导图社区 第5章 投资性房地产
第5章 投资性房地产
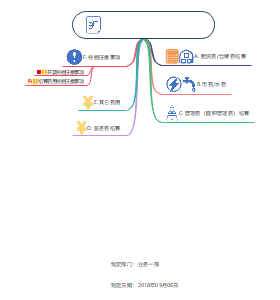
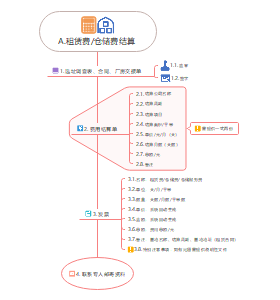
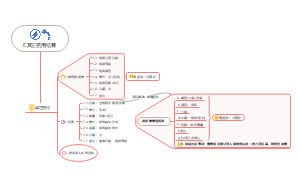
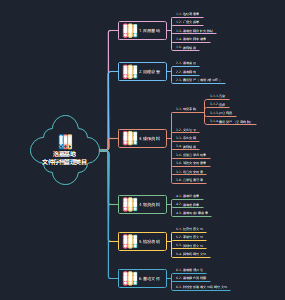
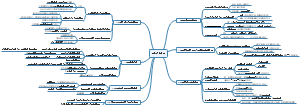
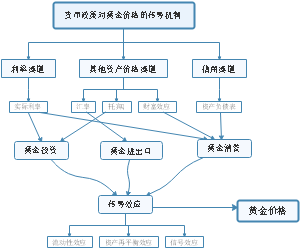
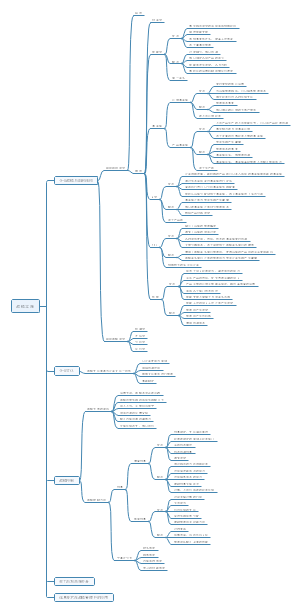
这是一篇关于第5章 投资性房地产的思维导图,主要内容包括:范围,不属于投资性房地产,转换日的确定,初始计量,成本模式,公允价值模式,投资性房地产业务对损益的影响。
编辑于2025-06-17 16:20:53- 相似推荐
- 大纲
导图社区 第5章 投资性房地产
这是一篇关于第5章 投资性房地产的思维导图,主要内容包括:范围,不属于投资性房地产,转换日的确定,初始计量,成本模式,公允价值模式,投资性房地产业务对损益的影响。
编辑于2025-06-17 16:20:53