原因: 实际参数列表和形式参数列表长度不同 1 个错误 错误: 编译失败 如果既要能使用带参数的构造方法,又想保留不带参数的构造方法,那么只能把两个构造方法都定义出来: // 构造方法 public class Main { public static void main(String[] args) { Person p1 = new Person("Xiao Ming", 15); // 既可以调用带参数的构造方法 Person p2 = new Person(); // 也可以调用无参数构造方法 } } class Person { private String name; private int age; public Person() { } public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return this.name; } public int getAge() { return this.age; } } 没有在构造方法中初始化字段时,引用类型的字段默认是null,数值类型的字段用默认值,int类型默认值是0,布尔类型默认值是false: class Person { private String name; // 默认初始化为null private int age; // 默认初始化为0 public Person() { } }
初始化字段
可以对字段直接进行初始化: class Person { private String name = "Unamed"; private int age = 10; } 那么问题来了:既对字段进行初始化,又在构造方法中对字段进行初始化: class Person { private String name = "Unamed"; private int age = 10; public Person(String name, int age) { this.name = name; this.age = age; } } 当我们创建对象的时候,new Person("Xiao Ming", 12)得到的对象实例,字段的初始值是啥? 在Java中,创建对象实例的时候,按照如下顺序进行初始化: 先初始化字段,例如,int age = 10;表示字段初始化为10,double salary;表示字段默认初始化为0,String name;表示引用类型字段默认初始化为null; 执行构造方法的代码进行初始化。 因此,构造方法的代码由于后运行,所以,new Person("Xiao Ming", 12)的字段值最终由构造方法的代码确定。
多构造方法
可以定义多个构造方法,在通过new操作符调用的时候,编译器通过构造方法的参数数量、位置和类型自动区分: class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } public Person(String name) { this.name = name; this.age = 12; } public Person() { } } 如果调用new Person("Xiao Ming", 20);,会自动匹配到构造方法public Person(String, int)。 如果调用new Person("Xiao Ming");,会自动匹配到构造方法public Person(String)。 如果调用new Person();,会自动匹配到构造方法public Person()。 一个构造方法可以调用其他构造方法,这样做的目的是便于代码复用。调用其他构造方法的语法是this(…): class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } public Person(String name) { this(name, 18); // 调用另一个构造方法Person(String, int) } public Person() { this("Unnamed"); // 调用另一个构造方法Person(String) } }
this变量
在方法内部,可以使用一个隐含的变量this,它始终指向当前实例。因此,通过this.field就可以访问当前实例的字段。 如果没有命名冲突,可以省略this。例如: class Person { private String name; public String getName() { return name; // 相当于this.name } } 但是,如果有局部变量和字段重名,那么局部变量优先级更高,就必须加上this: class Person { private String name; public void setName(String name) { this.name = name; // 前面的this不可少,少了就变成局部变量name了 } }
参数
形式参数与实际参数
形式参数:是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传入的参数,简称“形参”。
实际参数:在主调函数中调用一个函数时,函数名后面括号中的参数称为“实际参数”,简称“实参”。
参数传递:java中方法参数传递方式是按值传递。
如果参数是基本类型,传递的是基本类型的字面量值的拷贝。
如果参数是引用类型,传递的是该参量所引用的对象在堆中地址值的拷贝。
值传递与引用传递的根本区别是会不会创建传递对象的副本。
参数绑定
基本类型参数的传递,是调用方值的复制。双方各自的后续修改,互不影响。引用类型参数的传递,调用方的变量,和接收方的参数变量,指向的是同一个对象。双方任意一方对这个对象的修改,都会影响对方。
方法重载:方法名相同,但各自的参数不同,称为方法重载
在一个类中,我们可以定义多个方法。如果有一系列方法,它们的功能都是类似的,只有参数有所不同,那么,可以把这一组方法名做成同名方法。例如,在Hello类中,定义多个hello()方法: class Hello { public void hello() { System.out.println("Hello, world!"); } public void hello(String name) { System.out.println("Hello, " + name + "!"); } public void hello(String name, int age) { if (age < 18) { System.out.println("Hi, " + name + "!"); } else { System.out.println("Hello, " + name + "!"); } } } 这种方法名相同,但各自的参数不同,称为方法重载(Overload)。 注意:方法重载的返回值类型通常都是相同的。 方法重载的目的是,功能类似的方法使用同一名字,更容易记住,因此,调用起来更简单。 举个例子,String类提供了多个重载方法indexOf(),可以查找子串: int indexOf(int ch):根据字符的Unicode码查找; int indexOf(String str):根据字符串查找; int indexOf(int ch, int fromIndex):根据字符查找,但指定起始位置; int indexOf(String str, int fromIndex)根据字符串查找,但指定起始位置。 试一试: // String.indexOf() public class Main { public static void main(String[] args) { String s = "Test string"; int n1 = s.indexOf('t'); int n2 = s.indexOf("st"); int n3 = s.indexOf("st", 4); System.out.println(n1); System.out.println(n2); System.out.println(n3); } } 运行结果: 3 2 5
访问控制修饰符
Java借助private、protected、public与默认修饰符提供了成员访问控制。适用于字段、方法或类。 注意:java的访问控制是停留在编译层的,也就是它不会在.class文件中留下任何的痕迹,只在编译的时候进行访问控制的检查。其实,通过反射的手段,是可以访问任何包下任何类中的成员,例如,访问类的私有成员也是可能的。
public:具有最大的访问权限,可以访问任何一个在classpath下的类、接口、异常等。它往往用于对外的情况,也就是对象或类对外的一种接口的形式。
protected:主要的作用就是用来保护子类的。它的含义在于子类可以用它修饰的成员,其他的不可以,它相当于传递给子类的一种继承的东西。
default:有时候也称为friendly,它是针对本包访问而设计的,任何处于本包下的类、接口、异常等,都可以相互访问,即使是父类没有用protected修饰的成员也可以。
private:访问权限仅限于类的内部,是一种封装的体现,例如,大多数成员变量都是修饰符为private的,它们不希望被其他任何外部的类访问。
继承:extends
继承是面向对象编程中非常强大的一种机制,它首先可以复用代码。当我们让Student从Person继承时,Student就获得了Person的所有功能,我们只需要为Student编写新增的功能。 Java使用extends关键字来实现继承: class Person { private String name; private int age; public String getName() {...} public void setName(String name) {...} public int getAge() {...} public void setAge(int age) {...} } class Student extends Person { // 不要重复name和age字段/方法, // 只需要定义新增score字段/方法: private int score; public int getScore() { … } public void setScore(int score) { … } } 可见,通过继承,Student只需要编写额外的功能,不再需要重复代码。 在OOP的术语中,我们把Person称为超类(super class),父类(parent class),基类(base class),把Student称为子类(subclass),扩展类(extended class)。
定义:Java继承是面向对象的最显著的一个特征。继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力。
作用:继承技术使得复用以前的代码非常容易,能够大大缩短开发周期,降低开发费用。
这种技术使得复用以前的代码非常容易,能够大大缩短开发周期,降低开发费用。比如可以先定义一个类叫车,车有以下属性:车体大小,颜色,方向盘,轮胎,而又由车这个类派生出轿车和卡车两个类,为轿车添加一个小后备箱,而为卡车添加一个大货箱。
关键字super:表示父类
super关键字表示父类(超类)。子类引用父类的字段时,可以用super.fieldName。例如: class Student extends Person { public String hello() { return "Hello, " + super.name; } } 实际上,这里使用super.name,或者this.name,或者name,效果都是一样的。编译器会自动定位到父类的name字段。 但是,在某些时候,就必须使用super。我们来看一个例子: // super public class Main { public static void main(String[] args) { Student s = new Student("Xiao Ming", 12, 89); } } class Person { protected String name; protected int age; public Person(String name, int age) { this.name = name; this.age = age; } } class Student extends Person { protected int score; public Student(String name, int age, int score) { this.score = score; } } 运行结果: Main.java:21: 错误: 无法将类 Person中的构造器 Person应用到给定类型; public Student(String name, int age, int score) { ^ 需要: String,int 找到: 没有参数 原因: 实际参数列表和形式参数列表长度不同 1 个错误 错误: 编译失败 运行上面的代码,会得到一个编译错误,大意是在Student的构造方法中,无法调用Person的构造方法。 这是因为在Java中,任何class的构造方法,第一行语句必须是调用父类的构造方法。如果没有明确地调用父类的构造方法,编译器会帮我们自动加一句super();,所以,Student类的构造方法实际上是这样: class Student extends Person { protected int score; public Student(String name, int age, int score) { super(); // 自动调用父类的构造方法 this.score = score; } } 但是,Person类并没有无参数的构造方法,因此,编译失败。解决方法是调用Person类存在的某个构造方法。例如: class Student extends Person { protected int score; public Student(String name, int age, int score) { super(name, age); // 调用父类的构造方法Person(String, int) this.score = score; } } 这样就可以正常编译了!因此我们得出结论:如果父类没有默认的构造方法,子类就必须显式调用super()并给出参数以便让编译器定位到父类的一个合适的构造方法。这里还顺带引出了另一个问题:即子类不会继承任何父类的构造方法。子类默认的构造方法是编译器自动生成的,不是继承的。
向上转型:把一个子类类型安全地变为父类类型的赋值,被称为向上转型。
这种把一个子类类型安全地变为父类类型的赋值,被称为向上转型(upcasting)。 向上转型实际上是把一个子类型安全地变为更加抽象的父类型: Student s = new Student(); Person p = s; // upcasting, ok Object o1 = p; // upcasting, ok Object o2 = s; // upcasting, ok 注意到继承树是Student > Person > Object,所以,可以把Student类型转型为Person,或者更高层次的Object。
向下转型:如果把一个父类类型强制转型为子类类型,就是向下转型。
和向上转型相反,如果把一个父类类型强制转型为子类类型,就是向下转型(downcasting)。例如: Person p1 = new Student(); // upcasting, ok Person p2 = new Person(); Student s1 = (Student) p1; // ok Student s2 = (Student) p2; // runtime error! ClassCastException! 如果测试上面的代码,可以发现: Person类型p1实际指向Student实例,Person类型变量p2实际指向Person实例。在向下转型的时候,把p1转型为Student会成功,因为p1确实指向Student实例,把p2转型为Student会失败,因为p2的实际类型是Person,不能把父类变为子类,因为子类功能比父类多,多的功能无法凭空变出来。因此,向下转型很可能会失败。失败的时候,Java虚拟机会报ClassCastException。 为了避免向下转型出错,Java提供了instanceof操作符,可以先判断一个实例究竟是不是某种类型: Person p = new Person(); System.out.println(p instanceof Person); // true System.out.println(p instanceof Student); // false Student s = new Student(); System.out.println(s instanceof Person); // true System.out.println(s instanceof Student); // true Student n = null; System.out.println(n instanceof Student); // false instanceof实际上判断一个变量所指向的实例是否是指定类型,或者这个类型的子类。如果一个引用变量为null,那么对任何instanceof的判断都为false。利用instanceof,在向下转型前可以先判断: Person p = new Student(); if (p instanceof Student) { // 只有判断成功才会向下转型: Student s = (Student) p; // 一定会成功 }
操作符instanceof
继承与组合的区别:继承是is关系,组合是has关系。
在使用继承时,我们要注意逻辑一致性。 考察下面的Book类: class Book { protected String name; public String getName() {...} public void setName(String name) {...} } 这个Book类也有name字段,那么,我们能不能让Student继承自Book呢? class Student extends Book { protected int score; } 显然,从逻辑上讲,这是不合理的,Student不应该从Book继承,而应该从Person继承。 究其原因,是因为Student是Person的一种,它们是is关系,而Student并不是Book。实际上Student和Book的关系是has关系。 具有has关系不应该使用继承,而是使用组合,即Student可以持有一个Book实例: class Student extends Person { protected Book book; protected int score; } 因此,继承是is关系,组合是has关系。
多态
定义:同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。在运行时,可以通过指向基类的指针,来调用实现派生类中的方法。
多态(Polymorphism)按字面的意思就是“多种状态”。在面向对象语言中,接口的多种不同的实现方式即为多态。引用Charlie Calverts对多态的描述——多态性是允许你将父对象设置成为一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作(摘自“Delphi4 编程技术内幕”)。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。多态性在Object Pascal和C++中都是通过虚函数实现的。
作用:允许添加更多类型的子类实现功能扩展,却不需要修改基于父类的代码。把不同的子类对象都当作父类来看,可以屏蔽不同子类对象之间的差异,写出通用的代码,做出通用的编程,以适应需求的不断变化。
把不同的子类对象都当作父类来看,可以屏蔽不同子类对象之间的差异,写出通用的代码,做出通用的编程,以适应需求的不断变化。 赋值之后,父类型的引用就可以根据当前赋值给它的子对象的特性以不同的方式运作。也就是说,父亲的行为像儿子,而不是儿子的行为像父亲。 举个例子:从一个基类中派生,响应一个虚命令,产生不同的结果。 比如从某个基类派生出多个子类,其基类有一个虚方法Tdoit,然后其子类也有这个方法,但行为不同,然后这些子类对象中的任何一个可以赋给其基类对象的引用,或者说将子对象地址赋给基类指针,这样其基类的对象就可以执行不同的操作了。实际上你是在通过其基类的引用来访问其子类对象的,你要做的就是一个赋值操作。 使用继承性的结果就是当创建了一个类的家族,在认识这个类的家族时,就是把子类的对象当作基类的对象,这种认识又叫作upcasting(向上转型)。这样认识的重要性在于:我们可以只针对基类写出一段程序,但它可以适应于这个类的家族,因为编译器会自动找出合适的对象来执行操作。这种现象又称为多态性。而实现多态性的手段又叫称动态绑定(dynamic binding)。 简单的说,建立一个父类对象的引用,它所指对象可以是这个父类的对象,也可以是它的子类的对象。java中当子类拥有和父类同样的函数,当通过这个父类对象的引用调用这个函数的时候,调用到的是子类中的函数。
实现多态的方法:虚函数,抽象类,覆盖,模板
覆写
定义:在继承关系中,子类如果定义了一个与父类方法签名完全相同的方法,被称为覆写。
在继承关系中,子类如果定义了一个与父类方法签名完全相同的方法,被称为覆写(Override)。 例如,在Person类中,我们定义了run()方法: class Person { public void run() { System.out.println("Person.run"); } } 在子类Student中,覆写这个run()方法: class Student extends Person { @Override public void run() { System.out.println("Student.run"); } } Override和Overload不同的是,如果方法签名如果不同,就是Overload,Overload方法是一个新方法;如果方法签名相同,并且返回值也相同,就是Override。 注意:方法名相同,方法参数相同,但方法返回值不同,也是不同的方法。在Java程序中,出现这种情况,编译器会报错。 class Person { public void run() { … } } class Student extends Person { // 不是Override,因为参数不同: public void run(String s) { … } // 不是Override,因为返回值不同: public int run() { … } } 加上@Override可以让编译器帮助检查是否进行了正确的覆写。希望进行覆写,但是不小心写错了方法签名,编译器会报错,但是@Override不是必需的。 // override public class Main { public static void main(String[] args) { } } class Person { public void run() {} } public class Student extends Person { @Override // Compile error! public void run(String s) {} }
覆写Object方法
因为所有的class最终都继承自Object,而Object定义了几个重要的方法: toString():把instance输出为String; equals():判断两个instance是否逻辑相等; hashCode():计算一个instance的哈希值。 在必要的情况下,我们可以覆写Object的这几个方法。例如: class Person { ... // 显示更有意义的字符串: @Override public String toString() { return "Person:name=" + name; } // 比较是否相等: @Override public boolean equals(Object o) { // 当且仅当o为Person类型: if (o instanceof Person) { Person p = (Person) o; // 并且name字段相同时,返回true: return this.name.equals(p.name); } return false; } // 计算hash: @Override public int hashCode() { return this.name.hashCode(); } }
toString():把instance输出为String
equals():判断两个instance是否逻辑相等
hashCode():计算一个instance的哈希值
税收例子
假设我们定义一种收入,需要给它报税,那么先定义一个Income类: class Income { protected double income; public double getTax() { return income * 0.1; // 税率10% } } 对于工资收入,可以减去一个基数,那么我们可以从Income派生出SalaryIncome,并覆写getTax(): class Salary extends Income { @Override public double getTax() { if (income <= 5000) { return 0; } return (income - 5000) * 0.2; } } 如果你享受国务院特殊津贴,那么按照规定,可以全部免税: class StateCouncilSpecialAllowance extends Income { @Override public double getTax() { return 0; } } 现在,我们要编写一个报税的财务软件,对于一个人的所有收入进行报税,可以这么写: public double totalTax(Income... incomes) { double total = 0; for (Income income: incomes) { total = total + income.getTax(); } return total; } 来试一下: // Polymorphic public class Main { public static void main(String[] args) { // 给一个有普通收入、工资收入和享受国务院特殊津贴的小伙伴算税: Income[] incomes = new Income[] { new Income(3000), new Salary(7500), new StateCouncilSpecialAllowance(15000) }; System.out.println(totalTax(incomes)); } public static double totalTax(Income... incomes) { double total = 0; for (Income income: incomes) { total = total + income.getTax(); } return total; } } class Income { protected double income; public Income(double income) { this.income = income; } public double getTax() { return income * 0.1; // 税率10% } } class Salary extends Income { public Salary(double income) { super(income); } @Override public double getTax() { if (income <= 5000) { return 0; } return (income - 5000) * 0.2; } } class StateCouncilSpecialAllowance extends Income { public StateCouncilSpecialAllowance(double income) { super(income); } @Override public double getTax() { return 0; } } 运行结果: 800.0 观察totalTax()方法:利用多态,totalTax()方法只需要和Income打交道,它完全不需要知道Salary和StateCouncilSpecialAllowance的存在,就可以正确计算出总的税。如果我们要新增一种稿费收入,只需要从Income派生,然后正确覆写getTax()方法就可以。把新的类型传入totalTax(),不需要修改任何代码。 可见,多态具有一个非常强大的功能,就是允许添加更多类型的子类实现功能扩展,却不需要修改基于父类的代码。
关键字final:用final修饰method可以阻止被子类覆写
Java还提供了一个final修饰符。final与访问权限不冲突,它有很多作用。 用final修饰class可以阻止被继承: package abc; // 无法被继承: public final class Hello { private int n = 0; protected void hi(int t) { long i = t; } } 用final修饰method可以阻止被子类覆写: package abc; public class Hello { // 无法被覆写: protected final void hi() { } } 用final修饰field可以阻止被重新赋值: package abc; public class Hello { private final int n = 0; protected void hi() { this.n = 1; // error! } } 用final修饰局部变量可以阻止被重新赋值: package abc; public class Hello { protected void hi(final int t) { t = 1; // error! } }
抽象类
定义:使用abstract修饰的类就是抽象类。
如果一个class定义了方法,但没有具体执行代码,这个方法就是抽象方法,抽象方法用abstract修饰。 因为无法执行抽象方法,因此这个类也必须申明为抽象类(abstract class)。 使用abstract修饰的类就是抽象类。我们无法实例化一个抽象类: Person p = new Person(); // 编译错误
作用:因为抽象类本身被设计成只能用于被继承,因此,抽象类可以强迫子类实现其定义的抽象方法,否则编译会报错。因此,抽象方法实际上相当于定义了“规范”。
例如,Person类定义了抽象方法run(),那么,在实现子类Student的时候,就必须覆写run()方法: // abstract class public class Main { public static void main(String[] args) { Person p = new Student(); p.run(); } } abstract class Person { public abstract void run(); } class Student extends Person { @Override public void run() { System.out.println("Student.run"); } } 运行结果: Student.run
面相抽象编程
当我们定义了抽象类Person,以及具体的Student、Teacher子类的时候,我们可以通过抽象类Person类型去引用具体的子类的实例: Person s = new Student(); Person t = new Teacher(); 这种引用抽象类的好处在于,我们对其进行方法调用,并不关心Person类型变量的具体子类型: // 不关心Person变量的具体子类型: s.run(); t.run(); 同样的代码,如果引用的是一个新的子类,我们仍然不关心具体类型: // 同样不关心新的子类是如何实现run()方法的: Person e = new Employee(); e.run(); 这种尽量引用高层类型,避免引用实际子类型的方式,称之为面向抽象编程。 面向抽象编程的本质就是: 上层代码只定义规范(例如:abstract class Person); 不需要子类就可以实现业务逻辑(正常编译); 具体的业务逻辑由不同的子类实现,调用者并不关心。
关键字abstract
接口
定义:interface就是比抽象类还要抽象的纯抽象接口,因为它连字段都不能有。
在抽象类中,抽象方法本质上是定义接口规范:即规定高层类的接口,从而保证所有子类都有相同的接口实现,这样,多态就能发挥出威力。 如果一个抽象类没有字段,所有方法全部都是抽象方法: abstract class Person { public abstract void run(); public abstract String getName(); } 就可以把该抽象类改写为接口:interface。 在Java中,使用interface可以声明一个接口: interface Person { void run(); String getName(); } 所谓interface,就是比抽象类还要抽象的纯抽象接口,因为它连字段都不能有。因为接口定义的所有方法默认都是public abstract的,所以这两个修饰符不需要写出来(写不写效果都一样)。 当一个具体的class去实现一个interface时,需要使用implements关键字。举个例子: class Student implements Person { private String name; public Student(String name) { this.name = name; } @Override public void run() { System.out.println(this.name + " run"); } @Override public String getName() { return this.name; } } 我们知道,在Java中,一个类只能继承自另一个类,不能从多个类继承。但是,一个类可以实现多个interface,例如: class Student implements Person, Hello { // 实现了两个interface ... }
抽象类与接口的区别
Java的接口特指interface的定义,表示一个接口类型和一组方法签名,而编程接口泛指接口规范,如方法签名,数据格式,网络协议等。 抽象类和接口的对比如下: abstract class interface 继承 只能extends一个class 可以implements多个interface 字段 可以定义实例字段 不能定义实例字段 抽象方法 可以定义抽象方法 可以定义抽象方法 非抽象方法 可以定义非抽象方法 可以定义default方法
关键字interface
default方法
在接口中,可以定义default方法。例如,把Person接口的run()方法改为default方法: // interface public class Main { public static void main(String[] args) { Person p = new Student("Xiao Ming"); p.run(); } } interface Person { String getName(); default void run() { System.out.println(getName() + " run"); } } class Student implements Person { private String name; public Student(String name) { this.name = name; } public String getName() { return this.name; } } 运行结果: Xiao Ming run 实现类可以不必覆写default方法。default方法的目的是,当我们需要给接口新增一个方法时,会涉及到修改全部子类。如果新增的是default方法,那么子类就不必全部修改,只需要在需要覆写的地方去覆写新增方法。 default方法和抽象类的普通方法是有所不同的。因为interface没有字段,default方法无法访问字段,而抽象类的普通方法可以访问实例字段。
