导图社区 数量 CFA Level 2
数量 CFA Level 25%-10%的思维导图,内容包含线性回归介绍、多元线性回归、时间序列分析、机器学习、大数据。
注册金融分析师 CFA Level 3 全部内容,包含行为金融、资本市场预期、资产配置、衍生品和外汇管理、固定收益组合管理、私人财富管理、机构投资者、交易执行、业绩评估及基金经理选择、案例分析技巧、伦理与职业标准。
FRM1-风险管理基础的思维导图,分享了基础知识、投资组合管理、高级风险管理、风险案例、道德的内容,一起来看。
FRM1-估值与风险建模的思维导图,介绍了basic、价格、yield & return、利率、期限结构非平行移动、MBS、利率衍生品、市场风险、信用风险等知识。
社区模板帮助中心,点此进入>>
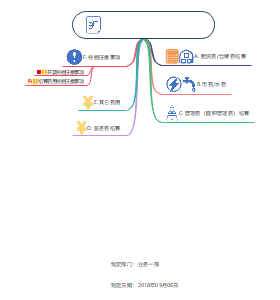
安全教育的重要性
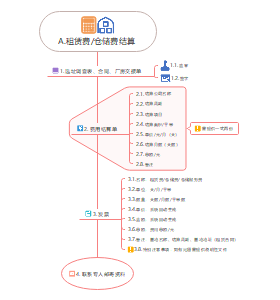
费用结算流程
租赁费仓储费结算
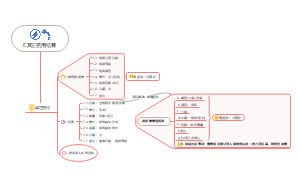
E其它费用
F1开票注意事项
F2结算费用特别注意事项
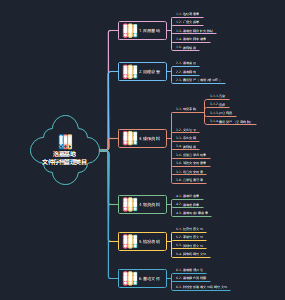
洛嘉基地文件存档管理类目
个人日常活动安排思维导图
西游记主要人物性格分析
CFA一级Ethics-standard思维导图
数量 5%-10%
线性回归介绍
基础假设
x, y线性关系
x和残差无关
残差期望为0
所有观察值残差项方差为常量
残差项分布独立
残差正态分布
残差假设
回归模型
“^”表示预测值
截距intercept,表示风险调整后收益,ex-post alpha
斜率slope coefficient, 市场性风险
SSE: sum of squared errors 残差(估计值-实际值)的标准差,线性回归是使得SSE最小的线
回归线过
参数检验
指标
标准误SEE
standard error of estimate ,标准误,衡量y和的变化程度,计量拟合程度,越小越好
多次抽样中样本均值间的离散程度,反映样本均值对总体均值的代表性
决定系数(coefficient of determination): y的变动能被x解释的百分比
对于一元线性回归,等于相关系数平方
多元回归时不成立
方差分析(ANOVA, analysis of variance)
SST, total sum of squares 衡量实际值与平均值之间的总变动,实际值-平均值的平方和
RSS, Regression sum of squares 衡量能被x解释的y变动,用回归求出的部分是能被解释的,预测值-平均值平方和
SSE, Sum of squared errors残差平方和:衡量不可解释的变动,实际值-预测值平方和,实际值和预测值有差异的部分是没被回归方程所解释的,所以形成偏差
SST=RSS + SSE
残差标准差,实际观测值偏离回归线程度
回归分析缺点
参数不稳定,线性关系可能随时间变化
其他市场参与者也使用相同模型会限制模型的有效性
回归分析假设需成立,不然有heteroskedastic(残差方差非常数)和autocorrelation(残差项不独立)
多元线性回归
模型
截距:x都为0时的y
斜率:其他x不变(holding xxx constant),制定x变化导致y的变化幅度
参数显著性检验
检验统计量
假设检验,服从t(n-k-1)
n→观测值数量;k→x的数量;1→截距数量
将计算得出的检验统计量与查表得到的critical value作比较得出结论
p-value
将critical value与p-value作比较,p-value< critical value拒绝原假设,考试中有p-value优先用p-value
置信区间
F(k, n-k-1)检验
主要用于多元线性回归,检验至少有1个x显著解释了Y
单尾
多元线性回归中,数值随回归方程中x数量增加而增加
哑变量dummy variables
取“是”,“否”等特定值
哑变量陷阱,n个取值,只需要n-1个变量
截距代表omitted category的值
斜率代表由哑变量和omitted category差异引起的y-dependent variable的变动
违反假设的情形
Heteroskedasticity 异方差
定义:样本点间残差方差不同
类型
unconditional heteroskedasticity:与x变化无关,对回归无重大影响
conditional heteroskedasticity:残差随x的变而变,对统计推断产生重大影响
影响
检测
方法1:散点图
方法2:卡方检验
纠正
方法1:计算white-corrected standard error also called robust/heteroskedasticity-consistent standard error
