导图社区 八下第一单元SA
八下第一单元SA的思维导图,整理了如何询问他人状态、如何描述自己的状态、如何发表建议的内容,大家可以学起来哦。
社区模板帮助中心,点此进入>>
《老人与海》思维导图
《钢铁是怎样炼成的》章节概要图
《傅雷家书》思维导图
《西游记》思维导图
《水浒传》思维导图
《茶馆》思维导图
《朝花夕拾》篇目思维导图
《红星照耀中国》书籍介绍思维导图
初中物理质量与密度课程导图
桃花源记思维导图
U1SA
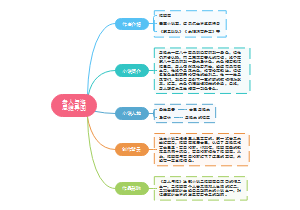
如何询问他人状态
What's the matter(with sb.)?
What's the happen to you?
What's the trouble with sb.?
what' up
Do/Does you/he/she/them+疾病?
以下来源于网络
What hurts you?你那里痛?
What sort of pain do you get there?您什么地方痛?
How're you feeling now?您现在感觉怎么样了?
How long has it been this way?这样多久 了?
Do you feel better?你感觉好点了吗?
How do you feel?你觉得如何
Are you feeling better? 你感觉好点了吗?
How are you today? 你今天感觉怎么样?
如何描述自己的状态
表达疾病
身体部位+ache
headache
earache
toothache
backache
waistache(腰痛)
heartache
faceache(颜面神经痛)
tongueache(舌痛)
legache(腿痛)
stomachache
have a sore...
have a sore back
have a sore throat
have a/an/the+疾病
have a cough
have a cold
have the flu
hurt+oneself(伤到某人自己)
ill
可做定语不可做表语
sick
可做表语与定语
句型
I have ....
take/catch:均可表示“生病”,且含有“感染”之意。
get: 常作“生病”讲,后接表示疾病的名词。
(be) ill with: 如表示“患......病”的时候后面须跟with
(be) sick with,与be ill with可以相互替换,但sick with不能改为sick of。
fall ill(sick) with; fall ill(sick): 表示“患......病”时,后面须加with
be troubled with: 意为“患......病”。
如何发表建议
You/He/She/They should/may/must/need to/have to+具体措施
You/He/She/They shouldn't/may not/mustn't/needn't to/haven't to
方法
cold/cough/throat/
drink hot water
fever
take temperature
go to the/a dentist
hurt oneself
put some medicine/a bandage on it
backache/sore back/neck
lie down and rest
fracture(骨折)
take an X-ray
stomaache
ate some medicine