静态字段和方法
静态字段:static 字段
在一个class中定义的字段,我们称之为实例字段。实例字段的特点是,每个实例都有独立的字段,各个实例的同名字段互不影响。还有一种字段,是用static修饰的字段,称为静态字段:static field。实例字段在每个实例中都有自己的一个独立“空间”,但是静态字段只有一个共享“空间”,所有实例都会共享该字段。举个例子: class Person { public String name; public int age; // 定义静态字段number: public static int number; } 我们来看看下面的代码: // static field public class Main { public static void main(String[] args) { Person ming = new Person("Xiao Ming", 12); Person hong = new Person("Xiao Hong", 15); ming.number = 88; System.out.println(hong.number); hong.number = 99; System.out.println(ming.number); } } class Person { public String name; public int age; public static int number; public Person(String name, int age) { this.name = name; this.age = age; } } 运行结果: 88 99 对于静态字段,无论修改哪个实例的静态字段,效果都是一样的:所有实例的静态字段都被修改了,原因是静态字段并不属于实例。虽然实例可以访问静态字段,但是它们指向的其实都是Person class的静态字段。所以,所有实例共享一个静态字段。因此,不推荐用实例变量.静态字段去访问静态字段,因为在Java程序中,实例对象并没有静态字段。在代码中,实例对象能访问静态字段只是因为编译器可以根据实例类型自动转换为类名.静态字段来访问静态对象。 推荐用类名来访问静态字段。可以把静态字段理解为描述class本身的字段(非实例字段)。对于上面的代码,更好的写法是: Person.number = 99; System.out.println(Person.number);
接口的静态字段
因为interface是一个纯抽象类,所以它不能定义实例字段。但是,interface是可以有静态字段的,并且静态字段必须为final类型: public interface Person { public static final int MALE = 1; public static final int FEMALE = 2; } 实际上,因为interface的字段只能是public static final类型,所以我们可以把这些修饰符都去掉,上述代码可以简写为: public interface Person { // 编译器会自动加上public statc final: int MALE = 1; int FEMALE = 2; } 编译器会自动把该字段变为public static final类型。
静态方法:static 方法
静态字段,就有静态方法。用static修饰的方法称为静态方法。调用实例方法必须通过一个实例变量,而调用静态方法则不需要实例变量,通过类名就可以调用。静态方法类似其它编程语言的函数。例如: // static method public class Main { public static void main(String[] args) { Person.setNumber(99); System.out.println(Person.number); } } class Person { public static int number; public static void setNumber(int value) { number = value; } } 运行结果: 99 因为静态方法属于class而不属于实例,因此,静态方法内部,无法访问this变量,也无法访问实例字段,它只能访问静态字段。通过实例变量也可以调用静态方法,但这只是编译器自动帮我们把实例改写成类名而已。通常情况下,通过实例变量访问静态字段和静态方法,会得到一个编译警告。 静态方法经常用于工具类。例如: Arrays.sort() Math.random() 静态方法也经常用于辅助方法。注意到Java程序的入口main()也是静态方法。
静态变量、静态方法初始化顺序
包
Java定义了一种名字空间,称之为包:package。一个类总是属于某个包,类名(比如Person)只是一个简写,真正的完整类名是包名.类名。使用package来解决名字冲突
在前面的代码中,我们把类和接口命名为Person、Student、Hello等简单名字。 在现实中,如果小明写了一个Person类,小红也写了一个Person类,现在,小白既想用小明的Person,也想用小红的Person,怎么办?如果小军写了一个Arrays类,恰好JDK也自带了一个Arrays类,如何解决类名冲突? 在Java中,我们使用package来解决名字冲突。 Java定义了一种名字空间,称之为包:package。一个类总是属于某个包,类名(比如Person)只是一个简写,真正的完整类名是包名.类名。 例如: 小明的Person类存放在包ming下面,因此,完整类名是ming.Person; 小红的Person类存放在包hong下面,因此,完整类名是hong.Person; 小军的Arrays类存放在包mr.jun下面,因此,完整类名是mr.jun.Arrays; JDK的Arrays类存放在包java.util下面,因此,完整类名是java.util.Arrays。 在定义class的时候,我们需要在第一行声明这个class属于哪个包。 小明的Person.java文件: package ming; // 申明包名ming public class Person { } 小军的Arrays.java文件: package mr.jun; // 申明包名mr.jun public class Arrays { } 在Java虚拟机执行的时候,JVM只看完整类名,因此,只要包名不同,类就不同。包可以是多层结构,用.隔开。例如:java.util。 要特别注意:包没有父子关系。java.util和java.util.zip是不同的包,两者没有任何继承关系。 没有定义包名的class,它使用的是默认包,非常容易引起名字冲突,因此,不推荐不写包名的做法。
包作用域:位于同一个包的类,可以访问包作用域的字段和方法。不用public、protected、private修饰的字段和方法就是包作用域。
位于同一个包的类,可以访问包作用域的字段和方法。不用public、protected、private修饰的字段和方法就是包作用域。例如,Person类定义在hello包下面: package hello; public class Person { // 包作用域: void hello() { System.out.println("Hello!"); } } Main类也定义在hello包下面: package hello; public class Main { public static void main(String[] args) { Person p = new Person(); p.hello(); // 可以调用,因为Main和Person在同一个包 } }
import关键字:mport的目的是为了让你写Xyz不用写abc.def.Xyz,和访问权限是两回事
ava编译器最终编译出的.class文件只使用完整类名,因此,在代码中,当编译器遇到一个class名称时: 如果是完整类名,就直接根据完整类名查找这个class; 如果是简单类名,按下面的顺序依次查找: 查找当前package是否存在这个class; 查找import的包是否包含这个class; 查找java.lang包是否包含这个class。 如果按照上面的规则还无法确定类名,则编译报错。 我们来看一个例子: // Main.java package test; import java.text.Format; public class Main { public static void main(String[] args) { java.util.List list; // ok,使用完整类名 -> java.util.List Format format = null; // ok,使用import的类 -> java.text.Format String s = "hi"; // ok,使用java.lang包的String -> java.lang.String System.out.println(s); // ok,使用java.lang包的System -> java.lang.System MessageFormat mf = null; // 编译错误:无法找到MessageFormat: MessageFormat cannot be resolved to a type } } 因此,编写class的时候,编译器会自动帮我们做两个import动作: 默认自动import当前package的其他class; 默认自动import java.lang.*。 注意:自动导入的是java.lang包,但类似java.lang.reflect这些包仍需要手动导入。 如果有两个class名称相同,例如,mr.jun.Arrays和java.util.Arrays,那么只能import其中一个,另一个必须写完整类名。
作用域
作用域(scope),程序设计概念,通常来说,一段程序代码中所用到的名字并不总是有效/可用的,而限定这个名字的可用性的代码范围就是这个名字的作用域。 作用域的使用提高了程序逻辑的局部性,增强程序的可靠性,减少名字冲突。
public、protected、private这些修饰符可以用来限定访问作用域。
局部变量:在方法内部定义的变量称为局部变量,局部变量作用域从变量声明处开始到对应的块结束。方法参数也是局部变量。
在方法内部定义的变量称为局部变量,局部变量作用域从变量声明处开始到对应的块结束。方法参数也是局部变量。 package abc; public class Hello { void hi(String name) { // ① String s = name.toLowerCase(); // ② int len = s.length(); // ③ if (len < 10) { // ④ int p = 10 - len; // ⑤ for (int i=0; i<10; i++) { // ⑥ System.out.println(); // ⑦ } // ⑧ } // ⑨ } // ⑩ } 我们观察上面的hi()方法代码: 方法参数name是局部变量,它的作用域是整个方法,即①~⑩; 变量s的作用域是定义处到方法结束,即②~⑩; 变量len的作用域是定义处到方法结束,即③~⑩; 变量p的作用域是定义处到if块结束,即⑤~⑨; 变量i的作用域是for循环,即⑥~⑧。 使用局部变量时,应该尽可能把局部变量的作用域缩小,尽可能延后声明局部变量。
final修饰符:Java还提供了一个final修饰符。final与访问权限不冲突,它有很多作用。
用final修饰class可以阻止被继承
用final修饰method可以阻止被子类覆写
用final修饰field可以阻止被重新赋值
用final修饰局部变量可以阻止被重新赋值
classpath和jar
classpath是JVM用到的一个环境变量,它用来指示JVM如何搜索class。 因为Java是编译型语言,源码文件是.java,而编译后的.class文件才是真正可以被JVM执行的字节码。因此,JVM需要知道,如果要加载一个abc.xyz.Hello的类,应该去哪搜索对应的Hello.class文件。 所以,classpath就是一组目录的集合,它设置的搜索路径与操作系统相关。例如,在Windows系统上,用;分隔,带空格的目录用""括起来,可能长这样: C:\work\project1\bin;C:\shared;"D:\My Documents\project1\bin" 在Linux系统上,用:分隔,可能长这样: /usr/shared:/usr/local/bin:/home/liaoxuefeng/bin 现在我们假设classpath是.;C:\work\project1\bin;C:\shared,当JVM在加载abc.xyz.Hello这个类时,会依次查找: <当前目录>\abc\xyz\Hello.class C:\work\project1\bin\abc\xyz\Hello.class C:\shared\abc\xyz\Hello.class 注意到.代表当前目录。如果JVM在某个路径下找到了对应的class文件,就不再往后继续搜索。如果所有路径下都没有找到,就报错。 classpath的设定方法有两种: 在系统环境变量中设置classpath环境变量,不推荐; 在启动JVM时设置classpath变量,推荐。 我们强烈不推荐在系统环境变量中设置classpath,那样会污染整个系统环境。在启动JVM时设置classpath才是推荐的做法。实际上就是给java命令传入-classpath或-cp参数: java -classpath .;C:\work\project1\bin;C:\shared abc.xyz.Hello 或者使用-cp的简写: java -cp .;C:\work\project1\bin;C:\shared abc.xyz.Hello 没有设置系统环境变量,也没有传入-cp参数,那么JVM默认的classpath为.,即当前目录: java abc.xyz.Hello 上述命令告诉JVM只在当前目录搜索Hello.class。 在IDE中运行Java程序,IDE自动传入的-cp参数是当前工程的bin目录和引入的jar包。 不要把任何Java核心库添加到classpath中!JVM根本不依赖classpath加载核心库! 更好的做法是,不要设置classpath!默认的当前目录.对于绝大多数情况都够用了。
模块
对比
抽象类和接口
本质:抽象是对类的抽象,是一种模板设计;接口是行为的抽象,是一种行为的规范
抽象类 abstract修饰
为子类提供一个公共的类型
封装子类中的重复属性和方法
抽象类中不一定包含抽象方法,但是有抽象方法的类必定是抽象类,不可被实例化
构造方法,类方法(用 static 修饰的方法)不能声明为抽象方法
定义抽象方法
抽象方法:由abstract修饰的方法为抽象方法,抽象方法只有方法的定义,没有方法的实现 抽象方法不能被private、static、final或native并列修饰,只能被public、protected修饰 (如果为private则没有意义,因为子类无法继承,子类无法实现)
abstract修饰的方法
抽象类的子类,除非也是抽象类,否则必须实现该抽象类声明的方法
父类和派生类之间必须存在"is-a"关系,即父类和派生类在概念本质上应该是相同的
接口 interface修饰
接口的方法默认是public,所有方法在接口中不能有实现,抽象类可以有非抽象的方法
jdk9中,引入的私有方法(private method)和私有静态方法(private static method)
由于不可被继承,因此私有方法必须定义方法体才有意义。同时也意味着接口的私有方法和私有静态方法不可被实现该接口的类或继承该接口的接口调用或重写。私有方法(private method)和私有静态方法(private static method)的提出都是对jdk8提出的default和public static method的补充。 默认方法和静态方法可以共享接口中的私有方法,因此避免了代码冗余,这也使代码更加清晰。如果私有方法是静态的,那这个方法就属于这个接口的。并且没有静态的私有方法只能被在接口中的实例调用。
接口的实现,必须通过子类,子类使用关键字implements,而且接口可以多实现
一个类实现接口的话要实现接口的所有方法,而抽象类不一定
接口不能用new实例化,但可以声明,但是必须引用一个实现该接口的对象
接口中的成员变量只能是public static final类型的
实现者仅仅是实现了接口定义的行为契约而已,"like-a"的关系
重载和重写的区别
重载:发生在同一个类中,方法名必须相同,参数类型不同、个数不同
重写:发生在父子类中,方法名、参数列表必须相同,返回值小于等于父类
如果父类方法访问修饰符为private则子类中就不是重写
与面向过程比较
对象过程性能更高,缺点是没有面向对象容易维护和扩展
易维护、易复用、易扩展,性能比面向过程低
数据类型与运算
基本数据类型
整数值型
byte、short、int、long
字符型
char
布尔型
boolean
浮点型
double、float
包装类型
Byte、Short、Integer、Long
Boolean
Character
Float、Double
基本类型和包装类型区别
包装类型可以为 null,而基本类型不可以
包装类型可用于泛型,而基本类型不可以
基本类型比包装类型更高效
基本类型在栈中直接存储的具体数值,而包装类型则存储的是堆中的引用
两个包装类型的值可以相同,但却不相等
Integer chenmo = new Integer(10); Integer wanger = new Integer(10); System.out.println(chenmo == wanger); // false System.out.println(chenmo.equals(wanger )); // true
装箱与拆箱
把基本类型转换成包装类型的过程叫做装箱(boxing)
把包装类型转换成基本类型的过程叫做拆箱(unboxing)
引用类型
类
接口
数组
数组类型:int[] ns = new int[5]
定义一个数组类型的变量,使用数组类型“类型[]”,例如,int[]。和单个基本类型变量不同,数组变量初始化必须使用new int[5]表示创建一个可容纳5个int元素的数组。 Java的数组有几个特点: 数组所有元素初始化为默认值,整型都是0,浮点型是0.0,布尔型是false; 数组一旦创建后,大小就不可改变。 要访问数组中的某一个元素,需要使用索引。数组索引从0开始,例如,5个元素的数组,索引范围是0~4。 可以修改数组中的某一个元素,使用赋值语句,例如,ns[1] = 79;。 可以用数组变量.length获取数组大小: // 数组 public class Main { public static void main(String[] args) { // 5位同学的成绩: int[] ns = new int[5]; System.out.println(ns.length); // 5 } } Run 5 数组是引用类型,在使用索引访问数组元素时,如果索引超出范围,运行时将报错: // 数组 public class Main { public static void main(String[] args) { // 5位同学的成绩: int[] ns = new int[5]; int n = 5; System.out.println(ns[n]); // 索引n不能超出范围 } } Run Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: Index 5 out of bounds for length 5 at Main.main(Main.java:7) 也可以在定义数组时直接指定初始化的元素,这样就不必写出数组大小,而是由编译器自动推算数组大小。例如: // 数组 public class Main { public static void main(String[] args) { // 5位同学的成绩: int[] ns = new int[] { 68, 79, 91, 85, 62 }; System.out.println(ns.length); // 编译器自动推算数组大小为5 } } Run 5 还可以进一步简写为: int[] ns = { 68, 79, 91, 85, 62 };
命令行参数String[ ] args
Java程序的入口是main方法,而main方法可以接受一个命令行参数,它是一个String[]数组。 这个命令行参数由JVM接收用户输入并传给main方法: public class Main { public static void main(String[] args) { for (String arg : args) { System.out.println(arg); } } } 我们可以利用接收到的命令行参数,根据不同的参数执行不同的代码。例如,实现一个-version参数,打印程序版本号: public class Main { public static void main(String[] args) { for (String arg : args) { if ("-version".equals(arg)) { System.out.println("v 1.0"); break; } } } } 上面这个程序必须在命令行执行,我们先编译它: $ javac Main.java 然后,执行的时候,给它传递一个-version参数: $ java Main -version v 1.0 这样,程序就可以根据传入的命令行参数,作出不同的响应。
String
String对象是不可变的
String是被final修饰的,因而不能被继承
StringBuffer与StringBuilder
StringBuilder性能比StringBuffer高,但是线程不安全
字符串连接:+
Java的编译器对字符串做了特殊照顾,可以使用+连接任意字符串和其他数据类型,这样极大地方便了字符串的处理。例如: // 字符串连接 public class Main { public static void main(String[] args) { String s1 = "Hello"; String s2 = "world"; String s = s1 + " " + s2 + "!"; System.out.println(s); } } 运行结果: Hello world! 如果用+连接字符串和其他数据类型,会将其他数据类型先自动转型为字符串,再连接: // 字符串连接 public class Main { public static void main(String[] args) { int age = 25; String s = "age is " + age; System.out.println(s); } } 运行结果: age is 25
空值null与空字符串
引用类型的变量可以指向一个空值null,它表示不存在,即该变量不指向任何对象。例如: String s1 = null; // s1是null String s2; // 没有赋初值值,s2也是null String s3 = s1; // s3也是null String s4 = ""; // s4指向空字符串,不是null 注意要区分空值null和空字符串"",空字符串是一个有效的字符串对象,它不等于null。
枚举
标注
关键字
var
var关键字 有些时候,类型的名字太长,写起来比较麻烦。例如: StringBuilder sb = new StringBuilder(); 这个时候,如果想省略变量类型,可以使用var关键字: var sb = new StringBuilder(); 编译器会根据赋值语句自动推断出变量sb的类型是StringBuilder。对编译器来说,语句: var sb = new StringBuilder(); 实际上会自动变成: StringBuilder sb = new StringBuilder(); 因此,使用var定义变量,仅仅是少写了变量类型而已。
运算
整数运算
四则运算
自增/自减:++、--
Java还提供了++运算和--运算,它们可以对一个整数进行加1和减1的操作: // 自增/自减运算 public class Main { public static void main(String[] args) { int n = 3300; n++; // 3301, 相当于 n = n + 1; n--; // 3300, 相当于 n = n - 1; int y = 100 + (++n); // 不要这么写 System.out.println(y); } } 运行结果: 3401
位移
在计算机中,整数总是以二进制的形式表示。例如,int类型的整数7使用4字节表示的二进制如下: 00000000 0000000 0000000 00000111 可以对整数进行移位运算。对整数7左移1位将得到整数14,左移两位将得到整数28: int n = 7; // 00000000 00000000 00000000 00000111 = 7 int a = n << 1; // 00000000 00000000 00000000 00001110 = 14 int b = n << 2; // 00000000 00000000 00000000 00011100 = 28 int c = n << 28; // 01110000 00000000 00000000 00000000 = 1879048192 int d = n << 29; // 11100000 00000000 00000000 00000000 = -536870912 左移29位时,由于最高位变成1,因此结果变成了负数。 类似的,对整数28进行右移,结果如下: int n = 7; // 00000000 00000000 00000000 00000111 = 7 int a = n >> 1; // 00000000 00000000 00000000 00000011 = 3 int b = n >> 2; // 00000000 00000000 00000000 00000001 = 1 int c = n >> 3; // 00000000 00000000 00000000 00000000 = 0 如果对一个负数进行右移,最高位的1不动,结果仍然是一个负数: int n = -536870912; int a = n >> 1; // 11110000 00000000 00000000 00000000 = -268435456 int b = n >> 2; // 11111000 00000000 00000000 00000000 = -134217728 int c = n >> 28; // 11111111 11111111 11111111 11111110 = -2 int d = n >> 29; // 11111111 11111111 11111111 11111111 = -1 还有一种不带符号的右移运算,使用>>>,它的特点是符号位跟着动,因此,对一个负数进行>>>右移,它会变成正数,原因是最高位的1变成了0: int n = -536870912; int a = n >>> 1; // 01110000 00000000 00000000 00000000 = 1879048192 int b = n >>> 2; // 00111000 00000000 00000000 00000000 = 939524096 int c = n >>> 29; // 00000000 00000000 00000000 00000111 = 7 int d = n >>> 31; // 00000000 00000000 00000000 00000001 = 1 对byte和short类型进行移位时,会首先转换为int再进行位移。 仔细观察可发现,左移实际上就是不断地×2,右移实际上就是不断地÷2。
位运算
位运算是按位进行与、或、非和异或的运算。 与运算的规则是,必须两个数同时为1,结果才为1: n = 0 & 0; // 0 n = 0 & 1; // 0 n = 1 & 0; // 0 n = 1 & 1; // 1 或运算的规则是,只要任意一个为1,结果就为1: n = 0 | 0; // 0 n = 0 | 1; // 1 n = 1 | 0; // 1 n = 1 | 1; // 1 非运算的规则是,0和1互换: n = ~0; // 1 n = ~1; // 0 异或运算的规则是,如果两个数不同,结果为1,否则为0: n = 0 ^ 0; // 0 n = 0 ^ 1; // 1 n = 1 ^ 0; // 1 n = 1 ^ 1; // 0 对两个整数进行位运算,实际上就是按位对齐,然后依次对每一位进行运算。例如: // 位运算 public class Main { public static void main(String[] args) { int i = 167776589; // 00001010 00000000 00010001 01001101 int n = 167776512; // 00001010 00000000 00010001 00000000 System.out.println(i & n); // 167776512 } } 运行结果: 167776512 上述按位与运算实际上可以看作两个整数表示的IP地址10.0.17.77和10.0.17.0,通过与运算,可以快速判断一个IP是否在给定的网段内。
相关概念
运算优先级
在Java的计算表达式中,运算优先级从高到低依次是: ( ) ! ~ ++ -- * / % + - << >> >>> & | += -= *= /= 记不住也没关系,只需要加括号就可以保证运算的优先级正确。
溢出
要特别注意,整数由于存在范围限制,如果计算结果超出了范围,就会产生溢出,而溢出不会出错,却会得到一个奇怪的结果: // 运算溢出 public class Main { public static void main(String[] args) { int x = 2147483640; int y = 15; int sum = x + y; System.out.println(sum); // -2147483641 } } 运算结果: -2147483641
类型转换
在运算过程中,如果参与运算的两个数类型不一致,那么计算结果为较大类型的整型。例如,short和int计算,结果总是int,原因是short首先自动被转型为int: // 类型自动提升与强制转型 public class Main { public static void main(String[] args) { short s = 1234; int i = 123456; int x = s + i; // s自动转型为int short y = s + i; // 编译错误! } } 运行结果: Main.java:7: 错误: 不兼容的类型: 从int转换到short可能会有损失 short y = s + i; // 编译错误! ^ 1 个错误 错误: 编译失败 也可以将结果强制转型,即将大范围的整数转型为小范围的整数。强制转型使用(类型),例如,将int强制转型为short: int i = 12345; short s = (short) i; // 12345 要注意,超出范围的强制转型会得到错误的结果,原因是转型时,int的两个高位字节直接被扔掉,仅保留了低位的两个字节: // 强制转型 public class Main { public static void main(String[] args) { int i1 = 1234567; short s1 = (short) i1; // -10617 System.out.println(s1); int i2 = 12345678; short s2 = (short) i2; // 24910 System.out.println(s2); } } 运行结果: -10617 24910 因此,强制转型的结果很可能是错的。
浮点数运算
四则运算
相关概念
溢出
整数运算在除数为0时会报错,而浮点数运算在除数为0时,不会报错,但会返回几个特殊值: NaN表示Not a Number Infinity表示无穷大 -Infinity表示负无穷大 例如: double d1 = 0.0 / 0; // NaN double d2 = 1.0 / 0; // Infinity double d3 = -1.0 / 0; // -Infinity 这三种特殊值在实际运算中很少碰到,我们只需要了解即可。
强制转型
可以将浮点数强制转型为整数。在转型时,浮点数的小数部分会被丢掉。如果转型后超过了整型能表示的最大范围,将返回整型的最大值。例如: int n1 = (int) 12.3; // 12 int n2 = (int) 12.7; // 12 int n2 = (int) -12.7; // -12 int n3 = (int) (12.7 + 0.5); // 13 int n4 = (int) 1.2e20; // 2147483647 如果要进行四舍五入,可以对浮点数加上0.5再强制转型: // 四舍五入 public class Main { public static void main(String[] args) { double d = 2.6; int n = (int) (d + 0.5); System.out.println(n); } } 运行结果: 3
类型提升
如果参与运算的两个数其中一个是整型,那么整型可以自动提升到浮点型: // 类型提升 public class Main { public static void main(String[] args) { int n = 5; double d = 1.2 + 24.0 / n; // 6.0 System.out.println(d); } } 运行结果: 6.0 需要特别注意,在一个复杂的四则运算中,两个整数的运算不会出现自动提升的情况。例如: double d = 1.2 + 24 / 5; // 5.2 计算结果为5.2,原因是编译器计算24 / 5这个子表达式时,按两个整数进行运算,结果仍为整数4。
布尔运算
对于布尔类型boolean,永远只有true和false两个值。 布尔运算是一种关系运算,包括以下几类: 比较运算符:>,>=,<,<=,==,!= 与运算 && 或运算 || 非运算 ! 下面是一些示例: boolean isGreater = 5 > 3; // true int age = 12; boolean isZero = age == 0; // false boolean isNonZero = !isZero; // true boolean isAdult = age >= 18; // false boolean isTeenager = age >6 && age <18; // true 关系运算符的优先级从高到低依次是: ! >,>=,<,<= ==,!= && ||
比较运算符:>,>=,<,<=,==,!=
与运算: &&
或运算: ||
非运算: !
