导图社区 第一单元 中华人民共和国的成立和巩固
第一单元 中华人民共和国的成立和巩固
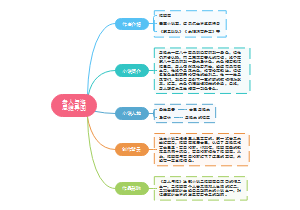
八年级下册历史第一单元课本全重点时间轴梳理,大事件时间轴,1949年开国大典天安门,1959年西藏民主改革,消灭封建农奴制度。
编辑于2023-02-25 11:05:52 北京市- 八年级下…
- 相似推荐
- 大纲
导图社区 第一单元 中华人民共和国的成立和巩固
八年级下册历史第一单元课本全重点时间轴梳理,大事件时间轴,1949年开国大典天安门,1959年西藏民主改革,消灭封建农奴制度。
编辑于2023-02-25 11:05:52 北京市