方法2:计算generalized least squares
Serial correlation(i.e., autocorrelation) 自相关
定义:残差之间相关,在时间序列中常见
正自相关positive serial correlation:当前一期正回归错误增加下一期正回归错误概率
负自相关negative serial correlation:当前一期正回归错误增加下一期负回归错误概率
散点图residual plot
DW(Durbin-Watson) statistic
r是当前和之前一期残差相关系数
方法1:调整标准误:只有异方差,用white-corrected标准误;有自相关或两者都有用Hansen method
方法2:改进模型,如加入时间特性项,如季节
Multicollinearity 多重共线性
定义:自变量之间or自变量组合之间相关
完全多重共线性
一个变量能由其他解释变量的线性组合表达
无法用OLS方法估计系数
不完全多重共线性
两个or两个以上自变量之间高度相关
不影响OLS方法使用,但会导致至少一个自变量系数估计量有较大偏误
不影响β1的无偏性,导致较大的var(β1)
产生type II错误,经济模型中常见
t-test发现没有系数显著不同于0,但F-test显示显著,且R方高
x之间高相关,表明多重共线性可能性高;但x之间低相关不能表明多重共线性不存在,可能是x之间的线性组合有相关性
忽略1个or多个相关的自变量,逐步回归stepwise regression
模型设定偏误model misspecification
对估计系数的统计推断有误
估计系数不具备一致性
函数形式错误
遗漏重要变量
错误函数形式
错误融合不同样本数据
自变量与残差项相关
自变量中包含因变量的滞后项
自变量是因变量的某种函数形式
自变量的度量存在偏误
时间序列设定错误
模型设定原则
需有一定依据,避免数据挖掘偏差
变量函数形式必须符合该变量数据的实际特征
疏松parsimonious:有效且简单
符合6大假设
样本外数据监测通过
定性因变量qualitative dependent
哑变量
回归方法
概率单位模型probit model
对数单位模型logit model
估计因变量取1的概率
判别分析法discriminant models
如Z-score
时间序列分析
趋势模型
线性趋势模型(通胀)
变量按固定数量增长用线性模型
对数线性趋势模型(股价&股指)
变量按固定比率增长用对数模型
局限性
对数线性模型不适合应用于自相关数据
自回归模型autoregressive model, AR
定义
用一个或多个过去的y预测当前y
协方差平稳
成立的条件
期望是常数且有限
方差是常数且有限
leading和lagging value之间的协方差是常数且有限
周期性
序列相关性检验
需满足回归假设:残差项不存在序列相关
自相关系数autocorrelation
k阶自相关系数:时间序列y在t时刻与t-k时刻之间相关系数
检验残差项之间的各阶自相关系数是否显著不为0
构建并估计AR(1)模型
计算残差项之间相关系数
检验残差的各阶相关系数是否显著不为0
T是期数-1
均值复归mean reversion
低于均值涨到均值,高于均值跌到均值
均值回归水平mean-reverting level
模型预测
RMSE(root mean squared error)均方误差越低越好
选取时间周期不同,系数不同,不稳定
随机游走
不具备均值复归特性
带漂移的随机游走 random walk with drift
性质
均值回归水平无穷
单位根(unit root )
不协方差平稳
检测协方差平稳
子主题
解决
一阶差分 first differencing
对y应用自回归模型AR(1)
单位根
判断时间序列是否平稳
AR(1)模型中β1绝对值大于等于1,则时间序列不平稳
Dickey Fuller test
如果差分后的时间序列平稳,那么通过AR(1)模型得到的统计推断结论是可靠的
原假设:有单位根
季节性因素
每年重复的pattern 需要将季节性因素加入到AR model中
Lag4 t统计量显著不为0,表示lag4有季节性,需要加入到模型
仍为AR(1)不是AR(2)
条件异方差自回归模型ARCH model
当期残差的方差依赖于前一期残差的方差 此时AR model 系数的标准误和假设检验都不准
解决←问题,引入ARCH model
ARCH(1) regression model:用t-1时残差方差预测t时残差方差
原假设:a1=0
协整cointegrated
两个时间序列相关于共同的宏观变量,趋势相同且不变
长期关系
用一个时间序列预测另一个时间序列