三元运算符:b ? x : y
Java还提供一个三元运算符b ? x : y,它根据第一个布尔表达式的结果,分别返回后续两个表达式之一的计算结果。示例: // 三元运算 public class Main { public static void main(String[] args) { int n = -100; int x = n >= 0 ? n : -n; System.out.println(x); } } 运行结果: 100 上述语句的意思是,判断n >= 0是否成立,如果为true,则返回n,否则返回-n。这实际上是一个求绝对值的表达式。 注意到三元运算b ? x : y会首先计算b,如果b为true,则只计算x,否则,只计算y。此外,x和y的类型必须相同,因为返回值不是boolean,而是x和y之一。
相关概念
短路运算:如果一个布尔运算的表达式能提前确定结果,则后续的计算不再执行,直接返回结果。
布尔运算的一个重要特点是短路运算。如果一个布尔运算的表达式能提前确定结果,则后续的计算不再执行,直接返回结果。 因为false && x的结果总是false,无论x是true还是false,因此,与运算在确定第一个值为false后,不再继续计算,而是直接返回false。 我们考察以下代码: // 短路运算 public class Main { public static void main(String[] args) { boolean b = 5 < 3; boolean result = b && (5 / 0 > 0); System.out.println(result); } } 运行结果: false 如果没有短路运算,&&后面的表达式会由于除数为0而报错,但实际上该语句并未报错,原因在于与运算是短路运算符,提前计算出了结果false。 如果变量b的值为true,则表达式变为true && (5 / 0 > 0)。因为无法进行短路运算,该表达式必定会由于除数为0而报错,可以自行测试。 类似的,对于||运算,只要能确定第一个值为true,后续计算也不再进行,而是直接返回true: boolean result = true || (5 / 0 > 0); // true
关系运算优先级
关系运算符的优先级从高到低依次是: ! >,>=,<,<= ==,!= && ||
引用类型
强引用
默认类型
GC Roots可达性分析:可达,仍被引用不回收;不可达,回收所有程序的场景,基本对象,自定义对象等。
String str = "xxx";
软引用
比强引用稍弱
内存足,不会被回收;内存不足,才回收
一般用在对内存非常敏感的资源上,用作缓存的场景比较多:网页缓存、图片缓存等
SoftReference<String> softReference = new SoftReference<String>(new String("xxx")); System.out.println(softReference.get());
弱引用
比软引用生命周期更短,只能存活到下一次垃圾收集之前
生命周期很短的对象,例如ThreadLocal中的Key
WeakReference<String> weakReference = new WeakReference<String>(new String("Misout的博客")); System.gc(); if(weakReference.get() == null) { System.out.println("weakReference已经被GC回收"); } // 结果 weakReference已经被GC回收
虚引用
必须和引用队列关联使用
业界暂无使用场景, 可能被JVM团队内部用来跟踪JVM的垃圾回收活动
随时会被回收, 创建了可能很快就会被回收
作用:为了更好的管理对象的内存,更好的进行垃圾回收
PhantomReference<String> phantomReference = new PhantomReference<String>(new String("Misout的博客"), new ReferenceQueue<String>()); System.out.println(phantomReference.get()); //结果总是Null
流程控制
输入和输出
输出:System.out.println(输出的内容)
println是print line的缩写,表示输出并换行。因此,如果输出后不想换行,可以用print(): // 输出 public class Main { public static void main(String[] args) { System.out.print("A,"); System.out.print("B,"); System.out.print("C."); System.out.println(); System.out.println("END"); } } 运行结果: A,B,C. END 格式化输出 Java还提供了格式化输出的功能。为什么要格式化输出?因为计算机表示的数据不一定适合人来阅读: // 格式化输出 public class Main { public static void main(String[] args) { double d = 12900000; System.out.println(d); // 1.29E7 } } 运行结果: 1.29E7 如果要把数据显示成我们期望的格式,就需要使用格式化输出的功能。格式化输出使用System.out.printf(),通过使用占位符%?,printf()可以把后面的参数格式化成指定格式: // 格式化输出 public class Main { public static void main(String[] args) { double d = 3.1415926; System.out.printf("%.2f\n", d); // 显示两位小数3.14 System.out.printf("%.4f\n", d); // 显示4位小数3.1416 } } Java的格式化功能提供了多种占位符,可以把各种数据类型“格式化”成指定的字符串: 占位符 说明 %d 格式化输出整数 %x 格式化输出十六进制整数 %f 格式化输出浮点数 %e 格式化输出科学计数法表示的浮点数 %s 格式化字符串 注意,由于%表示占位符,因此,连续两个%%表示一个%字符本身。 占位符本身还可以有更详细的格式化参数。下面的例子把一个整数格式化成十六进制,并用0补足8位: // 格式化输出 public class Main { public static void main(String[] args) { int n = 12345000; System.out.printf("n=%d, hex=%08x", n, n); // 注意,两个%占位符必须传入两个数 } } 运行结果: n=12345000, hex=00bc5ea8
输入:Scanner scanner = new Scanner(System.in); String name = scanner.nextLine();
和输出相比,Java的输入就要复杂得多。 我们先看一个从控制台读取一个字符串和一个整数的例子: import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); // 创建Scanner对象 System.out.print("Input your name: "); // 打印提示 String name = scanner.nextLine(); // 读取一行输入并获取字符串 System.out.print("Input your age: "); // 打印提示 int age = scanner.nextInt(); // 读取一行输入并获取整数 System.out.printf("Hi, %s, you are %d\n", name, age); // 格式化输出 } } 首先,我们通过import语句导入java.util.Scanner,import是导入某个类的语句,必须放到Java源代码的开头,后面我们在Java的package中会详细讲解如何使用import。 然后,创建Scanner对象并传入System.in。System.out代表标准输出流,而System.in代表标准输入流。直接使用System.in读取用户输入虽然是可以的,但需要更复杂的代码,而通过Scanner就可以简化后续的代码。 有了Scanner对象后,要读取用户输入的字符串,使用scanner.nextLine(),要读取用户输入的整数,使用scanner.nextInt()。Scanner会自动转换数据类型,因此不必手动转换。 要测试输入,我们不能在线运行它,因为输入必须从命令行读取,因此,需要走编译、执行的流程: javac Main.java
if判断
在Java程序中,如果要根据条件来决定是否执行某一段代码,就需要if语句。 if语句的基本语法是: if (条件) { // 条件满足时执行 } 根据if的计算结果(true还是false),JVM决定是否执行if语句块(即花括号{}包含的所有语句)。 让我们来看一个例子: // 条件判断 public class Main { public static void main(String[] args) { int n = 70; if (n >= 60) { System.out.println("及格了"); } System.out.println("END"); } } 运行结果: 及格了 END 当条件n >= 60计算结果为true时,if语句块被执行,将打印"及格了",否则,if语句块将被跳过。修改n的值可以看到执行效果。
if ... else if ..
可以用多个if ... else if ...串联。例如: // 条件判断 public class Main { public static void main(String[] args) { int n = 70; if (n >= 90) { System.out.println("优秀"); } else if (n >= 60) { System.out.println("及格了"); } else { System.out.println("挂科了"); } System.out.println("END"); } } 运行结果: 及格了 END
判断引用类型相等:equals( )方法
在Java中,判断值类型的变量是否相等,可以使用==运算符。但是,判断引用类型的变量是否相等,==表示“引用是否相等”,或者说,是否指向同一个对象。例如,下面的两个String类型,它们的内容是相同的,但是,分别指向不同的对象,用==判断,结果为false: // 条件判断 public class Main { public static void main(String[] args) { String s1 = "hello"; String s2 = "HELLO".toLowerCase(); System.out.println(s1); System.out.println(s2); if (s1 == s2) { System.out.println("s1 == s2"); } else { System.out.println("s1 != s2"); } } } 运行结果: hello hello s1 != s2 要判断引用类型的变量内容是否相等,必须使用equals()方法: // 条件判断 public class Main { public static void main(String[] args) { String s1 = "hello"; String s2 = "HELLO".toLowerCase(); System.out.println(s1); System.out.println(s2); if (s1.equals(s2)) { System.out.println("s1 equals s2"); } else { System.out.println("s1 not equals s2"); } } } 运行结果: hello hello s1 equals s2 注意:执行语句s1.equals(s2)时,如果变量s1为null,会报NullPointerException: // 条件判断 public class Main { public static void main(String[] args) { String s1 = null; if (s1.equals("hello")) { System.out.println("hello"); } } } 运行结果: Exception in thread "main" java.lang.NullPointerException at Main.main(Main.java:5) 要避免NullPointerException错误,可以利用短路运算符&&: // 条件判断 public class Main { public static void main(String[] args) { String s1 = null; if (s1 != null && s1.equals("hello")) { System.out.println("hello"); } } } 还可以把一定不是null的对象"hello"放到前面:例如:if ("hello".equals(s)) { ... }。
switch多重选择
除了if语句外,还有一种条件判断,是根据某个表达式的结果,分别去执行不同的分支。 例如,在游戏中,让用户选择选项: 单人模式 多人模式 退出游戏 这时,switch语句就派上用场了。 switch语句根据switch (表达式)计算的结果,跳转到匹配的case结果,然后继续执行后续语句,直到遇到break结束执行。 我们看一个例子: // switch public class Main { public static void main(String[] args) { int option = 1; switch (option) { case 1: System.out.println("Selected 1"); break; case 2: System.out.println("Selected 2"); break; case 3: System.out.println("Selected 3"); break; } } } 运行结果: Selected 1 如果option的值没有匹配到任何case,例如option = 99,那么,switch语句不会执行任何语句。这时,可以给switch语句加一个default,当没有匹配到任何case时,执行default: // switch public class Main { public static void main(String[] args) { int option = 99; switch (option) { case 1: System.out.println("Selected 1"); break; case 2: System.out.println("Selected 2"); break; case 3: System.out.println("Selected 3"); break; default: System.out.println("Not selected"); break; } } } 运行结果: Not selected 如果把switch语句翻译成if语句,那么上述的代码相当于: if (option == 1) { System.out.println("Selected 1"); } else if (option == 2) { System.out.println("Selected 2"); } else if (option == 3) { System.out.println("Selected 3"); } else { System.out.println("Not selected"); } 对于多个==判断的情况,使用switch结构更加清晰。
switch语句还可以匹配字符串。字符串匹配时,是比较“内容相等”
switch语句还可以匹配字符串。字符串匹配时,是比较“内容相等”。例如: // switch public class Main { public static void main(String[] args) { String fruit = "apple"; switch (fruit) { case "apple": System.out.println("Selected apple"); break; case "pear": System.out.println("Selected pear"); break; case "mango": System.out.println("Selected mango"); break; default: System.out.println("No fruit selected"); break; } } } 运行结果: Selected apple
穿透性
使用switch时,注意case语句并没有花括号{},而且,case语句具有“穿透性”,漏写break将导致意想不到的结果: // switch public class Main { public static void main(String[] args) { int option = 2; switch (option) { case 1: System.out.println("Selected 1"); case 2: System.out.println("Selected 2"); case 3: System.out.println("Selected 3"); default: System.out.println("Not selected"); } } } 运行结果: Selected 2 Selected 3 Not selected 当option = 2时,将依次输出"Selected 2"、"Selected 3"、"Not selected",原因是从匹配到case 2开始,后续语句将全部执行,直到遇到break语句。因此,任何时候都不要忘记写break。
循环
循环语句就是让计算机根据条件做循环计算,在条件满足时继续循环,条件不满足时退出循环。
while循环
Java提供的while条件循环。它的基本用法是: while (条件表达式) { 循环语句 } // 继续执行后续代码 while循环在每次循环开始前,首先判断条件是否成立。如果计算结果为true,就把循环体内的语句执行一遍,如果计算结果为false,那就直接跳到while循环的末尾,继续往下执行。 我们用while循环来累加1到100,可以这么写: // while public class Main { public static void main(String[] args) { int sum = 0; // 累加的和,初始化为0 int n = 1; while (n <= 100) { // 循环条件是n <= 100 sum = sum + n; // 把n累加到sum中 n ++; // n自身加1 } System.out.println(sum); // 5050 } } 运行结果: 5050
do while循环
在Java中,while循环是先判断循环条件,再执行循环。而另一种do while循环则是先执行循环,再判断条件,条件满足时继续循环,条件不满足时退出。它的用法是: do { 执行循环语句 } while (条件表达式); 可见,do while循环会至少循环一次。 我们把对1到100的求和用do while循环改写一下: // do-while public class Main { public static void main(String[] args) { int sum = 0; int n = 1; do { sum = sum + n; n ++; } while (n <= 100); System.out.println(sum); } } 运行结果: 5050 使用do while循环时,同样要注意循环条件的判断。 注意到while循环是先判断循环条件,再循环,因此,有可能一次循环都不做。
for循环
for循环的功能非常强大,它使用计数器实现循环。for循环会先初始化计数器,然后,在每次循环前检测循环条件,在每次循环后更新计数器。计数器变量通常命名为i。 我们把1到100求和用for循环改写一下: // for public class Main { public static void main(String[] args) { int sum = 0; for (int i=1; i<=100; i++) { sum = sum + i; } System.out.println(sum); } } 运行结果: 5050 在for循环执行前,会先执行初始化语句int i=1,它定义了计数器变量i并赋初始值为1,然后,循环前先检查循环条件i<=100,循环后自动执行i++,因此,和while循环相比,for循环把更新计数器的代码统一放到了一起。在for循环的循环体内部,不需要去更新变量i。 因此,for循环的用法是: for (初始条件; 循环检测条件; 循环后更新计数器) { // 执行语句 }
循环控制语句
break:跳出当前循环
continue:提前结束本次循环,直接继续执行下次循环
Java核心类
String
在Java中,String是一个引用类型,它本身也是一个class。但是,Java编译器对String有特殊处理,即可以直接用"..."来表示一个字符串。
创建:String s1 = "Hello"
在Java中,String是一个引用类型,它本身也是一个class。但是,Java编译器对String有特殊处理,即可以直接用"..."来表示一个字符串: String s1 = "Hello!"; 实际上字符串在String内部是通过一个char[]数组表示的,因此,按下面的写法也是可以的: String s2 = new String(new char[] {'H', 'e', 'l', 'l', 'o', '!'}); Java字符串的一个重要特点就是字符串不可变。这种不可变性是通过内部的private final char[]字段,以及没有任何修改char[]的方法实现的。
比较:s1.equals(s2)
两个字符串比较,必须总是使用equals()方法。 要忽略大小写比较,使用equalsIgnoreCase()方法。
搜索:s1.contain(s2) s1.indexOf(s2) / s1.lastIndexOf(s2) / s1.statsWith(s2) / s1.endWith(s2)
// 是否包含子串: "Hello".contains("ll"); // true "Hello".indexOf("l"); // 2 "Hello".lastIndexOf("l"); // 3 "Hello".startsWith("He"); // true "Hello".endsWith("lo"); // true
提取:s1.substring(index1, index2)
"Hello".substring(2); // "llo" "Hello".substring(2, 4); "ll"
去除首尾空白:s1.trim() / s1.strip()
使用trim()方法可以移除字符串首尾空白字符。空白字符包括空格,\t,\r,\n: " \tHello\r\n ".trim(); // "Hello" 注意:trim()并没有改变字符串的内容,而是返回了一个新字符串。 另一个strip()方法也可以移除字符串首尾空白字符。它和trim()不同的是,类似中文的空格字符\u3000也会被移除: "\u3000Hello\u3000".strip(); // "Hello" " Hello ".stripLeading(); // "Hello " " Hello ".stripTrailing(); // " Hello" String还提供了isEmpty()和isBlank()来判断字符串是否为空和空白字符串: "".isEmpty(); // true,因为字符串长度为0 " ".isEmpty(); // false,因为字符串长度不为0 " \n".isBlank(); // true,因为只包含空白字符 " Hello ".isBlank(); // false,因为包含非空白字符
替换字符串
replaceFirst(String regex,String replacement)
替换子串:s1.replace(s2, s3) / s1.replaceAll(regex)
要在字符串中替换子串,有两种方法。一种是根据字符或字符串替换: String s = "hello"; s.replace('l', 'w'); // "hewwo",所有字符'l'被替换为'w' s.replace("ll", "~~"); // "he~~o",所有子串"ll"被替换为"~~" 另一种是通过正则表达式替换: String s = "A,,B;C ,D"; s.replaceAll("[\\,\\;\\s]+", ","); // "A,B,C,D" 上面的代码通过正则表达式,把匹配的子串统一替换为","。
分割:s1.split(regex)
要分割字符串,使用split()方法,并且传入的也是正则表达式: String s = "A,B,C,D"; String[] ss = s.split("\\,"); // {"A", "B", "C", "D"}
拼接:String.join("拼接符号", String[])
拼接字符串使用静态方法join(),它用指定的字符串连接字符串数组: String[] arr = {"A", "B", "C"}; String s = String.join("***", arr); // "A***B***C"
获取字符串长度
str.length()
获取字符串某一位置的字符
str.charAt(4)
获取字符串的子串
str.substring(2,5)
字符串的比较
public int compareTo(String str) //该方法是对字符串内容按字典顺序进行大小比较, //通过返回的整数值指明当前字符串与参数字符串的大小关系。 //若当前对象比参数大则返回正整数,反之返回负整数,相等返回0。 public int compareToIgnoreCase (String str) //与compareTo方法相似,但忽略大小写。 public boolean equals(Object obj) //比较当前字符串和参数字符串,在两个字符串相等的时候返回true,否则返回false。 public boolean equalsIgnoreCase(String str) //与equals方法相似,但忽略大小写。
查找子串在字符串中的位置
public int indexOf(String str) //用于查找当前字符串中字符或子串,返回字符或 //子串在当前字符串中从左边起首次出现的位置,若没有出现则返回-1。 public int indexOf(String str, intfromIndex) //改方法与第一种类似,区别在于该方法从fromIndex位置向后查找。 public int lastIndexOf(String str) //该方法与第一种类似,区别在于该方法从字符串的末尾位置向前查找。 public int lastIndexOf(String str, intfromIndex) //该方法与第二种方法类似,区别于该方法从fromIndex位置向前查找。
str.indexOf('a')
str.indexOf('a',2)
str.lastIndexOf('a')
str.lastIndexOf('a',2)
字符串中字符的大小写转换
toLowerCase()
toUpperCase()
字符串两端去空格
trim()
将字符串分割成字符串数组
split(String str)
基本类型转换为字符串
String.valueOf(12.99)
基本类型类型转换成String:String.valueOf(基本类型)
要把任意基本类型或引用类型转换为字符串,可以使用静态方法valueOf()。这是一个重载方法,编译器会根据参数自动选择合适的方法: String.valueOf(123); // "123" String.valueOf(45.67); // "45.67" String.valueOf(true); // "true" String.valueOf(new Object()); // 类似java.lang.Object@636be97c
String转换成基本类型:Integer.parseInt(s1) / Double.parseDouble(s1) / Boolean.parseBoolean(s1)
要把字符串转换为其他类型,就需要根据情况。 例如,把字符串转换为int类型: int n1 = Integer.parseInt("123"); // 123 int n2 = Integer.parseInt("ff", 16); // 按十六进制转换,255 把字符串转换为boolean类型: boolean b1 = Boolean.parseBoolean("true"); // true boolean b2 = Boolean.parseBoolean("FALSE"); // false
String -> char[]:char[ ] cs = s1.toCharArray()
char[] -> String:String s = new String(cs)
通过new String(char[])创建新的String实例时,它并不会直接引用传入的char[]数组,而是会复制一份,所以,修改外部的char[]数组不会影响String实例内部的char[]数组,因为这是两个不同的数组。
类型转换
编码:byte[] b1 = s1.getBytes("某种编码方式")
解码:String s1 = new String(b1, "某种编码方式")
编码-解码
在Java中,char类型实际上就是两个字节的Unicode编码。如果我们要手动把字符串转换成其他编码,可以这样做: byte[] b1 = "Hello".getBytes(); // 按系统默认编码转换,不推荐 byte[] b2 = "Hello".getBytes("UTF-8"); // 按UTF-8编码转换 byte[] b2 = "Hello".getBytes("GBK"); // 按GBK编码转换 byte[] b3 = "Hello".getBytes(StandardCharsets.UTF_8); // 按UTF-8编码转换 注意:转换编码后,就不再是char类型,而是byte类型表示的数组。 如果要把已知编码的byte[]转换为String,可以这样做: byte[] b = ... String s1 = new String(b, "GBK"); // 按GBK转换 String s2 = new String(b, StandardCharsets.UTF_8); // 按UTF-8转换 始终牢记:Java的String和char在内存中总是以Unicode编码表示。
StringBuilder
StringBuilder是可变对象,用来高效拼接字符串; StringBuilder可以支持链式操作,实现链式操作的关键是返回实例本身; StringBuffer是StringBuilder的线程安全版本,现在很少使用。
创建:StringBuilder sb = new StringBuilder(缓冲区大小);
写入字符串:sb.append(s1).sappend(s2)...
为了能高效拼接字符串,Java标准库提供了StringBuilder,它是一个可变对象,可以预分配缓冲区,这样,往StringBuilder中新增字符时,不会创建新的临时对象: StringBuilder sb = new StringBuilder(1024); for (int i = 0; i < 1000; i++) { sb.append(','); sb.append(i); } String s = sb.toString(); StringBuilder还可以进行链式操作: public class Main { public static void main(String[] args) { var sb = new StringBuilder(1024); sb.append("Mr ") .append("Bob") .append("!") .insert(0, "Hello, "); System.out.println(sb.toString()); } }
删除字符串:sb.delete(start_index, end_index)
转换:String s1 = sb.toString()
StringJoiner
StringJoiner负责类似用分隔符拼接数组的内容,还可以指定“开头”和“结尾”: public class Main { public static void main(String[] args) { String[] names = {"Bob", "Alice", "Grace"}; var sj = new StringJoiner(", ", "Hello ", "!"); for (String name : names) { sj.add(name); } System.out.println(sj.toString()); } } 运行结果: Hello Bob, Alice, Grace!
创建:var sj = new StringJoiner(分隔符, 开始符号, 末尾符号)
写入字符串:sj.add(s1)
转换:String s1 = sb.toString()
包装类型
基本类型 对应的引用类型 boolean java.lang.Boolean byte java.lang.Byte short java.lang.Short int java.lang.Integer long java.lang.Long float java.lang.Float double java.lang.Double char java.lang.Character 注意:自动装箱和自动拆箱只发生在编译阶段,目的是为了少写代码。 装箱和拆箱会影响代码的执行效率,因为编译后的class代码是严格区分基本类型和引用类型的。并且,自动拆箱执行时可能会报NullPointerException: public class Main { public static void main(String[] args) { Integer n = null; int i = n; } } 包装类型的比较必须使用equals();
自动装箱:Integer n = 100; // 编译器自动使用Integer.valueOf(int)
这种直接把int变为Integer的赋值写法,称为自动装箱(Auto Boxing)
自动拆箱:int x = n; // 编译器自动使用Integer.intValue()
把Integer变为int的赋值写法,称为自动拆箱(Auto Unboxing)。
进制转换:int x2 = Integer.parseInt("100", 16); // 256,因为按16进制解析
Integer类本身还提供了大量方法,例如,最常用的静态方法parseInt()可以把字符串解析成一个整数: int x1 = Integer.parseInt("100"); // 100 int x2 = Integer.parseInt("100", 16); // 256,因为按16进制解析 Integer还可以把整数格式化为指定进制的字符串: // Integer: public class Main { public static void main(String[] args) { System.out.println(Integer.toString(100)); // "100",表示为10进制 System.out.println(Integer.toString(100, 36)); // "2s",表示为36进制 System.out.println(Integer.toHexString(100)); // "64",表示为16进制 System.out.println(Integer.toOctalString(100)); // "144",表示为8进制 System.out.println(Integer.toBinaryString(100)); // "1100100",表示为2进制 } }
静态变量
Java的包装类型还定义了一些有用的静态变量 // boolean只有两个值true/false,其包装类型只需要引用Boolean提供的静态字段: Boolean t = Boolean.TRUE; Boolean f = Boolean.FALSE; // int可表示的最大/最小值: int max = Integer.MAX_VALUE; // 2147483647 int min = Integer.MIN_VALUE; // -2147483648 // long类型占用的bit和byte数量: int sizeOfLong = Long.SIZE; // 64 (bits) int bytesOfLong = Long.BYTES; // 8 (bytes)
Number
所有的整数和浮点数的包装类型都继承自Number,因此,可以非常方便地直接通过包装类型获取各种基本类型: // 向上转型为Number: Number num = new Integer(999); // 获取byte, int, long, float, double: byte b = num.byteValue(); int n = num.intValue(); long ln = num.longValue(); float f = num.floatValue(); double d = num.doubleValue();
JavaBean
在Java中,有很多class的定义都符合这样的规范: 若干private实例字段; 通过public方法来读写实例字段。 public class Person { private String name; private int age; public String getName() { return this.name; } public void setName(String name) { this.name = name; } public int getAge() { return this.age; } public void setAge(int age) { this.age = age; } } 如果读写方法符合以下这种命名规范: // 读方法: public Type getXyz() // 写方法: public void setXyz(Type value) 那么这种class被称为JavaBean: 上面的字段是xyz,那么读写方法名分别以get和set开头,并且后接大写字母开头的字段名Xyz,因此两个读写方法名分别是getXyz()和setXyz()。 boolean字段比较特殊,它的读方法一般命名为isXyz(): // 读方法: public boolean isChild() // 写方法: public void setChild(boolean value) 我们通常把一组对应的读方法(getter)和写方法(setter)称为属性(property)。 JavaBean是一种符合命名规范的class,它通过getter和setter来定义属性; 属性是一种通用的叫法,并非Java语法规定; 可以利用IDE快速生成getter和setter; 使用Introspector.getBeanInfo()可以获取属性列表。
枚举类
为了让编译器能自动检查某个值在枚举的集合内,并且,不同用途的枚举需要不同的类型来标记,不能混用,我们可以使用enum来定义枚举类: // enum public class Main { public static void main(String[] args) { Weekday day = Weekday.SUN; if (day == Weekday.SAT || day == Weekday.SUN) { System.out.println("Work at home!"); } else { System.out.println("Work at office!"); } } } enum Weekday { SUN, MON, TUE, WED, THU, FRI, SAT; } 和int定义的常量相比,使用enum定义枚举有如下好处: 首先,enum常量本身带有类型信息,即Weekday.SUN类型是Weekday,编译器会自动检查出类型错误。 其次,不可能引用到非枚举的值,因为无法通过编译。 最后,不同类型的枚举不能互相比较或者赋值,因为类型不符。 综上,这就使得编译器可以在编译期自动检查出所有可能的潜在错误。 小结 Java使用enum定义枚举类型,它被编译器编译为final class Xxx extends Enum { … }; 通过name()获取常量定义的字符串,注意不要使用toString(); 通过ordinal()返回常量定义的顺序(无实质意义); 可以为enum编写构造方法、字段和方法 enum的构造方法要声明为private,字段强烈建议声明为final; enum适合用在switch语句中。
为什么使用枚举类?
在Java中,我们可以通过static final来定义常量。例如,我们希望定义周一到周日这7个常量,可以用7个不同的int表示: public class Weekday { public static final int SUN = 0; public static final int MON = 1; public static final int TUE = 2; public static final int WED = 3; public static final int THU = 4; public static final int FRI = 5; public static final int SAT = 6; } 使用常量的时候,可以这么引用: if (day == Weekday.SAT || day == Weekday.SUN) { // TODO: work at home } 也可以把常量定义为字符串类型,例如,定义3种颜色的常量: public class Color { public static final String RED = "r"; public static final String GREEN = "g"; public static final String BLUE = "b"; } 使用常量的时候,可以这么引用: String color = ... if (Color.RED.equals(color)) { // TODO: } 无论是int常量还是String常量,使用这些常量来表示一组枚举值的时候,有一个严重的问题就是,编译器无法检查每个值的合理性。例如: if (weekday == 6 || weekday == 7) { if (tasks == Weekday.MON) { // TODO: } } 上述代码编译和运行均不会报错,但存在两个问题: 注意到Weekday定义的常量范围是0~6,并不包含7,编译器无法检查不在枚举中的int值; 定义的常量仍可与其他变量比较,但其用途并非是枚举星期值。
创建:enum ClassName{A, B, C...}
比较:==
使用enum定义的枚举类是一种引用类型。前面我们讲到,引用类型比较,要使用equals()方法,如果使用==比较,它比较的是两个引用类型的变量是否是同一个对象。因此,引用类型比较,要始终使用equals()方法,但enum类型可以例外。 这是因为enum类型的每个常量在JVM中只有一个唯一实例,所以可以直接用==比较: if (day == Weekday.FRI) { // ok! } if (day.equals(Weekday.SUN)) { // ok, but more code! }
返回常量名:String s = ClassName.A.name()
返回定义常量的序号:int n = ClassName.A.ordinal()
ordinal() 返回定义的常量的顺序,从0开始计数,例如: int n = Weekday.MON.ordinal(); // 1 改变枚举常量定义的顺序就会导致ordinal()返回值发生变化。例如: public enum Weekday { SUN, MON, TUE, WED, THU, FRI, SAT; } 和 public enum Weekday { MON, TUE, WED, THU, FRI, SAT, SUN; } 的ordinal就是不同的。如果在代码中编写了类似if(x.ordinal()==1)这样的语句,就要保证enum的枚举顺序不能变。新增的常量必须放在最后。 有些童鞋会想,Weekday的枚举常量如果要和int转换,使用ordinal()不是非常方便?比如这样写: String task = Weekday.MON.ordinal() + "/ppt"; saveToFile(task); 但是,如果不小心修改了枚举的顺序,编译器是无法检查出这种逻辑错误的。要编写健壮的代码,就不要依靠ordinal()的返回值。因为enum本身是class,所以我们可以定义private的构造方法,并且,给每个枚举常量添加字段: public class Main { public static void main(String[] args) { Weekday day = Weekday.SUN; if (day.dayValue == 6 || day.dayValue == 0) { System.out.println("Work at home!"); } else { System.out.println("Work at office!"); } } } enum Weekday { MON(1), TUE(2), WED(3), THU(4), FRI(5), SAT(6), SUN(0); public final int dayValue; private Weekday(int dayValue) { this.dayValue = dayValue; } }
增加可读性:toString()
默认情况下,对枚举常量调用toString()会返回和name()一样的字符串。但是,toString()可以被覆写,而name()则不行。我们可以给Weekday添加toString()方法: // enum public class Main { public static void main(String[] args) { Weekday day = Weekday.SUN; if (day.dayValue == 6 || day.dayValue == 0) { System.out.println("Today is " + day + ". Work at home!"); } else { System.out.println("Today is " + day + ". Work at office!"); } } } enum Weekday { MON(1, "星期一"), TUE(2, "星期二"), WED(3, "星期三"), THU(4, "星期四"), FRI(5, "星期五"), SAT(6, "星期六"), SUN(0, "星期日"); public final int dayValue; private final String chinese; private Weekday(int dayValue, String chinese) { this.dayValue = dayValue; this.chinese = chinese; } @Override public String toString() { return this.chinese; } } 上述代码的运行结果如下: Today is 星期日. Work at home! 覆写toString()的目的是在输出时更有可读性。 注意:判断枚举常量的名字,要始终使用name()方法,绝不能调用toString()!
枚举:switch
枚举类可以应用在switch语句中。因为枚举类天生具有类型信息和有限个枚举常量,所以比int、String类型更适合用在switch语句中: // switch public class Main { public static void main(String[] args) { Weekday day = Weekday.SUN; switch(day) { case MON: case TUE: case WED: case THU: case FRI: System.out.println("Today is " + day + ". Work at office!"); break; case SAT: case SUN: System.out.println("Today is " + day + ". Work at home!"); break; default: throw new RuntimeException("cannot process " + day); } } } enum Weekday { MON, TUE, WED, THU, FRI, SAT, SUN; } 上述代码的运行结果如下: Today is SUN. Work at home! 加上default语句,可以在漏写某个枚举常量时自动报错,从而及时发现错误。
记录类
record关键字
使用String、Integer等类型的时候,这些类型都是不变类,一个不变类具有以下特点: 定义class时使用final,无法派生子类; 每个字段使用final,保证创建实例后无法修改任何字段 从Java 14开始,引入了新的Record类。我们定义Record类时,使用关键字record。把上述Point类改写为Record类(不变类),代码如下: // Record public class Main { public static void main(String[] args) { Point p = new Point(123, 456); System.out.println(p.x()); System.out.println(p.y()); System.out.println(p); } } public record Point(int x, int y) {} 仔细观察Point的定义: public record Point(int x, int y) {} 把上述定义改写为class,相当于以下代码: public final class Point extends Record { private final int x; private final int y; public Point(int x, int y) { this.x = x; this.y = y; } public int x() { return this.x; } public int y() { return this.y; } public String toString() { return String.format("Point[x=%s, y=%s]", x, y); } public boolean equals(Object o) { ... } public int hashCode() { ... } } 除了用final修饰class以及每个字段外,编译器还自动为我们创建了构造方法,和字段名同名的方法,以及覆写toString()、equals()和hashCode()方法。换句话说,使用record关键字,可以一行写出一个不变类。和enum类似,我们自己不能直接从Record派生,只能通过record关键字由编译器实现继承。 构造方法 编译器默认按照record声明的变量顺序自动创建一个构造方法,并在方法内给字段赋值。那么问题来了,如果我们要检查参数,应该怎么办? 假设Point类的x、y不允许负数,我们就得给Point的构造方法加上检查逻辑: public record Point(int x, int y) { public Point { if (x < 0 || y < 0) { throw new IllegalArgumentException(); } } } 注意到方法public Point {...}被称为Compact Constructor,它的目的是让我们编写检查逻辑,编译器最终生成的构造方法如下: public final class Point extends Record { public Point(int x, int y) { // 这是我们编写的Compact Constructor: if (x < 0 || y < 0) { throw new IllegalArgumentException(); } // 这是编译器继续生成的赋值代码: this.x = x; this.y = y; } ... } 作为record的Point仍然可以添加静态方法。一种常用的静态方法是of()方法,用来创建Point: public record Point(int x, int y) { public static Point of() { return new Point(0, 0); } public static Point of(int x, int y) { return new Point(x, y); } } 这样我们可以写出更简洁的代码: var z = Point.of(); var p = Point.of(123, 456); 从Java 14开始,提供新的record关键字,可以非常方便地定义Data Class: 使用record定义的是不变类; 可以编写Compact Constructor对参数进行验证; 可以定义静态方法。
BigInteger
java.math.BigInteger就是用来表示任意大小的整数。BigInteger内部用一个int[]数组来模拟一个非常大的整数:
创建:BigInteger a = new BigInteger("1234567890")
运算:a.add(b) / a.subtract(b) / a.multiply(b) / a.mod(b) 等
对BigInteger做运算的时候,只能使用实例方法,例如,加法运算: BigInteger i1 = new BigInteger("1234567890"); BigInteger i2 = new BigInteger("12345678901234567890"); BigInteger sum = i1.add(i2); // 12345678902469135780
转换:比如longValueExact()
和long型整数运算比,BigInteger不会有范围限制,但缺点是速度比较慢。 也可以把BigInteger转换成long型: BigInteger i = new BigInteger("123456789000"); System.out.println(i.longValue()); // 123456789000 System.out.println(i.multiply(i).longValueExact()); // java.lang.ArithmeticException: BigInteger out of long range 使用longValueExact()方法时,如果超出了long型的范围,会抛出ArithmeticException。 BigInteger和Integer、Long一样,也是不可变类,并且也继承自Number类。因为Number定义了转换为基本类型的几个方法: 转换为byte:byteValue() 转换为short:shortValue() 转换为int:intValue() 转换为long:longValue() 转换为float:floatValue() 转换为double:doubleValue() 因此,通过上述方法,可以把BigInteger转换成基本类型。如果BigInteger表示的范围超过了基本类型的范围,转换时将丢失高位信息,即结果不一定是准确的。如果需要准确地转换成基本类型,可以使用intValueExact()、longValueExact()等方法,在转换时如果超出范围,将直接抛出ArithmeticException异常。
BigDecimal
BigDecimal可以表示一个任意大小且精度完全准确的浮点数,常用于财务计算; 比较BigDecimal的值是否相等,必须使用compareTo()而不能使用equals()。
创建:BigDecimal bd = new BigDecimal("123.4567")
小数位数:bd.scale() // 4,四位小数
去掉末尾零:bd.stripTrailingZeros()
通过BigDecimal的stripTrailingZeros()方法,可以将一个BigDecimal格式化为一个相等的,但去掉了末尾0的BigDecimal: BigDecimal d1 = new BigDecimal("123.4500"); BigDecimal d2 = d1.stripTrailingZeros(); System.out.println(d1.scale()); // 4 System.out.println(d2.scale()); // 2,因为去掉了00 BigDecimal d3 = new BigDecimal("1234500"); BigDecimal d4 = d3.stripTrailingZeros(); System.out.println(d3.scale()); // 0 System.out.println(d4.scale()); // -2 如果一个BigDecimal的scale()返回负数,例如,-2,表示这个数是个整数,并且末尾有2个0。
运算:bd.function(bd2)
对BigDecimal做加、减、乘时,精度不会丢失,但是做除法时,存在无法除尽的情况,这时,就必须指定精度以及如何进行截断: BigDecimal d1 = new BigDecimal("123.456"); BigDecimal d2 = new BigDecimal("23.456789"); BigDecimal d3 = d1.divide(d2, 10, RoundingMode.HALF_UP); // 保留10位小数并四舍五入 BigDecimal d4 = d1.divide(d2); // 报错:ArithmeticException,因为除不尽 还可以对BigDecimal做除法的同时求余数: import java.math.BigDecimal; public class Main { public static void main(String[] args) { BigDecimal n = new BigDecimal("12.345"); BigDecimal m = new BigDecimal("0.12"); BigDecimal[] dr = n.divideAndRemainder(m); System.out.println(dr[0]); // 102 System.out.println(dr[1]); // 0.105 } } 调用divideAndRemainder()方法时,返回的数组包含两个BigDecimal,分别是商和余数,其中商总是整数,余数不会大于除数。我们可以利用这个方法判断两个BigDecimal是否是整数倍数: BigDecimal n = new BigDecimal("12.75"); BigDecimal m = new BigDecimal("0.15"); BigDecimal[] dr = n.divideAndRemainder(m); if (dr[1].signum() == 0) { // n是m的整数倍 }
截断
可以对一个BigDecimal设置它的scale,如果精度比原始值低,那么按照指定的方法进行四舍五入或者直接截断: import java.math.BigDecimal; import java.math.RoundingMode; public class Main { public static void main(String[] args) { BigDecimal d1 = new BigDecimal("123.456789"); BigDecimal d2 = d1.setScale(4, RoundingMode.HALF_UP); // 四舍五入,123.4568 BigDecimal d3 = d1.setScale(4, RoundingMode.DOWN); // 直接截断,123.4567 System.out.println(d2); System.out.println(d3); } } 运行结果: 123.4568 123.4567
比较:bd.equals(bd2)
在比较两个BigDecimal的值是否相等时,要特别注意,使用equals()方法不但要求两个BigDecimal的值相等,还要求它们的scale()相等: BigDecimal d1 = new BigDecimal("123.456"); BigDecimal d2 = new BigDecimal("123.45600"); System.out.println(d1.equals(d2)); // false,因为scale不同 System.out.println(d1.equals(d2.stripTrailingZeros())); // true,因为d2去除尾部0后scale变为2 System.out.println(d1.compareTo(d2)); // 0 必须使用compareTo()方法来比较,它根据两个值的大小分别返回负数、正数和0,分别表示小于、大于和等于。
常用工具类
数学计算:Math
Math类就是用来进行数学计算的,它提供了大量的静态方法来便于我们实现数学计算: 求绝对值: Math.abs(-100); // 100 Math.abs(-7.8); // 7.8 取最大或最小值: Math.max(100, 99); // 100 Math.min(1.2, 2.3); // 1.2 计算xy次方: Math.pow(2, 10); // 2的10次方=1024 计算√x: Math.sqrt(2); // 1.414... 计算ex次方: Math.exp(2); // 7.389... 计算以e为底的对数: Math.log(4); // 1.386... 计算以10为底的对数: Math.log10(100); // 2 三角函数: Math.sin(3.14); // 0.00159... Math.cos(3.14); // -0.9999... Math.tan(3.14); // -0.0015... Math.asin(1.0); // 1.57079... Math.acos(1.0); // 0.0 Math还提供了几个数学常量: double pi = Math.PI; // 3.14159... double e = Math.E; // 2.7182818... Math.sin(Math.PI / 6); // sin(π/6) = 0.5 生成一个随机数x,x的范围是0 <= x < 1: Math.random(); // 0.53907... 每次都不一样 如果我们要生成一个区间在[MIN, MAX)的随机数,可以借助Math.random()实现,计算如下: // 区间在[MIN, MAX)的随机数 public class Main { public static void main(String[] args) { double x = Math.random(); // x的范围是[0,1) double min = 10; double max = 50; double y = x * (max - min) + min; // y的范围是[10,50) long n = (long) y; // n的范围是[10,50)的整数 System.out.println(y); System.out.println(n); } } 有些童鞋可能注意到Java标准库还提供了一个StrictMath,它提供了和Math几乎一模一样的方法。这两个类的区别在于,由于浮点数计算存在误差,不同的平台(例如x86和ARM)计算的结果可能不一致(指误差不同),因此,StrictMath保证所有平台计算结果都是完全相同的,而Math会尽量针对平台优化计算速度,所以,绝大多数情况下,使用Math就足够了。
生成伪造随机数:Random
Random用来创建伪随机数。所谓伪随机数,是指只要给定一个初始的种子,产生的随机数序列是完全一样的。 要生成一个随机数,可以使用nextInt()、nextLong()、nextFloat()、nextDouble(): Random r = new Random(); r.nextInt(); // 2071575453,每次都不一样 r.nextInt(10); // 5,生成一个[0,10)之间的int r.nextLong(); // 8811649292570369305,每次都不一样 r.nextFloat(); // 0.54335...生成一个[0,1)之间的float r.nextDouble(); // 0.3716...生成一个[0,1)之间的double
生成安全随机数:SecureRandom
SecureRandom就是用来创建安全的随机数的: SecureRandom sr = new SecureRandom(); System.out.println(sr.nextInt(100)); SecureRandom无法指定种子,它使用RNG(random number generator)算法。JDK的SecureRandom实际上有多种不同的底层实现,有的使用安全随机种子加上伪随机数算法来产生安全的随机数,有的使用真正的随机数生成器。实际使用的时候,可以优先获取高强度的安全随机数生成器,如果没有提供,再使用普通等级的安全随机数生成器: import java.util.Arrays; import java.security.SecureRandom; import java.security.NoSuchAlgorithmException; public class Main { public static void main(String[] args) { SecureRandom sr = null; try { sr = SecureRandom.getInstanceStrong(); // 获取高强度安全随机数生成器 } catch (NoSuchAlgorithmException e) { sr = new SecureRandom(); // 获取普通的安全随机数生成器 } byte[] buffer = new byte[16]; sr.nextBytes(buffer); // 用安全随机数填充buffer System.out.println(Arrays.toString(buffer)); } } 运行结果(每次不一样): [-97, -98, -13, -102, -4, 119, 37, -100, 114, -15, -122, -56, 22, 5, 70, -68] SecureRandom的安全性是通过操作系统提供的安全的随机种子来生成随机数。这个种子是通过CPU的热噪声、读写磁盘的字节、网络流量等各种随机事件产生的“熵”。 在密码学中,安全的随机数非常重要。如果使用不安全的伪随机数,所有加密体系都将被攻破。因此,时刻牢记必须使用SecureRandom来产生安全的随机数。 需要使用安全随机数的时候,必须使用SecureRandom,绝不能使用Random!