使用DF-EG test 检验协整,原假设:unit root,拒绝原假设表示协方差平稳且协整,协整就可以使用线性回归model两个时间序列关系
机器学习
分类
有监督学习:supervised learning
惩罚回归penalized regression
正则化regularization
LASSO回归
支持向量机SVM
适用回归和分类问题
思想:类间margin最大,形成分隔超平面
K临近,K-nearest neighbor
思想:目标x附近最多的类别与x是同一类
分类回归树classification and regression tree,CART
分支bifurcate
集成学习与随机森林ensemble learning and random forest
投票分类
Bootstrap aggregation,Bagging
抽样n次形成n个模型训练
有助于防止过拟合,n次去除小概率事件
随机森林
多个CART投票
无监督学习:unsupervised learning
主成分分析PCA,principal component analysis
降维,正交分解
分层聚类
分裂聚类divisive clustering/hierarchical clustering,自上而下聚类
合并聚类agglomerative clustering,自下而上聚类
同类样本间距离尽可能小,不同类别间距离尽可能大
K均值,k-means
自上而下聚类
步骤
选k个质心
计算每个数据点到质心距离,归为距离最近的类
更新质心,定义为上一步不同类的均值点
变化小的话停止更新
深度学习 deep learning
分层
输入层
输出层
隐藏层
特征
激活函数activation function
每层权重值
超参数
增强学习 reinforced learning:从自身错误中学习
行动结果的奖惩制度,训练模型
alphaGo
模型评估
过拟合overfitting
欠拟合underfitting
评估错误率
数据集
训练集(训练模型)
样本内
验证集(验证调试模型)
测试集(新数据评估模型)
样本外
错误
偏差bias error
样本内,训练集,欠拟合
方差 variance error
样本外,验证集,过拟合
模型复杂度↑,方差↑,偏差↑
基本偏差 base error
随机噪声的残差
大数据
3V:volume大量,variety来源广,velocity数据产生速度快;可能还有准确veracity
结构化数据建模
对要建模的task有概念
收集数据
数据准备和整理wrangling
准备
数据不完整incompleteness
缺失值missing value
数据不准确inaccuracy
数据不一致
前后不一致
非标准错误non-uniformity
格式不统一
重复数据
整理
数据提炼extraction
构造新变量
加总aggregation
相加得出新变量
过滤
去除不需要的数据 列
选择
去掉不需要的数据 行
转换
转换为合适的数据类型
异常值处理outlier
3倍标准差之外
3倍IQR之外
IQR:75%-25%分位数的差值
认定
处理
截尾trimming:删除异常值
缩尾winsorization:将异常值用非异常值的最大最小值代替
数据标准化
正规化normalization
标准化standardization
数据探索
探索性数据分析EDA
数据可视化
均值、方差等
特征选择
反复迭代选择最有影响力特征
模型解释力和算法速度的抉择
特征工程
构建特征
one-hot encoding分类数据处理为二进制表示的数据(dummy)
训练模型
模型选择
考虑监督/非监督、数据类型、数据类型、数据大小
数值型-CART;文本型-广义线性模型GLMs/SVM;图像数据-深度模型
性能评估
调优tuning
不平衡数据集,使用过采样或者降采样
非结构化数据建模
文本分析:确定输入输出
数据护理data curation
文本数据准备与整理
去除HTML标签、标点、数字、空白符
整理wrangling
文本转小写
删除停用词
词干提取steamming
取词根
词形还原lemmatization
doing→do
词袋bags-of-words, BOW 词的无序集合
文本特征分析
document term matrix: 行是文档,列是单词,格子是词出现在某文档出现次数
N-gram: 一个句子中n个词一分割,2-gram 两两分隔,3个单词的句子产生2个gram
文本探索
EDA
词频term frequency;词云等
error analysis
混淆矩阵confusion matrix
ROC, receiver operating characteristic
RMSE, root mean square error
模型调优tuning
平衡方差/偏差、正则化、网格搜索、上限分析(ceiling analysis识别优化建模过程中的每一步)