反射
这种通过Class实例获取class信息的方法称为反射(Reflection)。Class类型是一个名叫Class的class,每加载一种类(或者接口),JVM就为其创建一个Class类型的实例,并关联起来。
Class类
除了int等基本类型外,Java的其他类型全部都是class(包括interface)。例如: String Object Runnable Exception ... 仔细思考,我们可以得出结论:class(包括interface)的本质是数据类型(Type)。无继承关系的数据类型无法赋值: Number n = new Double(123.456); // OK String s = new Double(123.456); // compile error! 而class是由JVM在执行过程中动态加载的。JVM在第一次读取到一种class类型时,将其加载进内存。 每加载一种class,JVM就为其创建一个Class类型的实例,并关联起来。注意:这里的Class类型是一个名叫Class的class。它长这样: public final class Class { private Class() {} } 以String类为例,当JVM加载String类时,它首先读取String.class文件到内存,然后,为String类创建一个Class实例并关联起来: Class cls = new Class(String); 这个Class实例是JVM内部创建的,如果我们查看JDK源码,可以发现Class类的构造方法是private,只有JVM能创建Class实例,我们自己的Java程序是无法创建Class实例的。 所以,JVM持有的每个Class实例都指向一个数据类型(class或interface)。 一个Class实例包含了该class的所有完整信息: ┌───────────────────────────┐ │ Class Instance │──────> String ├───────────────────────────┤ │name = "java.lang.String" │ ├───────────────────────────┤ │package = "java.lang" │ ├───────────────────────────┤ │super = "java.lang.Object" │ ├───────────────────────────┤ │interface = CharSequence...│ ├───────────────────────────┤ │field = value[],hash,... │ ├───────────────────────────┤ │method = indexOf()... │ └───────────────────────────┘ 由于JVM为每个加载的class创建了对应的Class实例,并在实例中保存了该class的所有信息,包括类名、包名、父类、实现的接口、所有方法、字段等,因此,如果获取了某个Class实例,我们就可以通过这个Class实例获取到该实例对应的class的所有信息。
获取一个class的Class实例有三种方法
直接通过一个class的静态变量class获取:Class cls = String.class
如果有一个实例变量,可以通过该实例变量提供的getClass()方法获取:String s = "Hello";Class cls = s.getClass();
如果知道一个class的完整类名,可以通过静态方法Class.forName()获取: Class cls = Class.forName("java.lang.String");
Class 实例比较与instanceof比较
因为Class实例在JVM中是唯一的,所以,上述方法获取的Class实例是同一个实例。可以用==比较两个Class实例: Class cls1 = String.class; String s = "Hello"; Class cls2 = s.getClass(); boolean sameClass = cls1 == cls2; // true 注意一下Class实例比较和instanceof的差别: Integer n = new Integer(123); boolean b1 = n instanceof Integer; // true,因为n是Integer类型 boolean b2 = n instanceof Number; // true,因为n是Number类型的子类 boolean b3 = n.getClass() == Integer.class; // true,因为n.getClass()返回Integer.class boolean b4 = n.getClass() == Number.class; // false,因为Integer.class!=Number.class 用instanceof不但匹配指定类型,还匹配指定类型的子类。而用==判断class实例可以精确地判断数据类型,但不能作子类型比较。 通常情况下,我们应该用instanceof判断数据类型,因为面向抽象编程的时候,我们不关心具体的子类型。只有在需要精确判断一个类型是不是某个class的时候,我们才使用==判断class实例。
通过反射获取该Object的class信息
因为反射的目的是为了获得某个实例的信息。因此,当我们拿到某个Object实例时,我们可以通过反射获取该Object的class信息: void printObjectInfo(Object obj) { Class cls = obj.getClass(); } 要从Class实例获取获取的基本信息,参考下面的代码: // reflection public class Main { public static void main(String[] args) { printClassInfo("".getClass()); printClassInfo(Runnable.class); printClassInfo(java.time.Month.class); printClassInfo(String[].class); printClassInfo(int.class); } static void printClassInfo(Class cls) { System.out.println("Class name: " + cls.getName()); System.out.println("Simple name: " + cls.getSimpleName()); if (cls.getPackage() != null) { System.out.println("Package name: " + cls.getPackage().getName()); } System.out.println("is interface: " + cls.isInterface()); System.out.println("is enum: " + cls.isEnum()); System.out.println("is array: " + cls.isArray()); System.out.println("is primitive: " + cls.isPrimitive()); } } 注意到数组(例如String[])也是一种Class,而且不同于String.class,它的类名是[Ljava.lang.String。此外,JVM为每一种基本类型如int也创建了Class,通过int.class访问。
通过Class实例来创建对应类型的实例
果获取到了一个Class实例,我们就可以通过该Class实例来创建对应类型的实例: // 获取String的Class实例: Class cls = String.class; // 创建一个String实例: String s = (String) cls.newInstance(); 上述代码相当于new String()。通过Class.newInstance()可以创建类实例,它的局限是:只能调用public的无参数构造方法。带参数的构造方法,或者非public的构造方法都无法通过Class.newInstance()被调用。
VM动态加载class的特性:为了在运行期根据条件加载不同的实现类。
动态加载 JVM在执行Java程序的时候,并不是一次性把所有用到的class全部加载到内存,而是第一次需要用到class时才加载。例如: // Main.java public class Main { public static void main(String[] args) { if (args.length > 0) { create(args[0]); } } static void create(String name) { Person p = new Person(name); } } 当执行Main.java时,由于用到了Main,因此,JVM首先会把Main.class加载到内存。然而,并不会加载Person.class,除非程序执行到create()方法,JVM发现需要加载Person类时,才会首次加载Person.class。如果没有执行create()方法,那么Person.class根本就不会被加载。 这就是JVM动态加载class的特性。 动态加载class的特性对于Java程序非常重要。利用JVM动态加载class的特性,我们才能在运行期根据条件加载不同的实现类。例如,Commons Logging总是优先使用Log4j,只有当Log4j不存在时,才使用JDK的logging。利用JVM动态加载特性,大致的实现代码如下: // Commons Logging优先使用Log4j: LogFactory factory = null; if (isClassPresent("org.apache.logging.log4j.Logger")) { factory = createLog4j(); } else { factory = createJdkLog(); } boolean isClassPresent(String name) { try { Class.forName(name); return true; } catch (Exception e) { return false; } } 这就是为什么我们只需要把Log4j的jar包放到classpath中,Commons Logging就会自动使用Log4j的原因。
可以实现动态装配
降低代码的耦合度
动态代理
JDK 中 java.lang.Class 类,就是为了实现反射提供的核心类之一
动态代理
在运行时,创建目标类,可以调用和扩展目标类的方法。
JDK 动态代理
实现 InvocationHandler 接口
重写 invoke 方法,添加业务逻辑
持有目标类对象
提供静态方法获取代理
CGLib 动态代理
使用了ASM(字节码操作框架)来操作字节码生成新的类
java 序列化
序列化:将 Java 对象转换成字节流的过程
反序列化:将字节流转换成 Java 对象的过程
Java异常
throwable类
Error类
一般是指与虚拟机相关的问题
这类错误的导致的中断,仅靠程序本身无法恢复,遇到这样的错误,建议让程序终止
NoClassDefFoundError
发生在JVM在动态运行时,根据你提供的类名,在classpath中找不到对应的类进行加载
Exception类
表示程序可以处理的异常,可以捕获且可能恢复
遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常
Unchecked Exception
指的是程序的瑕疵或逻辑错误,并且在运行时无法恢复
RuntimeException
NullPointerException/空指针异常
在为空的对象中调用方法就会出现NullPointerException
IndexOutOfBoundsException 数组下标越界异常
NegativeArraySizeException 负数组长度异常
ArithmeticException 数学计算异常
ClassCastException 类型强制转换异常
SecurityException 违背安全原则异常
Checked Exception
代表程序不能直接控制的无效外界情况
ClassNotFoundException
编译的时候在classpath中找不到对应的类而发生的错误
NoSuchMethodException 方法未找到异常
IOException 输入输出异常
NumberFormatException 字符串转换为数字异常
EOFException 文件已结束异常
FileNotFoundException 文件未找到异常
SQLException 操作数据库异常
Throws
作用在方法的声明上,表示如果抛出异常,则由该方法的调用者来进行异常处理
方法会抛出会抛出某种类型的异常,让它的使用者知道捕获异常的类型
出现异常是一种可能性,但不一定会发生异常
Throw
真实抛出一个异常
try-catch-finally
catch 和 finally 都可以被省略,但是不能同时省略
finally 一定会执行,atch 中的 return 会等 finally 中的代码执行完之后,才会执行
JavaEE基础
分层模型
经典三层
web层
Servlet/JSP
业务逻辑层(BLL)
EJB
持久层
JDBC、MyBatis、Hibernate
四层模型
表现层(PL)
服务层(Service)
业务逻辑层(BLL)
数据访问层(DAL)
五层模型
Domain Object(领域对象)层
DAO(数据访问层)
业务逻辑层
MVC控制层
表现层
分层应用
JPA(Java持久化API)
JPA实现
JMS(Java信息服务)
JCA(JavaEE连接器架构)
Managed beans、EJB
CDI(安全依赖注入)
Web层
Servlets、JSP
Web Services
Java IO/NIO
IO
流式
字节流
InputStream
PipedInputStream
ByteArrayInputStream
FileInputStream
FileterInputStream
BufferedInputStream
DataInputStream
PushBackInputStream
StringBufferInputStream
SequenceInputStream
ObjectInputStream
OutputStream
ObjectOutputStream
PipedOutputStream
FileterOutputStream
BufferedOutputStream
DataOutputStream
PrintStream
FileOutputStream
ByteArrayOutputStream
字符流
Writer
FilterWriter
StringWriter
PipedWriter
OutputStreamWriter
FileWriter
CharArrayWriter
BufferedWriter
PrintWriter
Reader
BufferedReader
LineNumberReader
CharArrayReader
InputStreamReader
FileReader
PipedReader
StringReader
FilterReader
非流式
file
其他
SerializablePermission
FileSystem
字符编码
ASCII,美国信息交换标准代码
拉丁码,ISO8859-1
中文码,GB2312/GBK/GBK18030
国际标准码,Unicode
UTF-8,UTF-16,根据Unicode可变长度编码
IO模型
BIO (Blocking I/O): 同步阻塞I/O模式
BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO (New I/O): 同步非阻塞的I/O模型
NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
Channel双向通道
Buffer缓冲
Selector选择器
多路复用
select
原理图
缺点: 1)能够监视文件描述符的数量存在最大限制 (1024) 2)线性扫描效率低下
poll
epoll
每当FD就绪,采用系统的回调函数直接将fd放入,效率更高 无最大连接数的限制
AIO (Asynchronous I/O):异步非阻塞的IO模型
AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
信号驱动IO模型
异步IO模型
伪异步IO模型
形参和实参
出现在函数定义中的参数,就叫形参 出现在函数调用中的参数,就叫实参
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参
在一般传值调用的机制中只能把实参传送给形参,而不能把形参的值反向地传送给实参。因此在函数调用过程中,形参值发生改变,而实参中的值不会变化。而在引用调用的机制当中是将实参引用的地址传递给了形参,所以任何发生在形参上的改变实际上也发生在实参变量上。
Java Web基础
Servet+JDBC应用(3.1)
db.properties文件(属性文件)
.properties文件内容: #驱动地址 driverClassName=oracle.jdbc.OracleDriver #连接地址 url=jdbc:oracle:thin:@localhost:1521/XE #帐号 username=system/litao #密码 password=123456 #选填的 #初始化的连接池 连接数量 initialaSize=5 #最大的连接数量 maxActive=100 #空闲时保留的 最大连接数量 maxIdle=10 #空闲时保留的 最小连接数量 minIdle=5 #超时时间 maxWait=10000
导入3个包
编写连接池工具类
DbcpUtil
com.xdl.util包
完成一个银行账户登录的功能
在数据库中建立一张银行账户表
创建一个init.sql
/** 建立一张银行账户表 建立之前先删除 */ drop table xdl_bank_account cascade constraint; create table xdl_bank_account( id number constraint xdl_bank_account_id_pk primary key, acc_no varchar(30) constraint xdl_bank_account_acc_no_uk unique, acc_password varchar(30), acc_money number ); /** 为这张表 建立一个序列 建立之前先删除 */ drop sequence xdl_bank_account_id_seq; create sequence xdl_bank_account_id_seq; /** 插入测试数据 */ insert into xdl_bank_account values(xdl_bank_account_id_seq.nextval, 'malaoshi','17',10000000); commit;
建立一个项目 根据表建立实体类(说白就是封装)
命名格式:去掉表名下划线首字母大写 变量名与表内一致 构造,get set,tostring,序列化 implements Serializable
com.xdl.bean包
定义DAO 接口 方法的设计
命名格式:实体类后面加DAO 只做增删改查其中一件事
com.xdl.Dao
根据DAO 接口 结合 DbcpUtil 和 JDBC编程五步完成DAO实现类
命名格式:实体类+dao+数据库名+imp 连接数据库代码 1.加载驱动 2.获取连接 3.定义sql 并获取sql的预编译环境 设置参数 setXX 4. 执行SQL 处理sql的返回值 select/ 遍历结果集 5.释放资源
com.xdl.dao.imp
编写业务逻辑类 Service 封装业务方法
命名格式:实体类后面加+功能+Service 1.持有一个DAO 2.给Dao 赋值 3.封装一个业务方法(return接口.方法)
com.xdl.service
测试类
com.xdl.test
编写一个 html 页面 发出 登录请求
编写一个Servlet 用来接收用户请求参数 根据参数调用Service中的方法看是否登录成功 成功 输出 login success 否则 login failed
命名格式:实体类后面加Servlet 0.编码 1.请求参数获取 2.用service进行判断 3.把参数封装成对象 4.写入浏览器,获取一个向浏览器输出对象
com.xdl.servlet
状态管理
为什么要有状态管理
因为 http 协议是无状态的 当请求响应之后这个请求就和服务器之间断开连接了,上一次请求 和以后的数据变量就没关系了。但是有时要获取上一次请求的数据状态 比如 购物 购买商品 时需要之前上一次 以及前几次购买的商品数据。
状态管理技术的实现方式
基于客户端的状态的管理技术
Cookie
原理
当浏览器 请求服务器上一个服务器时,服务器会创建好一个Cookie 对象 然后以setCookie 消息头的方式传递给浏览器。当浏览器再次请求服务器上服务时 会携带这个Cookie对象 到服务端。服务端就可以获知上一次的数据状态。
如何实现?
创建一个Cookie对象 Cookie cookie=new Cookie("key","value");
如何写给客户端 response.addCookie(cookie);
概要
如何获取请求中对应的Cookie Cookie [] cookies =request.getCookies();
获取Cookie的名字和值 getName() getValue() 设置值 setValue("字符串值")
概要
Cookie的生命期问题
默认和浏览器生命期相同 关闭浏览器则消失 值是 -1
setMaxAge(int seconds); (秒)
Cookie 到期之后 浏览器就不再携带 (如何设置三个月的生命期呢? setMaxAge(60*60*24*93);) 把生命期设置成 0 代表立即删除 Cookie
Cookie 的 路径问题
Cookie 默认所在的路径 是servlet 所在的路径。
Cookie 携带的规则是 会携带本路径下的Cookie 以及本路径对应的父路径下的Cookie
可以通过 setPath("/路径") 来修改Cookie 默认的路径
如:setPath("/servlet-day04") 则代表Cookie 放入项目下 这个项目的所有针对这个项目请求都将携带这个Cookie.
如果 把path 写成 / 代表什么意思? 代表针对所有的请求
基于服务端的状态管理技术
Session
基础知识
请求参数
请求参数的中文乱码问题
tomcat8:get方式没有乱码问题
tomcat8:post方式乱码问题
post提交时是以utf-8进行数据提交但,tomcat解码时默认按照ISO-8859-1进行解码
HttpServletRequest 这个类型的对象提供了对应的API对tomcat 可以设置解码的编码
request.setCharacterEncoding("utf-8")
告诉tomcat以utf-8解码
必须出现在获取参数之前
这种只针对post方式
acc_no=new String (acc_no.getbytes("iso-8859-1"),"utf-8");
先按照ISO-8859-1解码,再按照utf-8编码
这是通用的解决方式
适用于 tomcat7的get post 还有 tomcat8 post
请求参数的获取
String中请求参数获取 String data= request.getParameter("name") 根据name获取对应的请求参数 对应单值
String [] datas=request.getParameterValues("name"); 根据name 获取对应的请求参数 对应的值的数组
HttpServletRequest 获取请求头信息的API
getMethod()
获取请求方式
getServletPath();
获取servlet的请求路径 等同于url-pattiern
getContextPath()
/项目名
getServerPort()
端口号
getServerName()
主机名
getRemoteAddr()
获取远程客户端地址
getLocalAddr()
获取服务器地址
getRequestURL()
统一资源定位
http://localhost:8888/Web02/Zhuce
协议 主机 端口 项目 请求
getRequestURI()
统一资源标识
/Web02/Zhuce
项目 请求
转发与重定向
区别
HttpServletResponse 接口中的 sendRedirect() 方法用于实现重定向
大数据、云计算及其他扩展
运维与集成
持续集成(CI/CD)
版本管理工具(SCM)
Git
SVN
仓库管理
GitLab
Maven 仓库管理器
Apache Archiva
JFrog Artifactory
Sonatype Nexus
构建工具
Maven
Ant
Gradle
代码检测
SonarQube
自动化发布
Jenkins
测试
分布式测试
全链路压测
集成测试
加密算法
AES
高级加密标准(AES,Advanced Encryption Standard)为最常见的对称加密算法
对称加密算法也就是加密和解密用相同的密钥
RSA
RSA 加密算法是一种典型的非对称加密算法,它基于大数的因式分解数学难题,它也是应用最广泛的非对称加密算法。
非对称加密是通过两个密钥(公钥-私钥)来实现对数据的加密和解密的。
公钥用于加密,私钥用于解密。
CRC
循环冗余校验(Cyclic Redundancy Check, CRC)是一种根据网络数据包或电脑文件等数据产生简短固定位数校验码的一种散列函数,主要用来检测或校验数据传输或者保存后可能出现的错误。
它是利用除法及余数的原理来作错误侦测的。
MD5
MD5 常常作为文件的签名出现,我们在下载文件的时候,常常会看到文件页面上附带一个扩展名为.MD5 的文本或者一行字符,这行字符就是就是把整个文件当作原数据通过 MD5 计算后的值,我们下载文件后,可以用检查文件 MD5 信息的软件对下载到的文件在进行一次计算。
两次结果对比就可以确保下载到文件的准确性。
另一种常见用途就是网站敏感信息加密,比如用户名密码,支付签名等等。
随着 https 技术的普及,现在的网站广泛采用前台明文传输到后台,MD5 加密(使用偏移量)的方式保护敏感数据保护站点和数据安全。
新技术
区块链技术(Java版)
区块链应用
比特币
以太坊
超级账本
大数据技术
大数据
Hadoop
MapReduce
Hadoop MapReduce 作业的生命周期
Client
JobTracker
TaskTracker
Task
执行过程
1.从远程节点上读取 MapTask 中间结果(称为 “Shuffle 阶段”);
2.按照key 对key/alue 对进行排序(称为“Sort阶段”);
3. 依次读取<key, value list>,调用用户自定义的 reduce0 函数处理,并将最终结果存到 HDFS上
HDFS
Client
NameNode
Secondary NameNode
DataNode
hadoop2.0 以后引入 yarn
HBase
Spark
核心架构
Spark Core
Spark SQL
Spark Streaming
MIlib
GraphX
核心组件
Cluster Manager-制整个集群,监控worker
Worker节点-负责控制计算节点
Driver:运行Application 的main()函数
Executor
执行器,
是为某个Application 运行在 worker node 上的一个进程
SPARK 编程模型
1.用户使用 SparkContext提供的 API(常用的有 textFile、 sequenceFile、 runJob、 stop 等)编写 Driver application 程序。此外 SQLContext、 HiveContext 及 Streaming Context 对SparkContext进行封装,并提供了 SQL、 Hive 及流式计算相关的APl。
2. 使用SparkContext提交的用户应用程序,首先会使用 BlockManager和 BroadcastManager将任务的 Hadoop 配置进行广播。然后由 DAGScheduler 将任务转换为 RDD 并组织成 DAG,DAG 还将被划分为不同的 Stage。最后由 TaskScheduler 借助 ActorSystem 将任务提交给集群管理器(Cluster Manager)。
3. 集群管理器 (ClusterManager)给任务分配资源,即将具体任务分配到Worker上,Worker创建 Executor 来处理任务的运行。Standalone、 YARN、 Mesos、 EC2 等都可以作为 Spark的集群管理器。
SPARK 计算模型
SPARK运行流程
1.构建 Spark Application 的运行环统,启动 SparkContext
2.SparkContext 向资源管理器(可以是 Standalone, Mesos, Yarn)申请运行 Executor 资源,并启动 StandaloneExecutorbackend,
3.Executor 向 SparkContext 中请 Task
4.SparkContext 将应用程序分发给 Executor
5.SparkContext 构建成DAG 图,将DAG 图分解成 Stage、将 Taskset 发送给 Task Scheduler,最后由 Task Scheduler 将 Task 发送给 Executor 运行
6.Task 在Executor 上运行,运行完摩放所有资源
SPARK RDD流程
1. 创建 RDD 对象
2.DAGScheduler 模块介入运算,计算 RDD 之间的依赖关系,RDD 之间的依赖关系就形成了DAG
3. 每一个 Job 被分内多个 Stage。划分 Stage 的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个 Stage,避免多个 Stage 之间的消息传递开销
Hive
大数据搜索
[搜索引擎选择: Elasticsearch与Solr](http://www.cnblogs.com/chowmin/articles/4629220.html)
Lucene
ElasticSearch
特点
基于Lucene基本架构
java搜索界的鼻祖
实时搜索性能高
正则、substring、内存数据库
构件
Document行(Row)文本
Index索引(数据关键值)
Analyzer分词器(打标签)
Solr
特点
不能用于实时搜索
Nutch
yarn
ResourceManager
1.ResourceManager 负责整个集群的资源管理和分配,是一个全局的资源管理系统。
2.NodeManager 以心跳的方式向 ResourceManager 汇报资源使用情况(目前主要是 CPU 和内存的使用情况)。RM 只接受 NM 的资源回报信息,对于具体的资源处理则交给 NM 自己处理。
3. YARN Scheduler 根据 application 的请求为其分配资源,不负责 application job 的监控、追踪、运行状态反馈、启动等工作。
NodeManager
1.NodeManager 是每个节点上的资源和任务管理器,它是管理这台机器的代理,负责该节点程序的运行,以及该节点资源的管理和监控。YARN集群每个节点都运行一个 NodeManager。
2.NodeManager 定时向 ResourceManager 汇报本节点资源(CPU、内存)的使用情况和Container 的运行状态。当 ResourceManager 宕机时 NodeManager 自动连接 RM 备用节点。
3.NodeManager 接收并处理来自 ApplicationMaster 的 Container 启动、停止等各种请求。
ApplicationMaster
1.负责与RM 调度器协商以获取资源(用 Container 表示)。
2. 将得到的任务进一步分配给内部的任务(资源的二次分配)。
3. 与NM通信以启动/停止任务。
4.监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
5.当前 YARN 自带了两个 ApplicationMaster 实现,一个是用于演示 AM 编写方法的实例程序DistributedShell,它可以申请一定数目的 Container 以并行运行一个 Shell 命令或者 Shell脚本;另—个是运行 MapReduce 应用程序的 AM—MRAppMaster。
人工智能技术
神经网络
机器学习
深度学习
常用框架
DL4J
Deeplearning4j- 使用java和Scala编写的深度学习库- 支持GPU
机器学习算法
决策树
随机森林算法
逻辑回归
SVM
朴素贝叶斯
K最近邻算法
K均值算法
Adaboost 算法
马尔可夫
数学基础
应用场景
云计算
虚拟机
JRockit VM
HotSpot VM
云原生
kubernetes
Docker
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程 API 来管理和创建 Docker 容器。
Docker 容器通过Docker 镜像来创建。
Docker的四种网络模式
Host
Container
None
Bridge 模式
Docker支持的存储驱动
AUFS
devicemapper
overlay2
zfs
vfs
云架构分类
公有云
购买/解决方案 -上层
庞大计算资源
A公司 搭建云计算环境---->B/C/D公司
国外:aws / google / azure
国内:aliyun/ Tencent cloud / Huaweicloud / jinshan cloud
私有云
部署搭建- 底层
私密数据/重要数据
A公司 搭建- A公司使用
国外:vmware vicoud
国内:华为 DevCloud/华三 cloud
混合云:公有云+私有云
云计算的商业模式
SaaS
通过提供满足最终用户需求的业务,按使用收费
互联网应用
举例
Salesforce
华为云:WeLink
PaaS
提供应用运行和开发环境
提供应用开发的组件(如:数据库)
举例
Microsoft:Azure的Visio Studio工具
华为云:Devcloud软件开发云
laaS
出租计算,存储,网络等IT资源
按使用收费
举例
Amazon EC2云主机
华为云:ECS
Openstack
LoT
Java集合
集合框架
框架结构图
Collection
List
元素可重复性,有序性 String的长度限制: 底层是char 数组 长度 Integer.MAX_VALUE 线程安全的
ArrayList
排列有序,可重复
底层使用数组
getter()和setter()方法快,增删慢
线程不安全
当容量不足时,ArrayList是当前容量*1.5+1
CopyOnWriteArrayList
写数组的拷贝,支持高效率并发且是线程安全的
读操作无锁的ArrayList
适合使用在读操作远远大于写操作的场景里,比如缓存
不存在扩容的概念,每次写操作都要复制一个副本,因而写操作性能差
实现了List, RandomAccess, Cloneable, java.io.Serializable等接口
add/remove等写方法是需要加锁的,目的是为了避免Copy出N个副本出来,导致并发写
LinkedList
排列有序,可重复
底层使用双向循环链表数据结构
查询速度快,增删快,add()和remove()速度快
线程不安全
Vector
排列有序,可重复
底层使用数组
速度快,增删慢
线程安全,效率低
当容量不够时,Vector默认扩展一倍容量
Stack
底层也是数组,继承自Vector
先进后出,默认容量是10
应用:计算后缀表达式
Set
具有唯一性,无序性
HashSet
排列无序,不可重复
底层使用Hash表实现,内部是HashMap
存取速度快
TreeSet
排列无序,不可重复
底层使用二叉树实现
排序存储,内部是TreeMap和SortedSet
LinkedHashSet
采用Hash表存储,使用双向链表记录插入数据
继承自HashSet,内部是LinkedHashMap
Queue
在两端处入的List,也可以用数组或链表来实现
DelayQueue
是java并发包下的延时阻塞队列,常用于实现定时任务
DelayQueue实现了BlockingQueue
主要使用优先级队列来实现,并辅以重入锁和条件来控制并发安全
PriorityQueue
是一个小顶堆,非线程安全
不是有序的,只有堆顶存储着最小的元素
PriorityBlockingQueue
是java并发包下的优先级阻塞队列,它是线程安全的
ArrayDeque(双端队列)
是一种特殊的队列,它的两端都可以进出元素,故而得名双端队列
是一种以数组方式实现的双端队列,它是非线程安全的
ArrayDeque实现了Deque接口,Deque接口继承自Queue接口
可以直接作为栈使用,出队入队是通过头尾指针循环利用数组实现的
容量不足时是会扩容的,每次扩容容量增加一倍
Map
采用键值对<key,value>存储元素,key键唯一
HashMap
键不可重复,值可重复
底层哈希表,内部数组+单链表
jdk8中引入了红黑树对长度 > 8的链表进行转换
允许Key值为null,value也可以为null
利用哈希算法根据hashCode()配置存储地址
线程不安全
写入操作丢失
修改覆盖
HashTable(哈希表/散列表)
键不可重复,值可重复
底层哈希表
线程安全
Key、value都不许为null
LinkedHashMap
基于HashMap和双向链表/红黑树实现的
有序
插入顺序
插入的是什么顺序,读出来的就是什么顺序
访问顺序
访问了一个key,这个key就跑到了最后面
WeakHashMap
ConcurrentHashMap
高效且线程安全
Key、value都不许为null
TreeMap
键不可重复,值可重复
Key值是要求实现java.lang.Comparable
迭代的时候TreeMap默认是按照Key值升序排序
基于红黑树的NavigableMap 实现
红黑树属于平衡二叉树
平均高度log(n),最坏情况高度不会超过2log(n)
红黑树能够以O(log2(N))的时间复杂度进行搜索、插入、删除操作
任何不平衡都会在3次旋转之内解决
SortedMap接口
键的总体排序 的 Map
Properties
HashTable子类,只能操作String类型
Stream
Stream基本操作
MapReduce
分布式计算模型,主要用于搜索领域
泛型擦除
泛型,即“参数化类型”。 创建集合时就指定集合元素的类型,该集合只能保存其指定类型的元素,避免使用强制类型转换。 Java编译器生成的字节码是不包涵泛型信息的,泛型类型信息将在编译处理是被擦除,这个过程即类型擦除。泛型擦除可以简单的理解为将泛型java代码转换为普通java代码,只不过编译器更直接点,将泛型java代码直接转换成普通java字节码。 类型擦除的主要过程如下: 1).将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。 2).移除所有的类型参数。
泛型和 Object 的区别
泛型声明
public <T> T doSomeThing(T t){return t; }
泛型引用
不再需要强制转换,编译时自动检查类型安全,避免隐性的类型转换异常
Object声明
public Object doSomeThing(Object obj){ return obj; }
Object引用
可能发生类型转换异常(ClassCastException)
区别与类比
HashMap, HashSet, HashTable的区别
*HashMap**HashSet*HashMap实现了Map接口HashSet实现了Set接口HashMap储存键值对HashSet仅仅存储对象使用put()方法将元素放入map中使用add()方法将元素放入set中HashMap中使用键对象来计算hashcode值HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回falseHashMap比较快,因为是使用唯一的键来获取对象HashSet较HashMap来说比较慢
HashSet
HashSet实现了Set接口,它不允许集合中有重复的值,当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象。如果我们没有重写这两个方法,将会使用这个方法的默认实现。 public boolean add(Object o)方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true。
HashMap
HashMap实现了Map接口,Map接口对键值对进行映射。Map中不允许重复的键。Map接口有两个基本的实现,HashMap和TreeMap。TreeMap保存了对象的排列次序,而HashMap则不能。HashMap允许键和值为null。HashMap是非synchronized的,但collection框架提供方法能保证HashMap synchronized,这样多个线程同时访问HashMap时,能保证只有一个线程更改Map。 HashMap在底层数据结构上采用了数组+链表+红黑树,通过散列映射来存储键值对数据因为在查询上使用散列码(通过键生成一个数字作为数组下标,这个数字就是hash code)所以在查询上的访问速度比较快,HashMap最多允许一对键值对的Key为Null,允许多对键值对的value为Null。它是非线程安全的。在排序上面是无序的。 在jdk1.7中的HashMap是位桶+链表实现在jdk1.8中的HashMap是位桶+链表+红黑树实现未超过8个节点时,是位桶+链表实现,在节点数超过8个节点时,是位桶+红黑树实现。
哈希冲突
链地址法
链表
JDK1.7
位桶+链表
JDK1.8
位桶+链表+红黑树
未超过8个节点时,是位桶+链表实现,在节点数超过8个节点时,是位桶+红黑树实现。
HashTable
ConcurrentHashMap
ConcurrentHashMap是基于segment数组内嵌哈希表的ConcurrentMap接口实现,线程安全。 ConcurrentHashMap的数据结构(数组+链表+红黑树),桶中的结构可能是链表,也可能是红黑树,红黑树是为了提高查找效率。 ConcurrentHashMap的主要实现原理就是使用segments将原本唯一的hashtable分段, 增加并发能力。 ConcurrentHashMap使用两次哈希算法(single-word Wang/Jenkins哈希算法的一个变种)尽量将元素均匀的分布到不同的segment的hashtable中:第一次哈希算法找到segment;第二次哈希算法找到hashentry;这两次哈希算法要求能尽量将元素均匀的分布到不同的segment的hashtable中, ConcurrentHashMap使用的是single-word Wang/Jenkins哈希算法的一个变种
HashMap、 LinkedHashMap、 TreeMap的区别
HashMap
数组+链表/红黑树
取值无顺序
最多一条记录的key为null
绝大多数无需排序的情况
LinkedHashMap
数组+链表/红黑树
取值按插入的顺序/按修改的顺序,根据accessOrder控制
最多一条记录的key为null
需要插入的顺序和取出的顺序一样的情况
TreeMap
红黑树
插入时按key的自然顺序或者自定义顺序
当为key的自然顺序存储时key不能为null
需要按照key的自然顺序甚至于自定义顺序的情况下
ArrayList 、 LinkedList 的区别
Arraylist基于Array(动态数组)结构
最大的数组容量是Integer.MAX_VALUE-8
对于空出的8位
①存储Headerwords
②避免一些机器内存溢出,减少出错几率,所以少分配
③最大还是能支持到Integer.MAX_VALUE
Linkedlist基于链表的动态数组
数据添加删除效率高,只需要改变指针指向即可
但是访问数据的平均效率低,需要对链表进行遍历
ArrayList与Vector的区别
同步性
Vector是线程安全的
方法之间是线程同步
ArrayList是线程序不安全的
方法之间是线程不同步
数据增长
Vector默认增长为原来的两倍
ArrayList增长为原来的1.5倍
Collection和Collections有什么区别
java.util.Collection 是一个集合接口
提供了对集合对象进行基本操作的通用接口方法
java.util.Collections 是一个包装类
各种有关集合操作的静态方法
不能实例化,就像一个工具类,服务于Java的Collection框架
Array 和 ArrayList 有何区别
ArrayList想象成一种“会自动扩增容量的Array”
Array大小固定,ArrayList的大小是动态变化的
Array可以包含基本类型和对象类型,ArrayList只能包含对象类型
Queue队列是一个典型的先进先出(FIFO)的容器
向队列中添加一个元素 offer()和add()的区别
如果想在一个满的队列中加入一个新元素
offer() 方法会返回 false
add() 方法就会抛出一个 unchecked 异常
不移除的情况下返回队头 peek()和element()的区别
peek()方法在队列为空时返回null
element()方法会抛出NoSuchElementException异常
移除并且返回队头 poll()和 remove()的区别
poll()在队列为空时返回null
remove()会抛出NoSuchElementException异常
迭代器Iterator
迭代器模式
使得序列类型的数据结构的遍历行为与被遍历的对象分离
Iterable
实现这个接口的集合对象支持迭代,是可以迭代的
可以配合foreach使用
Iterator:迭代器
Iterator迭代器包含的方法: hasNext():如果迭代器指向位置后面还有元素,则返回 true,否则返回false next():返回集合中Iterator指向位置后面的元素 remove():删除集合中Iterator指向位置后面的元素
提供迭代机制的对象,具体如何迭代是这个Iterator接口规范的
foreach和Iterator的关系
foreach中调用集合remove会导致原集合变化导致错误
应该用迭代器的remove方法
for循环和迭代器Iterator对比
for循环中的get()方法,采用随机访问的方法
ArrayList对随机访问比较快
iterator中的next()方法,采用顺序访问的方法
LinkedList则是顺序访问比较快
Iterator 和 ListIterator 的区别
ListIterator迭代器
ListIterator迭代器包含的方法: add(E e):将指定的元素插入列表,插入位置为迭代器当前位置之前 hasNext():以正向遍历列表时,如果列表迭代器后面还有元素,则返回 true,否则返回false hasPrevious():如果以逆向遍历列表,列表迭代器前面还有元素,则返回 true,否则返回false next():返回列表中ListIterator指向位置后面的元素 nextIndex():返回列表中ListIterator所需位置后面元素的索引 previous():返回列表中ListIterator指向位置前面的元素 previousIndex():返回列表中ListIterator所需位置前面元素的索引 remove():从列表中删除next()或previous()返回的最后一个元素(有点拗口,意思就是对迭代器使用hasNext()方法时,删除ListIterator指向位置后面的元素;当对迭代器使用hasPrevious()方法时,删 除ListIterator指向位置前面的元素) set(E e):从列表中将next()或previous()返回的最后一个元素返回的最后一个元素更改为指定元素e
使用范围不同
Iterator可以应用于所有的集合,Set、List和Map和这些集合的子类型
ListIterator只能用于List及其子类型
ListIterator功能更强大,可以增删改查
Iterator 和 ListIterator 的不同点 1.使用范围不同,Iterator可以应用于所有的集合,Set、List和Map和这些集合的子类型。而ListIterator只能用于List及其子类型。 2.ListIterator有add方法,可以向List中添加对象,而Iterator不能。 3.ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍 历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator不可以。 4.ListIterator可以定位当前索引的位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。 5.都可实现删除操作,但是ListIterator可以实现对象的修改,set()方法可以实现。Iterator仅能遍历,不能修改。
实现方法与原理
HashMap 的实现原理
Entry数组
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
存储位置
源码
static int indexFor(int h, int length) { return h & (length-1);}
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
由于和(length-1)运算,length 绝大多数情况小于2的16次方。所以始终是hashcode 的低16位参与运算。要是高16位也参与运算,会让得到的下标更加散列
所以(h >>> 16)得到他的高16位与hashCode()进行^运算
因为&和|都会使得结果偏向0或者1 ,并不是均匀的概念,所以用异或
HashSet 的实现原理
不允许有重复元素
HashSet的值存放于HashMap的key上
HashSet底层由HashMap实现,无序
HashSet中的元素都存放在HashMap的key上面
value统一为无意义静态常量private static final Object PRESENT = new Object();
怎么确保一个集合不能被修改
使用Collections包下的Collections. unmodifiableCollection(Collection c)方法
改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常
数组和list集合之间转换的各种方法
数组转List
package listtoArray; import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.List; import java.util.stream.Collectors; import java.util.stream.Stream; public class ArrayToList { public static void main(String[] args) { //数组转list String[] str=new String[] {"hello","world"}; //方式一:使用for循环把数组元素加进list List<String> list=new ArrayList<String>(); for (String string : str) { list.add(string); } System.out.println(list); //方式二: List<String> list2=new ArrayList<String>(Arrays.asList(str)); System.out.println(list2); //方式三: //同方法二一样使用了asList()方法。这不是最好的, //因为asList()返回的列表的大小是固定的。 //事实上,返回的列表不是java.util.ArrayList类,而是定义在java.util.Arrays中一个私有静态类java.util.Arrays.ArrayList //我们知道ArrayList的实现本质上是一个数组,而asList()返回的列表是由原始数组支持的固定大小的列表。 //这种情况下,如果添加或删除列表中的元素,程序会抛出异常UnsupportedOperationException。 //java.util.Arrays.ArrayList类具有 set(),get(),contains()等方法,但是不具有添加add()或删除remove()方法,所以调用add()方法会报错。 List<String> list3 = Arrays.asList(str); //list3.remove(1); //boolean contains = list3.contains("s"); //System.out.println(contains); System.out.println(list3); //方式四:使用Collections.addAll() List<String> list4=new ArrayList<String>(str.length); Collections.addAll(list4, str); System.out.println(list4); //方式五:使用Stream中的Collector收集器 //转换后的List 属于 java.util.ArrayList 能进行正常的增删查操作 List<String> list5=Stream.of(str).collect(Collectors.toList()); System.out.println(list5); } }
使用Stream中的Collector收集器
List<String> list5=Stream.of(str).collect(Collectors.toList());
List转数组
package listtoArray; import java.util.ArrayList; import java.util.List; public class ListToArray { public static void main(String[] args) { //list转数组 List<String> list=new ArrayList<String>(); list.add("hello"); list.add("world"); //方式一:使用for循环 String[] str1=new String[list.size()]; for(int i=0;i<list.size();i++) { str1[i]=list.get(i); } for (String string : str1) { System.out.println(string); } //方式二:使用toArray()方法 //list.toArray(T[] a); 将list转化为你所需要类型的数组 String[] str2=list.toArray(new String[list.size()]); for (String string : str2) { System.out.println(string); } //错误方式:易错 list.toArray()返回的是Object[]数组,怎么可以转型为String //ArrayList<String> list3=new ArrayList<String>(); //String strings[]=(String [])list.toArray(); } }
使用toArray()方法
String[] str2=list.toArray(new String[list.size()]);
List去重方式
利用java8的stream去重
List uniqueList = list.stream().distinct().collect(Collectors.toList());
Set集合不允许重复元素
遍历去重
微服务
理论知识
ESB(服务总线)
包含内容
服务元数据管理
服务注册、生命周期
协议适配
中介服务
各种集成场景,支持各种消息处理与转换模式
治理与监控
服务调用与消息处理的日志及统计分析,服务质量、服务降级,流控等
安全性
传输通信安全性,数据安全性、服务调用安全性,身份验证等
其他
事务管理、高性能、高可用、高可靠性、高稳定性等
熔断
服务注册发现
工具
ZooKeeper
Consul
Etcd,
eureka
客户端注册(zookeeper)
第三方注册(独立的服务 Registrar)
当服务启动后以某种方式通知Registrar, 然后 Registrar 负责向注册中心发起注册工作
同时注册中心要维护与服务之间的心跳,当服务不可用时,向注册中心注销服务。
客户端发现
服务端发现
API网关
API Gateway 是一个服务器,也可以说是进入系统的唯一节点
请求转发
服务转发主要是对客户端的请求安装微服务的负载转发到不同的服务上
响应合并
把业务上需要调用多个服务接口才能完成的工作合并成一次调用对外统一提供服务。
协议转换
重点是支持 SOAP, JMS, Rest 间的协议转换。
数据转换
重点是支持XML和Json 之间的报文格式转换能力(可选)
安全认证
1. 基于 Token 的客户端访问控制和安全策略
2. 传输数据和报文加密,到服务端解密,需要在客户端有独立的SDK 代理包
3. 基于 Https 的传输加密,客户端和服务端数字证书支持
4. 基于 OAuth2.0 的服务安全认证(授权码,客户端,密码模式等)
配置中心
要求
高效获取
实时感知
分布式访问
zookeeper配置中心
配置中心数据分类
事件调度(kafka)
服务跟踪(starter-sleuth)
随着微服务数量不断增长,需要跟踪—个请求从一个微服务到下一个微服务的传播过程,SpringCloud Sleuth 正是解决这个问题,它在日志中引入唯一ID,以保证微服务调用之间的一致性,这样你就能跟踪某个请求是如何从一个微服务传递到下一个。
服务熔断(Hystrix)
熔断器的原理很简单,如同电力过载保护器。它可以实现快速失败,如果它在一段时间内侦测到许多类似的错误,会强迫其以后的多个调用快速失败,不再访问远程服务器,从而防止应用程序不断地尝试执行可能会失败的操作,使得应用程序继续执行而不用等待修正错误,或者浪费 CPU时间去等到长时间的超时产生。熔断器也可以使应用程序能够诊断错误是否已经修正,如果已经修正,应用程序会再次尝试调用操作。
Hystrix断路器机制
当 Hystrix Command 请求后端服务失败数量超过一定比例(默认 50%), 断路器会切换到开路状态(Open).
断路器保持在开路状态一段时间后(默认 5 秒), 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN).
微服务中台
SpringCloud Alibaba
SpringCloud Netflix
包含项目
Eureke
基于REST服务的分布式中间件,用于服务管理
Hystrix
容错框架,帮助控制分布式系统间组件交互
调用失败时执行服务回退
支持实时监控,报警及其他操作
分布式系统中,停止级联故障(服务熔断)
Feign
REST客户端,目的为简化Web Service客户端开发
Ribbon
负载均衡框架,为微服务集群中各个客户端通信提供支持,实现中间层的负载均衡
Zuul
为微服务集群提供代理、过滤、路由等功能
Netty与RPC框架
Netty
Netty原理
是一个高性能、异步事件驱动的 NIO 框架,基于 JAVA NIO 提供的 API 实现
它提供了对TCP、UDP 和文件传输的支持
Netty 的所有 IO 操作都是异步非阻塞的
通过 Future-Listener 机制,用户可以方便的主动获取或者通过通知机制获得 IO 操作结果
Netty高性能
IO 多路复用技术通过把多个 IO 的阻塞复用到同一个 select 的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求
与传统的多线程/多进程模型比,I/O 多路复用的最大优势是系统开销小,系统不需要创建新的额外进程或者线程
系统不需要守护这些进程和线程的运行,降低了系统的维护工作量,节省了系统资源
多路复用通讯方式
Netty 的 IO线程 NioEventLoop 由于聚合了多路复用器 Selector ,可以同时并发处理成百上千个客户端 Channel,由于读写操作都是非阻塞的,这就可以充分提升 IO 线程的运行效率,避免由于频繁 IO 阻塞导致的线程挂起。
异步通讯NIO
由于 Netty 采用了异步通信模式一个 IO 线程可以并发处理 N 个客户端连接和读写操作 ,这从根本上解决了传统同步阻塞 IO 一连接一线程模型
零拷贝(DIRECT BUFFERS 使用堆外直接内存)
1.Netty 的接收和发送 ByteBuffer 采用 DIRECT BUFFERS,使用堆外直接内存进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS) 进行 Socket 读写,JVM 会将堆内存 Buffer 拷贝一份到直接内存中,然后才写入 Socket 中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
2.Netty 提供了组合 Buffer 对象,可以聚合多个 Byte Buffer 对象,用户可以像操作一个 Buffer 那样方便的对组合 Buffer 进行操作,避免了传统通过内存拷贝的方式将几个小 Buffer 合并成一个大的Buffer。
3.Netty 的文件传输采用了 transferTo方法,它可以直接将文件缓冲区的数据发送到目标 Channel,避免了传统通过循环 write 方式导致的内存拷贝问题
内存池(基于内存池的缓冲区重用机制)
重用缓冲区,
Netty 提供了基于内存池的缓冲区重用机制
Reactor 线程模型
Reactor 单线程模型
指的是所有的I0 操作都在同一个 NIO 线程上面完成
1) 作为 NIO 服务端,接收客户端的TCP 连接;
2)作为NIO客户端,向服务端发起TCP 连接;
3) 读取通信对端的请求或者应答消息;
4)向通信对端发送消息请求或者应答消息。
由于 Reactor 模式使用的是异步非阻塞 IO,所有的 IO 操作都不会导致阻塞,理论上一个线程可以独立处理所有 IO 相关的操作。
Reactor 多线程模型
Rector 多线程模型与单线程模型最大的区别就是有一组 NIO 线程处理 IO 操作。
NIO 线程-Acceptor线程用于监听服务端,接收客户端的TCP 连接请求;
网络 I0操作-读、写等由一个 NIO 线程池负责
线程池可以采用标准的JDK 线程池实现,它包含一个任务队列和 N个可用的线程,由这些 NIO 线程负责消息的读取、解码、编码和发送;
主从 Reactor 多线程模型号
服务端用于接收客户端连接的不再是个1 个单独的 NIO 线程,而是一个独立的NIO 线程池。
Acceptor 接收到客户端 TCP连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel 注册到IO线程池 (sub reactor 线程池)的某个 IO 线程上,由它负责SocketChannel 的读写和编解码工作。
Acceptor 线程池仅仅只用于客户端的登陆、握手和安全认证,一旦链路建立成功,就将链路注册到后端 subReactor线程池的IO线程上,由IO线程负责后续的IO操作。
无锁设计、线程绑定
Netty 采用了串行无锁化设计,在 10 线程内部进行串行操作,避免多线程竞争导致的性能下降。
可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行线程设计相比一个队列-多个工作线程模型性能更优。
高性能的序列化框架
1.SO RCVBUF 和 SO SNDBUF
通常建议值为128K 或者 256K。
2.SO TCPNODELAY:
小包封大包,防止网络阻塞
3.软中断:开启 RPS 后可以实现软中断,提升网络吞吐量。
软中断 Hash 值利CPU 绑定
Netty RPC实现
RPC概念
调用远程计算机上的服务,就像调用本地服务一样。
RPC 可以很好的解耦系统,如 WebService 就是一种基于 Http 协议的 RPC。
关键技术
1.服务发布与订阅:服务端使用 Zookeeper 注册服务地址,客户端从 Zookeeper 获取可用的服务地址。
2. 通信:使用 Netty 作为通信框架。
3.Spring:使用 Spring 配置服务,加载 Bean,扫描注解。
4.动态代理:客户端使用代理模式透明化服务调用。
5.消息编解码:使用 Protostuff 序列化和反序列化消息。
核心流程
1.服务消费方 (client)调用以本地调用方式调用服务;
2.client stub 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
3.client stub 找到服务地址,并将消息发送到服务端;
4.server stub 收到消息后进行解码;
5.server stub 根据解码结果调用本地的服务;
6.本地服务执行并将结果返回给 server stub;
7.server stub 将返回结果打包成消息并发送至消费方;
8.client stub 接收到消息,并进行解码;
9.服务消费方得到最终结果。
消息编解码
消息数据结构(接口名称+ 方法名 + 参数类型和参数值 + 超时时间 + requestID
1.接口名称:在我们的例子里接口名是"HelloWorldService〞,如果不传,服务端就不知道调用哪个接口了;
2.方法名:一个接口内可能有很多方法,如果不传方法名服务端也就不知道调用哪个方法;
3.参数类型和参数值:参数类型有很多,比如有 bool int、 long、 double、 string、 map、 list,甚至如 struct (class);以及相应的参数值;
4.超时时间:
5.requestID,标识唯一请求id,在下面一节会详细描述 requestID 的用处。
6.服务端返回的消息:一般包括以下内容。返回值+状态 code+ requestID
序列化
方案
Protobuf
优点
性能方面
体积小
序列化后,数据大小可缩小约3倍
序列化速度快
比XML和JSON 快20-100倍
传输速度快
因为体积小,传输起来带宽和速度会有优化
使用方面
使用简单
proto编译器 自动进行序列化和反序列化
维护成本低
多平台仅需维护一套对象协议文件 (.proto)
向后兼容性好
即扩展性好:不必破坏 旧数据格式 就可以直接对 数据结构 进行更新
加密性好
Http 传输内容抓包只能看到字节
使用范围方面
跨平台
跨语言
可拓展性好
缺点
功能方面
不适合用于对基于文本的标记文档(如 HTML)建楼,因为文本不适合描述数据结构
其他方面
通用性较差
Json、XML已经成为多种行业标准的编写工具,而Protobuf只是 Google 公司内部使用的工具
自解释性差
以二进制数据流方式存储(不可读),需要通过 .proto文件 才能了解到数据结构
总结
Protocol Buffer比XML、 Json 更小、更快、使用&维护更简单!
Thrift
Avro
通讯流程
requestID 生成-AtomicLong
存放回调对象 callback 到全局 ConcurrentHashMap
synchronized 获取回调对象 callback 的锁并自旋wait
监听消息的线程收到消息,找到callback 上的锁并唤醒
RMI实现方式
1. 编写远程服务接口,该接口必须继承 java.rmi.Remote 接口,方法必须抛出java.rmi.RemoteException 异常;
2.编写远程接口实现类,该实现类必须继承 java.rmi.server.UnicastRemoteObject 类;
3. 运行 RMI 编译器 (rmic),创建客户端 stub 类和服务端 skeleton 类;
4.启动一个 RMI 注册表,以便驻留这些服务;
5. 在RMI 注册表中注册服务;
6.客户端查找远程对象,并调用远程方法;
跨语言RPC框架
Hessian
Apache Thrift
gRPC
Hprose
服务治理RPC框架
Dubbo
组成
Provider
Consumer
Registry
Monitor
支持的容器
Spring
Jetty
Log4j
Logback
支持的协议
默认dubbo同一个服务可配置多种协议,需配置协议对应端口
dubbo(默认)
RMI
hessian
webservice
http
thrift
支持的注册中心
支持多注册中心- 中英文网站,配置中心分离
zookeeper
redis
multicast
simple
服务治理
负载均衡
随机负载(默认)
可设置权重
一致性哈希
最小活跃度
....
配置
注册中心支持本地缓存(缓存在文件系统)
file="c:/dubbo-server"
DubboX
JSF
Motan
数据库
存储引擎
哈希存储引擎
支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统
代表数据库:redis,Memcache,存储系统Bitcask
B树存储引擎
不仅支持随机读取,还支持范围扫描
LSM树(Log-Structured Merge Tree)存储引擎
分布式数据库
HBase
概述
从BigTable说起
BigTable是一个分布式存储系统,利用谷歌提出的MapReduce分布式并行计算模型处理海量数据,使用谷歌分布式文件系统GFS作为其底层数据存储方式,并采用Chubby提供系统管理服务,可以扩展到PB级别的数据和上千台机器,具有广泛应用性、可扩展性、高性能和高可用性等特点。
BigTable具有以下特性:
支持大规模海量数据
分布式并发数据处理效率高
易于扩展且支持动态伸缩
适用于廉价设备
适合读操作不适合写操作
HBase简介
HBase利用Hadoop Mapreduce来处理HBase中的海量数据,实现高性能计算;
利用Zookeeper作为协同服务,实现稳定服务和失败恢复;
使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力。
为了方便在HBase上进行数据处理,Sqoop为HBase提供了高效、便捷的关系数据库管理系统数据导入功能,
Pig和Hive为HBase提供了高层语言支持
HBase是BigTable的开源实现
HBase和BigTable的底层技术对应关系:
HBase与传统关系数据库的关系分析
HBase是一种非常成熟、稳定的数据库管理系统,通常具备的功能包括面向磁盘的存储和索引结构、多线程访问、基于锁的同步访问机制、基于日志记录的恢复机制和事务机制等。
HBase与传统是关系数据库的区别主要体现在以下几个方面:
数据类型
数据操作
存储模式
数据索引
数据维护
可伸缩性
Hbase 访问接口
类型:Native Java API
特点:常规和高效的访问方式
使用场合:适合Hadoop MapReduce作业并行批处理HBase表数据
类型:Hbase Shell
特点:HBase的命令行工具,简单的接口
使用场合:适合HBase管理
类型:Thrift Gateway
特点:利用Thrift序列化技术,支持C++、PHP、Python等多种语言
使用场合:适合其他异构系统在线访问HBase表数据
类型:REST Gateway
特点:解除语言限制
使用场合:支持REST风格的HTTP API访问Hbase
类型:Pig
特点:使用Pig Latin流式编程语言来处理HBase中的数据
使用场合:适合做数据统计
类型:Hive
特点:简单
使用场合:当需要与一类似SQL的方式来访问HBase的时候
HBase 数据模型
数据模型概述
HBase是一个稀疏、多维度、排列的映射表,这张表的索引包括行键、列族、列限定符和时间戳。
数据模型的相关概念
表
HBase采用表来组织数据,表由行和列组成,列划分为若干个列族。
行键
每个HBase表都有若干行组成,每个列由列键(Row Key)来标识。
列族
一个HBase表被分组成许多“列族”的集合,它是基本的访问控制单元。
列限定符
列族里的数据通过列限定符(或列)来定位。
单元格
在HBase表中,通过行键、列族和列限定符确定一个单元格(Cell)。
时间戳
每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
数据坐标
HBase使用坐标来定位表中的数据,每个值都通过坐标来访问。
概念视图
在HBase的概念视图中,一个表可以视为一个稀疏、多维的映射关系。
物理视图
从概念视图层面,HBase中的每个表是由许多行组成的,但是在屋里存储层面,它猜用基于列的存储方式,而不是像传统关系数据库那样采用基于行的存储方式,这也是HBase和传统关系数据库的重要区别。
面向列的存储
通过前面的论述,我们已经知道HBase是面向列的存储,HBase是一个“列式数据库”。
HBase的实现原理
HBase的功能组件
库函数,链接到每个客户端。
一个Master主服务器(也称为Master)。
许多个Region服务器。
表和Region
在一个HBase中,存储了很多表。每个表只包含一个Region,随着数据的不断插入,Region会持续增大。
Region的定位
一个HBase的表可能非常庞大,会被分裂成很多个Region,这些Region可被分发到不同的Region服务器上。
HBase运行机制
HBase系统架构
客户端
Zookeeper服务器
Master主服务器
Region服务器
Region服务器的工作原理
用户读写数据的过程
缓存的刷新
StoreFile
Store的工作原理
Region服务器是HBase的核心模块,而Store是Region服务器的核心。每个Store对应了表中的一个列族的存储。每个Store包含一个MEMStore缓存和若干个StoreFile文件。
HLog的工作原理
在分布式环境下,必须考虑到系统出错的情形,比如当Region服务器发生故障时,MEMStore缓存中的数据(还没有被写入文件)会全部丢失。因此,HBase采用HLog来保证系统发生故障时能够恢复到正常的状态。
HBASE编程实践
HBase常用的Shell命令
HBase常用的Java API及应用实例
关系型数据
MySQL
索引优化
优化索引-二叉查找树
特点
所有非叶子节点的最多有两个子节点
每个节点存储一个关键字
非叶子节点的左指针小于其关键字的子树,右指针指向大于其关键字的子树
TODO
优化索引 之B树
特点
多路搜索树,不一定是二叉的
定义任意一个叶子节点最多只有M个儿子,且M>2;
根节点的的儿子树为[2,M]
除根节点以外的节点的儿子树为[M/2,M]
每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
非叶子结点的关键字个数=指向儿子的指针个数-1;
非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
非叶子结点的指针:
P[1], P[2], …, P[M] ;其中 P[1] 指向关键字小于 K[1] 的子树,
P[M] 指向关键字大于 K[M-1] 的子树,其它 P[i] 指向关键字属于 (K[i-1], K[i]) 的子树;
所有叶子结点位于同一层;
B树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果 命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
1.关键字集合分布在整颗树中; 2.任何一个关键字出现且只出现在一个结点中; 3.搜索有可能在非叶子结点结束; 4.其搜索性能等价于在关键字全集内做一次二分查找; 5.自动层次控制; 由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为: 其中,M为设定的非叶子结点最多子树个数,N为关键字总数; 所以B树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题; 由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
优化索引-B+树
特点
是B树的变体
非叶子节点的树指针与关键字个数相同
非叶子节点的子树指针p[i],指向关键字值属于[K[i], K[i+1])的子树,B+ 树是 开区间
为所有的叶子节点添加一个链指针
所有的关键字都在叶子节点出现
B+树的搜索只有到 叶子节点才会命中,(B树可以在非叶子节点命中),性能等价于在关键字 全集 做一次 二分查找
所有的关键字都出现在叶子节点的链表中(稠密索引),且链表是有序的
不可能在非叶子节点命中
非叶子节点相当于 叶子节点的索引 (稀疏索引),叶子节点相当于存储关键字的 数据层
更适合文件索引系统
查询效率稳定
B*树 是 B+树的变种,新建节点少,空间利用率高
优化索引-Hash以及BitMap
仅仅能满足 “=”,“IN”,不能使用范围查询
无法用来做数据的排序操作
不能利用部分索引键进行查询
密集索引和稀疏索引
密集索引
密集索引文件中的每个索引码都对应一个索引值
INNODB
若有主键被定义,则主键作为密集索引
若没有主键定义,该表的第一个唯一非空索引作为密集索引
若无主键,也无非空索引,innodb内部会生成一个隐藏主键(密集索引)
非主键索引存储相关键位和其对应的主键值,包含两次查找
稀疏索引
稀疏索引文件只为索引码的某些值建立索引项
MyISAM
索引优化问题 优化sql
查看 慢日志 定位慢sql
使用 show variable like '%quer%' 查看配置信息
slow_query_log 慢查询日志开启状态
set global slow_query_log = ON
long_query_time 慢查询时间多长会被写入
set global long_query_time =1
slow_query_log_file 慢日志文件位置
使用explain等 工具 分析sql
explain 主要关键词
id
select 查询的 子查询序列号,表示select 子句 或操作表的顺序。id相同则从上到下。id不同则 id大的执行优先级更高
select_type
表示那种类型查询,主要用于区分 普通查询,联合查询,子查询等复杂查询
SIMPLE
PRIMARY
SUBQUERY
DERIVED
UNION
UNION RESULT
table
当前执行表
possible_keys
当前表存在的索引,不一定使用
key
实际使用的索引,如果为NULL,则表示没使用索引(包括没建索引或者索引失效)
key_len
索引中使用的字节数,可以通过该列计算查询中使用的索引长度,在不损失精度的情况下,长度越短越好。key_len表示索引字段的最大可能长度,不代表实际长度。即key_len是通过表定义计算得出的,非表查询得出的。
ref
表示索引的哪一列被使用了,如果可能的话,最好是一个常数。那些列或者常量被用于查找索引列上的值。
type
查询从最优到最差排序
system>const>eq_ref>ref>fulltext>ref_or_null>index_merage>unique_subquery>index_subquery>range>index>all
当出现 index、all时,表示走的是全表扫描
extral
extral如果出现以下情况意味着MYSQL根本不能使用索引,效率会受大影响。尽可能对此进行优化
Using filesort
表示MYSQL会对结果使用一个外部排序,而不是从表里按索引次序读取到内容。可能是磁盘或者内存上进行排序。MYSQL中无法利用索引完成的排序操作称为 “文件排序”
Using temporary
表示MYSQL 对查询结果使用临时表。 常用于排序 order by 和分组查询 group by
rows
根据表统计信息及索引选用情况,大致估算出所需的记录查询需要读取的行数,这个行数越少越好。
修改sql或者尽量让sql走索引
索引最左匹配原因
最左匹配原则:MYSQL会一直向右匹配,一直匹配到范围查询就停止匹配。如建立a,b,c,d顺序索引,条件 a=1 and b=2 and c>1 and d =2, d是不会用到索引的,如果建立abdc 顺序索引,则abcd都可以用到
= 和 in 可以乱序,msql查询优化器 会帮你优化索引成可识别的形式
原因
索引底层是B+树,联合索引当然还是一个B+树,只不过联合索引的键值不止一个,而是多个。构建一个B+树只能根据一个值来构建,因此数据库根据最左字段来构建B+树

匹配的几种情况 假如建立联合索引 (a,b,c)
全值匹配查询时
select * from table_name where a = '1' and b = '2' and c = '3' select * from table_name where b = '2' and a = '1' and c = '3' select * from table_name where c = '3' and b = '2' and a = '1' ......
用到的索引,子条件顺序调换不影响结果 Mysql查询优化器会自动优化查询顺序
匹配到最左列时
select * from table_name where a = '1' select * from table_name where a = '1' and b = '2' select * from table_name where a = '1' and b = '2' and c = '3'
都从最左列开始 连续匹配,用到了索引
select * from table_name where b = '2' select * from table_name where c = '3' select * from table_name where b = '1' and c = '3'
这些都没有从最左边开始,最后查询没有用到索引,走全表扫描
select * from table_name where a = '1' and c = '3'
不连续时,只用到了a列的索引,b和c都么有用到
匹 配 前 缀
select * from table_name where a like 'As%'; //前缀都是排好序的,走索引查询 select * from table_name where a like '%As'//全表查询 select * from table_name where a like '%As%'//全表查询
如果是a是字符型的,比较规则是 比较字符串的第一个字符,第一个字符串的字符比较小这个字符串就比较小,如果第一个字符相同,则比较第二个字符,以此类推。 所以 前缀匹配走的是索引,后缀匹配 和中缀匹配 走的全表扫描
匹 配 范 围 值
select * from table_name where a > 1 and a < 3
可以对最左列进行范围查询,走索引
select * from table_name where a > 1 and a < 3 and b > 1;
多列范围查询时,只有最左列 a范围查询可以用到索引,在1<a<3范围内,b是无序的,不能用索引。找到1<a<3的记录后,只能根据条件b>1进行逐条过滤。
精确匹配一列并范围查找一列
select * from table_name where a = 1 and b > 3;
a=1情况下 b是有序的,进行范围查询走的是联合索引
排序
一般情况下 mysql 用到文件排序,比较慢,如果order by 里有索引,可以省去文件排序步骤
select * from table_name order by a,b,c limit 10;
用到索引
select * from table_name order by b,c,a limit 10;
颠倒顺序的用不到索引
select * from table_name order by a limit 10; select * from table_name order by a,b limit 10;
用到部分索引
select * from table_name where a =1 order by b,c limit 10;
联合索引最左列是常量,后面排序可以走索引
数据读取与事务隔离
锁模块并发产生的问题-事务隔离机制
更新丢失
mysql的所有事务隔离级别在数据库层面均可避免
脏读
READ_COMMITTED事务隔离级别及以上 可以避免
脏读的产生
READ_UNCOMMITTED 事务隔离级别下,两个事务同时对同一行进行修改,一旦其中一个事务发生了ROLL BACK(回滚),就会导致另外一个事务产生脏读。(事务A读到了事务B提交失败的数据,实际数据已经回滚)
不可重复读
不可重复读产生
事务A 多次读取一行记录,事务B,事务C 分别修改这行记录,在事务B,事务C提交事务之后,A事务还没有提交,此时事务A 先后读取事务B,事务C提交后的记录,该行记录 已经被修改,读取到的记录是不同的
幻读
幻读产生
事务A读取数据若干行,事务B以插入/删除方式修改了事务A的结果集,事务A再次操作发现了还没有操作过的数据行,就像幻觉一样,(出现了不该出现的记录)
当前读和快照读
当前读
select *** lock in share mode, select*** for update
update,delete,insert
快找读
不加锁的非阻塞读,select
RC,RR 级别下的InnoDB如何实现非阻塞读
数据行里的DB_TRX_ID,DB_ROLL_PTR,DB_ROW_ID 字段
undo 日志
read view
RR如何避免幻读
InnoDB 会加一个 GAP锁+ next-key锁,避免了幻读
对主键索引或者唯一索引会使用GAP锁吗
如果where条件全部命中,则不会使用GAP锁,只会添加记录锁
在RR隔离级别下,Gap锁会用在非唯一索引,或者不走索引的当前读中
explain分析优化
select_type (查询中每个select子句的类型)
(1) SIMPLE(简单SELECT,不使用UNION或子查询等)
(2) PRIMARY(查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION(UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT(UNION的结果)
(6) SUBQUERY(子查询中的第一个SELECT)
(7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,取决于外面的查询)
(8) DERIVED(派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
type (MySQL在表中找到所需行的方式, 又称“访问类型”)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行(阿里要求最少)
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值(阿里建议最好达到)
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
possible_keys
MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
Key
key列显示MySQL实际决定使用的键(索引)
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的) 不损失精确性的情况下,长度越短越好
ref
上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows
MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
Extra
Using where:列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询
(如果出现以上的两种的红色的Using temporary和Using filesort说明效率低)
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行。
Using filesort:MySQL中无法利用索引完成的排序操作称为“文件排序”
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
Mysql调优
字段设计
尽量使用整型表示字符串
尽可能选择小的数据类型和指定短的长度
尽可能使用 not null
单表字段不宜过多
可以预留字段
范式 Normal Format
第一范式1NF:字段原子性
第二范式:消除对主键的部分依赖
第三范式:消除对主键的传递依赖
查询缓存
windows上是my.ini,linux上是my.cnf
0:不开启
1:开启,默认缓存所有,SQL语句中增加select sql-no-cache来放弃缓存
2:开启,默认都不缓存,SQL语句中增加select sql-cache来主动缓存(常用)
缓存失效问题
当数据表改动时,基于该数据表的任何缓存都会被删除
分区
只有检索字段为分区字段时,分区带来的效率提升才会比较明显
水平分割和垂直分割
水平分割:通过建立结构相同的几张表分别存储数据
垂直分割:将经常一起使用的字段放在一个单独的表中,分割后的表记录之间是一一对应关系
典型的服务器配置
max_connections,最大客户端连接数
show variables like 'max_connections'
table_open_cache,表文件句柄缓存
key_buffer_size,索引缓存大小
innodb_buffer_pool_size,Innodb存储引擎缓存池大小
innodb_file_per_table
压测工具
mysqlslap
问题排查
使用 show processlist 命令查看当前所有连接信息
使用 explain 命令查询SQL语句执行计划
开启慢查询日志,查看慢查询的SQL
NoSQL
MongoDB
MongoDB入门
nosql与sql使用场景分析
基础概念
mongodb进阶
常用命令
快速入门
mongodo客户端驱动
增删改查与聚合
安全控制
mongodb高级知识
存储引擎
索引
高可用
最佳实践与注意事项
数据结构
栈 (stack)
栈(stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的未端,叫做栈顶(top)
它是后进先出(LIFO)的。对栈的基本操作只有 push(进栈)和 pop(出栈)两种,前者相当于插入,后者相当于删除最后的元素。
队列 (queue)
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端 (rear)进行插入操作,
队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
链表 (Link)
链表是一种数据结构,和数组同级。比如,Java 中我们使用的 ArrayList,其实现原理是数组。
Linkedlist 的实现原理就是链表。
链表在进行循环遍历时效率不高,但是插入和删除时优势明显。
散列表 (Hash Table)
散列表(Hash table,也叫哈希表)是一种查找算法,与链表、树等算法不同的是,散列表算法在查找时不需要进行一系列和关键字(关键字是数据元素中某个数据项的值,用以标识一个数据元素)的比较操作。
散列表算法希望能尽量做到不经过任何比较,通过一次存取就能得到所查找的数据元素,因而必须要在数据元素的存储位置和它的关键字(可用 key 表示)之间建立一个确定的对应关系,使每个关键字和散列表中一个唯一的存储位置相对应。
构造散列函数的方法有:
(1) 直接定址法:取关键字或关键字的某个线性函数值为散列地址。
即:h(key) = key 或 h(key) = a* key + b 其中a 和b为常数。
(2)数字分析法
(3)平方取值法:取关键字平方后的中间几位为散列地址。
(4)折叠法:将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为散列地址。
(5)除留余数法:取关键字被某个不大于散列表表长m 的数p除后所得的余数为散列地址,
即:h(key) = key MOD p ps m
(6) 随机数法:选择一个随机函数,取关键字的随机函数值为它的散列地址,
即:h(key) = random(key)
排序二叉树
排序二叉树每个节点满足:
左子树所有节点值小于它的根节点值,
且右子树所有节点值大于它的根节点值
插入操作
首先要从根节点开始往下找到自己要插入的位置(即新节点的父节点);具体流程是:新节点与当前节点比较,如果相同则表示已经存在且不能再重复插入;如果小于当前节点,则到左子树中寻找,如果左子树为空则当前节点为要找的父节点,新节点插入到当前节点的左子树即可;如果大于当前节点,则到右子树中寻找,如果右子树为空则当前节点为要找的父节点,新节点插入到当前节点的右子树即可。
删除操作
删除操作主要分为三种情况
要删除的节点无子节点
要删除的节点只有一个子节点
要删除的节点有两个子节点
1.对于要删除的节点无子节点可以直接删除,即让其父节点将该子节点置空即可。
2. 对于要删除的节点只有一个子节点,则替换要删除的节点为其子节点。
3. 对于要删除的节点有两个子节点,则首先找该节点的替换节点(即右子树中最小的节点),接着替换要删除的节点为替换节点,然后删除替换节点。
查询操作
查找操作的主要流程为:
先和根节点比较,如果相同就返回,
如果小于根节点则到左子树中递归查找,
如果大于根节点则到右子树中递归查找。
因此在排序二叉树中可以很容易获取最大(最右最深子节点)和最小(最左最深子节点)值。
红黑树
红黑树的特性
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。[注意:这里叶子节点,是指为空(N儿L或NULL)的叶子节点!
(4)如果—个节点是红色的,则它的子节点心须是黑色的。
(5) 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
左旋
对×进行左旋,意味着,将“x的右孩子〞设为“x 的父亲节点〞;即,将× 变成了一个左节点(x成了为Z的左孩子)!
因此,左旋中的"左〞,意味着"被旋转的节点将变成一个左节点〞。
LEFT-ROTATE(T, x) y ← right[x] // 前提:这里假设 x 的右孩子为 y。下面开始正式操作 right[x] ← left[y] // 将 “y 的左孩子” 设为 “x 的右孩子”,即 将β设为 x 的右孩子 p[left[y]] ← x // 将 “x” 设为 “y 的左孩子的父亲”,即 将β的父亲设为 x p[y] ← p[x] // 将 “x 的父亲” 设为 “y 的父亲” if p[x] = nil[T] then root[T] ← y // 情况 1:如果 “x 的父亲” 是空节点,则将 y 设为根节点 else if x = left[p[x]] then left[p[x]] ← y // 情况 2:如果 x 是它父节点的左孩子,则将 y 设为“x 的父节点的左孩子” else right[p[x]] ← y // 情况 3:(x 是它父节点的右孩子) 将 y 设为“x 的父节点的右孩子” left[y] ← x // 将 “x” 设为 “y 的左孩子” p[x] ← y // 将 “x 的父节点” 设为 “y”
右旋
对x进行右旋,意味着,将"x的左孩子〞设为”x的父亲节点〞;即,将×变成了一个右节点(x成了为y的右孩子)!
因此,右旋中的“右〞,意味着“被旋转的节点将变成一个右节点〞。
RIGHT-ROTATE(T, y) x ← left[y] // 前提:这里假设 y 的左孩子为 x。下面开始正式操作 left[y] ← right[x] // 将 “x 的右孩子” 设为 “y 的左孩子”,即 将β设为 y 的左孩子 p[right[x]] ← y // 将 “y” 设为 “x 的右孩子的父亲”,即 将β的父亲设为 y p[x] ← p[y] // 将 “y 的父亲” 设为 “x 的父亲” if p[y] = nil[T] then root[T] ← x // 情况 1:如果 “y 的父亲” 是空节点,则将 x 设为根节点 else if y = right[p[y]] then right[p[y]] ← x // 情况 2:如果 y 是它父节点的右孩子,则将 x 设为“y 的父节点的左孩子” else left[p[y]] ← x // 情况 3:(y 是它父节点的左孩子) 将 x 设为“y 的父节点的左孩子” right[x] ← y // 将 “y” 设为 “x 的右孩子” p[y] ← x // 将 “y 的父节点” 设为 “x”
添加
第一步:将红黑树当作一颗二叉查找树,将节点插入。
第二步:将插入的节点着色为"红色。
第三步:通过一系列的旋转或着色等操作,使之重新成为一颗红黑树。
删除
第一步:将红黑树当作一颗二叉查找树,将节点删除。
这和"删除常规二叉查找树中删除节点的方法是一样的"。分3种情况:
① 被删除节点没有儿子,即为叶节点。那么,直接将该节点删除就OK了。
② 被删除节点只有一个儿子。那么,直接删除该节点,并用该节点的唯—子节点顶替它的位置。
③ 被删除节点有两个儿子。那么,先找出它的后继节点;然后把“它的后继节点的内容〞复制给"该节点的内容〞;之后,删除“它的后继节点〞。
第二步:通过"旋转和重新着色"等一系列来修正该树,使之重新成为一棵红黑树。
因为"第一步"中删除节点之后,可能会违背红黑树的特性。 所以需要通过"旋转和重新着色"来修正该树,使之重新成为一棵红黑树。
选择重着色3 种情况。
① 情况说明:x是“红+黑”节点。
处理方法:直接把x 设为黑色,结束。此时红黑树性质全部恢复。
2⃣️情况说明:x是“黑+黑”节点,且x是根。
处理方法:什么都不做,结束。此时红黑树性质全部恢复。
③ 情况说明:x是〞黑+黑”节点,且x不是根。
B-TREE
B-tree 又叫平衡多路查找树。一棵m 阶的 B-tree (m 叉树)的特性如下(其中 ceil(x)是一个取上限的函数):
1. 树中每个结点至多有m 个孩子;
2. 除根结点和叶子结点外,其它每个结点至少有有 ceil(m / 2)个孩子;
3. 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
4.所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询
失败的结点,实际上这些结点不存在,指向这些结点的指针都为 null);
5.每个非终端结点中包含有n个关键字信息:(n, PO, K1, P1, K2, P2,Kn, Pn)。其中:
a) Ki(=1..n)为关键字,且关键字按顺序排序 K(-1)< Ki。
b) Pi 为指向子树根的接点,且指针 P(-1)指向子树种所有结点的关键字均小于 Ki,但都大于 K(i-1)。
c)关键字的个数n必须满足:ceil(m / 2)-1 <=n <=m-1。
一棵m阶的 B+tree 和m 阶的 B-tree 的差异在于:
1.有n棵子树的结点中含有 n个关键字;(B-tree 是 n棵子树有 n-1个关键字)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的小自小而大的顺序链接。(B-tree 的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (B-tree 的非终节点也包含需要查找的有效信息)
位图
位图的原理就是用一个 bit 来标识一个数字是否存在,采用一个 bit 来存储一个数据,所以这样可以大大的节省空间。
bitmap 是很常用的数据结构,比如用于 Bloom Filter 中;用于无重复整数的排序等等。
bitmap 通常基于数组来实现,数组中每个元素可以看成是一系列二进制数,所有元素组成更大的二进制集合。
基本概念
Java基础概念
JDK与JRE
JDK为Java开发工具包,包含Java编译及运行所需的工具、IDE以及JRE
JRE即Java运行环境,包含JVM(Java虚拟机)和系统类库
关系图
JavaEE(Java平台企业版)
包含技术标准
Applet
是一种 Java 程序。它一般运行在支持 Java 的 Web 浏览器内
Applet 被设计为嵌入在一个 HTML 页面
当用户浏览包含 Applet 的 HTML 页面,Applet 的代码就被下载到用户的机器上
EJB
JNDI
Java 命名和目录接口
JDBC
Servlet
运行在 Web 服务器或应用服务器上的程序
它是作为来自 Web 浏览器和 HTTP 服务器上的数据库或应用程序之间的中间层
与CGI比较
性能更好,且独立于平台
在 Web 服务器的地址空间内执行,无需创建单独进程处理每个客户端请求
Servlet 是可信的,是因为Java 安全管理器执行了一系列限制
java 类库的全部功能对 Servlet 来说都是可用的
架构图
作用
实现 Servlet 规范定义的各种接口和类,为 Servlet 的运行提供底层支持
管理用户编写的 Servlet 类,以及实例化以后的对象
提供 HTTP 服务,相当于一个简化的服务器
JSP
Java IDL(接口定义语言)/CORBA
XML
JMS(Java Message Service)
JTA(Java Transaction Architecture)
JTS(Java Transaction Service)
JavaMail
JAF(JavaBeans Activation Framework)
分类
JavaWeb
开发Web程序
JavaSE
C/S架构,用于开发和部署在桌面、服务器、嵌入式环境和实时环境中使用的 Java 应用程序
JavaME
移动设备和嵌入式设备(手机、PAD等)上的运行环境
关系图
(Common Gateway Interface,公共网关接口)CGI
JavaBeans
是一个面向对象的编程接口
是一个Java类,主要集中解决如何在开发工具中进行应用集成
POJO(Plain OrdinaryJava Object)
指没有使用Entity Beans的普通java对象
实质上可以理解为简单的实体类
可以很方便的将POJO类当做对象来进行使用,当然也是可以方便的调用其get,set方法
POJO类也给我们在struts框架中的配置带来了很大的方便
Servlet
Jsp
内置对象
1 request javax.servlet.http.HttpServletRequest
客户端的请求信息:Http协议头信息、Cookie、请求参数等
2 response javax.servlet.http.HttpServletResponse
用于服务端响应客户端请求,返回信息
3 pageContext javax.servlet.jsp.PageContext
页面的上下文
4 session javax.servlet.http.HttpSession
客户端与服务端之间的会话
5 application javax.servlet.ServletContext
用于获取服务端应用生命周期的信息
6 out javax.servlet.jsp.JspWriter
用于服务端传输内容到客户端的输出流
7 config javax.servlet.ServletConfig
初始化时,Jsp 引擎向 Jsp 页面传递的信息
8 page java.lang.Object
指向 Jsp 页面本身
9 exception java.lang.Throwable
页面发生异常,产生的异常对象
作用域
page 当前页面作用域
该作用域中存放的属性值,只能在当前页面中取出
request 请求作用域
范围是从请求创建到请求消亡这段时间,一个请求可以涉及的多个页面
session 会话作用域
范围是一段客户端和服务端持续连接的时间
用户在会话有效期内多次请求所涉及的页面
application 全局作用域
范围是服务端Web应用启动到停止,整个Web应用中所有请求所涉及的页面
Servlet组件
什么是Servlet?
可以提供动态的html响应
他是运行在服务器上的java类
用来完成b/s架构下 客户请求的动态响应
这个java类,需要遵守jsp/Servlet规范
如何编写一个Servlet
三种方式
建立一个动态web项目,写一个java类继承javax.servlet.http.HttpServlet 抽象类, 重写 doGet() 或 doPost() 方法
实现 javax.servlet.Servlet 接口,重写其全部方法
继承 javax.servlet.GenericServlet 抽象类,重写 service() 方法
需要把web-inf下,配置web.xml
把项目部署到web服务器,使用url格式请求测试
创建动态web项目
Dynamic web
注意:选择tomcat运行环境和web版本
//服务器告知浏览器以html方式进行翻译和utf-8进行编码 resp.setContentType("text/html;charset=utf-8;");
// 写入浏览器,获取一个向浏览器输出对象 PrintWriter p = resp.getWriter(); p.write("<h1>" + s + "<h2>");
web.xml
<!-- 配置servlet --> <servlet> <servlet-name>一致</servlet-name> <servlet-class>包名.类名</servlet-class> </servlet> <servlet-mapping> <servlet-name>一致</servlet-name> <url-pattern>/自己写</url-pattern> </servlet-mapping>
Servlet、GenericServlet 以及 HttpServlet 三者之间的关系
servlet的生命周期
servlet 对象的创建
默认是第一次请求到来时 创建Servlet
(通过构造方法)
可以通过xml标记 <load-on-startup>(当其启动时加载)值大于等于0 建议写 1
servlet 对象的初始化
对象创建完成后立即 调用 void init() 完成初始化
servlet 对象的不断的服务
void doGet(HttpServletRequest request,HttpServletResponse response) throws ServletException, IOException //如果浏览器直接请求发送doget void doPost(HttpServletRequest request,HttpServletResponse response) throws ServletException, IOException //当form表单发送psot请求时,调用doPost void service(HttpServletRequest request,HttpServletResponse response) throws ServletException, IOException //既能处理get又能处理post请求
当发送doget请求,只有doPost方法程序会报405
@Override protected void doGet(HttpServletRequest request,HttpServletResponse response) throws ServletException, IOException { doPost(request, response); }
解决
servlet 对象的即将消亡
void destroy()
一旦被调用,则对象进入垃圾回收体系,现在还没有成为垃圾,调用方法才有可能成为垃圾,因为java程序员对垃圾回收权利只有建议
消亡
servlet的线程安全问题
servlet线程不安全原因
同一个请求对应的servlet对象只有1个,当多个servlet 对同一个成员变量进行 写操作时,就会发生线程不安全的问题
如何解决
通过synchronized(this){}
加锁,这样线程排队
为每次方法调用分配独立的变量即可,不做成成员变量
ServletContext对象
什么是ServletContext对象?
在项目部署到web服务器时, 会为这个项目生产一个ServletContext类型的对象. 这个对象可以解决多个servlet之间的信息共享和传递的问题
如何来获取?
request.getServletContext()
或在servet服务方法中 this.getServletContext()
ServletContext的API
设置数据
setAttribute("name",value)
获取数据
setAttribute("name")
删除数据
removeAttribute("name")
aaaaaaa
getRealPath("文件夹名")
获取web.xml中配置全局参数数据
getInitParameter("name");
配置全局参数:
<context-param>上下文参数
<context-name>xx
<context-value>utf-8
ServletConfig对象
什么是ServletConfig 对象?
每一个独立的servlet 对象 都有一个专门的ServletConfig 类型的对象为它服务,这个ServletConfig 类型的对象 可以 获取Servlet对象 的相关信息 和 配置信息。
如何获取?
在servet服务方法中 this.getServletContext()
ServletConfig 的API
getServletName() 获取servlet的名字
指<servlet-name>
getServletContext() 获取servlet 共享信息的对象
getInitParameter("name") 根据name 获取针对这个servlet对象的配置信息
写在<servlet>里 <init-param> <param-name> <param-value>
Servlet请求转发
工作原理
特点
请求转发不支持跨域访问,只能跳转到当前应用中的资源
请求转发之后,浏览器地址栏中的 URL 不会发生变化,因此浏览器不知道在服务器内部发生了转发行为,更无法得知转发的次数
参与请求转发的 Web 资源之间共享同一 request 对象和 response 对象
由于 forward() 方法会先清空 response 缓冲区,因此只有转发到最后一个 Web 资源时,生成的响应才会被发送到客户端
request 域对象
与Context 域对象对比
1) 生命周期不同
2) 作用域不同
3) Web 应用中数量不同
4) 实现数据共享的方式不同
分布式系统及调用
(Enterprise Java Beans)EJB
是运行在独立服务器上的组件,客户端是通过网络对EJB 对象进行调用
EJB集群服务
就是通过RMI的通信,连接不同功能模块的服务器,以实现一个完整的功能
尽量不要使用EJB的情况
简单的纯Web 应用开发,不需要用EJB
与其他服务程序配合使用,调用或返回的网络协议可以解决
较多人并发访问的C/S 结构的应用程序
(Remote Method Invocation)RMI
EJB 技术基础正是RMI,通过RMI实现远程调用
是利用对象序列化机制实现分布式计算,实现远程调用的方法
CORBA
Common Object Request Broker Architecture,通用对象请求代理体系
面向对象分布式应用程序体系规范,异构分布式环境中硬件和软件系统互联的一种解决方案
常用术语
OBR
Object Request Broker,对象请求代理
面向对象的分布式环境中,ORB可以为应用程序、服务器、网络设施之间分发消息提供关键通信设施
是CORBA的核心组件,提供了识别和定位对象、处理连接管理、传送数据和请求通信的框架结构
CORBA对象
是一个“虚拟”的实体,可以有对象请求代理(ORB)定位,并且可以被客户程序请求调用
IOR
可互操作的对象引用:Interoperable Object Reference
存储几乎所有ORB间协议信息,用于建立客户机和目标对象之间的通信,为ORB的互操作提供标准化的对象引用格式
每个IOR包括一个主机名,TCP/IP端口号和一个对象密钥,密钥根据主机名和端口识别目标对象
主要有三部分组成:仓库ID,终点信息和对象密钥
CORBA体系图
CORBA请求调用步骤
(1).定位目标对象
(2).调用服务器应用程序
(3).传递调用所需的参数
(4).必要时,激活调用目标对象的伺服程序
(5).等待请求结束
(6).如果调用成功,返回out/inout参数和将返回值传给客户机
(7).如果调用失败,返回一个异常给客户机
特征
实现了分布式系统下跨平台,跨语言的数据的传输
实现了远程方法的本地调用(在本地调用远程Server上的方法并取得返回值)
异构式分布式系统原则
寻求独立于平台的模型和抽象
在不牺牲太多性能的前提下,尽可能隐藏底层的复杂细节
其他
Java特性
与C++比较
C++ 支持指针,而 Java 没有指针的概念
C++ 支持多继承,而 Java 不支持多重继承
Java 是完全面向对象的语言
Java 自动进行内存回收,而 C++ 中必须由程序释放内存资源
Java 不支持操作符重载,而操作符重载则被认为是 C++ 的突出特征
Java 允许预处理,但不支持预处理器功能,为了实现预处理引入语句(import)
Java 不支持缺省参数函数,而C++支持
C 和 C++ 不支持字符串变量
Java 不提供 goto 语句
Java 不支持 C++ 中的自动强制类型转换
快速失败(fail-fast)
默认指的是Java集合的一种错误检测机制
当多个线程对部分集合进行结构上的改变的操作时,有可能会产生fail-fast机制
工具
源码编辑
Notepad++
EditPlus
UltraEdit
Sublime Text
Vim
IDE
Eclipse IDE
MyEclipse
Intellij IDEA
NetBeans
Servlet容器/服务器
Tomcat
结构图
Jboss
Jetty
WebSphere
WebLogic
GlassFish
代码生成
Xdoclet
压缩算法
Gzip
高压缩率,慢速
deflate
deflate(lvl=1)
低压缩率,快速
。。。
deflate(lvl=9)
高压缩率,慢速
Bzip2
LZMA
XZ
LZ4
LZ4(high)
LZ4(fast)
很快,可达320M/S
LZO
Snappy
Snappy(framed)
Snappy(normal)
编程思想及设计模式
设计原则
单一职责原则
开闭原则(Open-Closed Principle)
里氏代替原则(Liskov Substitution Principle)
依赖倒置原则
接口隔离原则
合成复用原则
迪米特法则
设计模式
创建型模式
(1)单例模式(Singleton)
(2)简单工厂模式(SimpleFactory)
(3)工厂方法模式(FactoryMothod)
(4)抽象工厂模式(AbstratorFactory)
(5)建造者模式(Builder Pattern)
(6)原型模式(Prototype Pattern)
结构型模式
(7)适配器模式(Adapter Pattern)
(8)桥接模式(Bridge Pattern)
(9)装饰者模式(Decorator Pattern)
(10)组合模式(Composite Pattern)
(11)外观模式(Facade Pattern)
(12)享元模式(Flyweight Pattern)
(13)代理模式(Proxy Pattern)
行为型模式
(14)模板方法模式(Template Method)
(15)命令模式(Command Pattern)
(16)迭代器模式(Iterator Pattern)
(17)观察者模式(Observer Pattern)
(18)中介者模式(Mediator Pattern)
(19)状态者模式(State Pattern)
(20)策略者模式(Stragety Pattern)
(21)责任链模式
(22)访问者模式(Vistor Pattern)
(23)备忘录模式(Memento Pattern)
(24)解释器模式
编程思想
AOP 面向切面
介绍
关注点分离:不同的问题交给不同的部分去解决
面向切面编程AOP就是这种技术的体现
通用化的功能实现,对应的 就是所谓的切面(Aspect)
业务功能代码和切面代码分开后,架构将变得高内聚,低耦合
确保功能的完整性,切面最终需要被整合到业务中(Weave,编入)
AOP三种织入的方式
编译时织入(静态代理)
需要特殊的Java编译器,入AspectJ
类加载时候织入
需要特殊的Java编译器,如AspactJ,AspectWerkz
运行时织入(动态代理)
动态代理就是说AOP框架不会去修改字节码,而是在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
Spring采用这种方式,通过动态代理,实现简单
Spring AOP
JDK动态代理
通过反射来接收被代理的类,且要求被代理的类必须实现一个接口。
InvocationHandler 接口 Proxy.newProxyInstance()
CGLIB动态代理
是一个代码生成的类库,可以在运行时动态的生成某个类的子类
通过继承 的方式做 动态代理,因此如果某个类被标记为 final, 那么它是无法使用CGLIB做动态代理的
MethodInterceptor 接口 Enhancer 类
AOP主要名词概念
Aspect
切面:通用功能的代码是实现
Target
目标:被织入Aspect对象
Join point
可以作为切入点的机会,所有的方法都可以作为切入点
Pointcut
定义Aspect实际被应用在的Join Point,支持正则
Advice
类里的方法以及这个方法如何织入到目标方法的方式
分类
前置通知Before
后置通知AfterRunning
异常通知AfterThrowing
最终通知 After
环绕通知 Around
Weaving
AOP实现的过程
JDKProxy,Cglib 来生成代理对象
具体由AopProxyFactory 根据AdvisedSupport对象的配置来决定
策略是如果目标是接口,则默认使用JDKProxy来实现,否则使用后者
JDKProxy
JDK动态代理是代理模式的一种实现方式,通过反射接收要代理的类,并且要求要代理的类必须要实现接口
JDKProxy核心
InvocationHandler接口和 Proxy类
反射机制在生成类的过程中比较高效
Cglib
以继承的方式实现目标类的代理,底层借助ASM实现
如果目标类被设置为final 而无法继承 则无法使用Cglib动态代理
ASM在生成类之后执行过程比较高效
代理模式
接口+真实实现类+代理类
Spring里的代理实现
真实实现类的逻辑包含在getBean方法里
getBean方法返回的实际上是Proxy的实例
Proxy实例是Spring 采用JDKProxy或者是Cglib动态生成的
IOC 控制 反转
Spring Core 最核心部分
Dependency Inversion 依赖注入
举例:上层建筑依赖下层建筑,这样的代码几乎不可维护 想修改轮子,你得修改所有的类

依赖注入的含义: 将底层类作为参数 传递给上层类,实现上层对下层的 “控制”

注入方式
Set注入
接口注入
注解注入
构造器注入
IOC容器优势
避免在各处使用new 来创建类,并且可以做到统一维护
在创建实例的过程中,不需要了解其中的细节
项目启动时发生了什么
1.Spring 启动时,回读取应用程序提供的Bean信息 .2.将读取到的bean 配置信息,生成一个bean配置的注册表 3.根据这个bean的注册表 去实例化bean,装配好bean的依赖关系,为上层提供准备就绪的运行环境。 4.利用java 的反射功能实例化bean,并建立bean之间的依赖关系

IOC支持哪些功能
依赖注入
依赖检查
自动装配
支持集合
制定初始方法 和销毁方法
支持回调某些方法
Spring IOC 容器核心接口
BeanFactory
提供了IOC的配置机制
包含了bean的各种定义,便于实例化bean
建立bean之间的依赖关系
bean的生命周期控制

ApplicationContext
继承了多个接口
BeanFactory
能够管理、装配Bean
ResourcePatternResolver
能够加载资源文件
MessageSource
能够实现国际化相关功能
ApplicationEventPublisher
能够注册监听器,实现监听机制
BeanDefinition
主要用来描述bean定义
BeanDefinitionRegistry
提供向IOC容器注册BeanDefinition对象的方法
BeanFactory 和ApplicationContext 比较
BeanFactory是Spring 的基础设施 ApplicationContext是面向Spring框架的开发者
refresh方法
为IOC容器以及Bean的生命周期管理提供条件
刷新Spring上下文信息,定义Spring上下文加载流程
getBean方法
转换beanName
从缓存加载实例
实例化bean
检测parentBeanFactory
初始化依赖的bean
创建bean
常见面试题
Spring Bean 的作用域
singleton
Spring 容器默认的作用域,容器里会有唯一的Bean实例
适合无状态的bean
prototype
针对每个getBean请求,容器都会创建一个新的Bean实例
适合有状态的bean
request
会为每个Http请求创建一个Bean实例
session
会为每个Session创建一个Bean实例
globalSession
会为每个全局Http Session创建一个Bean实例, 该作用域仅对Portlet生效
web容器额外支持
Bean的生命周期
实例化Bean
Aware(注入Bean ID,BeanFactory,AppCtx)
Aware接口声明依赖关系
BeanPostProcessor(s) postProcessBeforeInitalization
前置初始化方法 咋Spring完成实例化之后, 对Spring容器实例化的Bean 添加一些自定义处理逻辑
InitializingBeans(s).afterPropertiesSet
定制的bean.init方法
BeanPosProcessor(s). postProcessAfterInitalization
后置初始化方法 去实现bean初始化完成之后 自定义的操作
bean初始化完毕
Bean的创建
bean的销毁过程
如果实现了DisposableBean接口,则会调用destroy方法
若配置了destroy-method属性,则会调用期配置的销毁方法
Bean的销毁
Java基础进阶
理论基础
栈(stack)、堆(heap)和方法区(method area)
基本数据类型的变量,对象的引用,函数调用的保存都使用JVM中的栈空间
通过new关键字和构造器创建的对象则放在堆空间
方法区和堆都是各个线程共享的内存区域,用于存储已经被JVM加载的类信息、常量、静态变量、JIT编译器编译后的代码等
栈空间操作起来最快但是栈很小,通常大量的对象都是放在堆空间
栈和堆的大小都可以通过JVM的启动参数来进行调整
栈空间用光了会引发StackOverflowError,而堆和常量池空间不足则会引发OutOfMemoryError
基本类型和包装类型
包装类型可以为 null,而基本类型不可以
包装类型可用于泛型,而基本类型不可以
基本类型比包装类型更高效
基本类型在栈中直接存储的具体数值,而包装类型则存储的是堆中的引用
两个包装类型的值可以相同,但却不相等
Integer chenmo = new Integer(10); Integer wanger = new Integer(10); System.out.println(chenmo == wanger); // false System.out.println(chenmo.equals(wanger )); // true
装箱与拆箱
把基本类型转换成包装类型的过程叫做装箱(boxing)
把包装类型转换成基本类型的过程叫做拆箱(unboxing)
String和StringBuilder、StringBuffer
String是只读字符串,也就意味着String引用的字符串内容是不能被改变的
StringBuffer/StringBuilder类表示的字符串对象可以直接进行修改
StringBuilder它是在单线程下使用的,线程不安全,但性能远大于StringBuffer
final、finally、finalize
final
如果一个类被声明为final,意味着它不能再派生出新的子类,即不能被继承,和abstract是反义词
变量声明为final,可以保证它们在使用中不被改变
finally
通常放在try…catch…的后面构造总是执行代码块,这就意味着程序无论正常执行还是发生异常,这里的代码只要JVM不关闭都能执行
finalize
Java中允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作
static final/final static
static final修饰的属性表示一旦给值,就不可修改,并且可以通过类名访问
static final修饰方法,表示该方法不能重写,可以在不new对象的情况下调用
==和hashCode和equals方法
equals()才能确认是否真的相等
Object类中默认的实现方式是 : return this == obj 。只有this 和 obj引用同一个对象,才会返回true。
重写equals
自反性: x.equals(x) 一定是true
对null: x.equals(null) 一定是false
对称性: x.equals(y) 和 y.equals(x)结果一致
传递性: a 和 b equals , b 和 c equals,那么 a 和 c也一定equals。
一致性: 在某个运行时期间,2个对象的状态的改变不会不影响equals的决策结果
hashCode()用来缩小寻找范围
重写equals,也必须重写hashCode
参与equals函数的字段,也必须都参与hashCode 的计算
等价的(调用equals返回true)对象必须产生相同的散列码。不等价的对象,不要求产生的散列码不相同
equals中衡量相等的字段参入散列运算,每一个重要字段都会产生一个hash分量,为最终的hash值做出贡献
==判断对象地址是否相等
RPC方面
Protocol Buffer 的序列化 & 反序列化简单 & 速度快的原因是
1. 编码 / 解码 方式简单(只需要简单的数学运算 = 位移等等)
2. 采用 Protocol Buffer 自身的框架代码 和 编译器 共同完成
Protocol Buffer 的数据压缩效果好(即序列化后的数据量体积小)的原因是:
1. a. 采用了独特的编码方式,如 Varint、Zigzag 编码方式等等
2. b. 采用 T - L - V 的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑
数据库
INNODB 的可重复读,采用了哪些巧妙的方式避免了幻读
表象快照读(非阻塞读),伪MVCC
内在 next-key锁+ gap锁
需要了解下Redo Log