导图社区 高中政治思维导图
这是一篇关于人教版高一必修一政治第三课 只有中国特色社会主义才能发展中国思维导图。该思维导图比较系统全面地归纳总结了关于这一部分的知识点。
这是一篇关于人教版高一政治必修一第二课思维导图。该思维导图主要涉及经济生活的知识点,并对此作了归纳总结。
社区模板帮助中心,点此进入>>
《老人与海》思维导图
《钢铁是怎样炼成的》章节概要图
《傅雷家书》思维导图
《阿房宫赋》思维导图
《西游记》思维导图
《水浒传》思维导图
《茶馆》思维导图
《朝花夕拾》篇目思维导图
英语词性
生物必修一
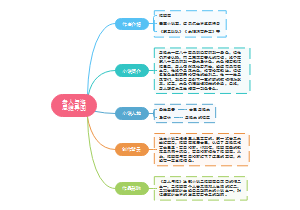
第三课 只有中国特色社会主义才能发展中国
伟大的改革开放
改革开放的进程
十一届三中全会做出的重要决定及其意义
①重要决定:1978年12月召开的党的十一届三中全会重新确立了马克思主义的思想路线、政治路线和组织路线, 确定把党和国家工作的重心转移到社会主义现代化建设上来,作出实行改革开放的重大决策。 ②意义:实现了中华人民共和国成立以来党的历史上具有深远意义的伟大转折,开启了改革开放和社会主义现代化 建设新时期。
1992年我国对外开放格局
全方位、多层次、宽领域
改革开放的意义
①改革开放极大改变了中国的面貌,中华民族的面貌,中国人民的面貌,中国共产党的面貌,中华民族迎来了从站 起来,富起来到强起来的伟大飞跃,中国特色社会主义迎来了从创立,发展到完善的伟大飞跃,中国人民迎来了 从温饱不足到小康富裕的伟大飞跃。 ②实践充分证明,改革开放是党和人民大踏步赶上时代的重要法宝,是坚持和发展中国特色社会主义的必由之路, 是决定当代中国命运的关键一招,也是决定实现“两个一百年”奋斗目标、实现中国中华民族伟大复兴的关键一招
中国特色社会主义的创立、发展和完善
改革开放以来,党的全部理论和实践的主题
中国特色社会主义是改革开放以来党的全部理论和实践的主题,是党和人民历尽千辛万苦,付出巨大代价取得的根本成就
①党的十一届三中全会以后以邓小平同志为主要代表的中国共产党人创立了 邓小平理论,成功开创了中国特色社会主义。 ②党的十三届四中全会以后,以江泽民同志为主要代表的中国共产党人,形 成了三个代表重要思想,成功把中国特色社会主义推向21世纪。(三个代 表:代表中国先进生产力的发展要求,代表中国先进文化的前进方向,代 表中国最广大人民的根本利益) ③党的十六大以后,以胡锦涛同志为主要代表的中国共产党人,形成了科学 发展观,成功在新的历史起点上坚持和发展了中国特色社会(科学发展观 :第一要义是发展,核心是以人为本,基本要求是全面协调可持续,根本 方法是统筹兼顾) ④党的十八大以来,以***同志为主要代表的中国共产党人,创立了习近 平新时代中国特色社会主义思想,中国特色社会主义进入了新时代。
中国特色社会主义道路、理论、制度、文化
改革开放以来,我国取得一切成绩和进步的根本原因
中国共产党带领全国人民,开辟了中国特色社会主义道路,形成了中国特色社会主义理论体系,确立了中国特色社会主义制度,发展了中国特色社会主义文化。
中国特色社会主义道路的含义
中国特色社会主义道路,就是在中国共产党领导下,立足基本国情,以经济建设为中心,坚持四项基本原则,坚持改革开放,解放和发展社会生产力,建设社会主义市场经济、社会主义民主政治、社会主义先进文化、社会主义和谐社会、社会主义生态文明,促进人的全面发展,逐步实现全体人民共同富裕,建设富强民主文明和谐美丽的社会主义现代化强国。
中国特色社会主义道路的重要性
中国特色社会主义道路是实现社会主义现代化、创造人民美好生活的必由之路,是实现中华民族伟大复兴的必由之路。实践证明,中国特色社会主义道路是一条既符合中国国情,又适合时代发展要求并取得巨大成功的唯一正确道路。
中国特色社会主义理论体系
包括邓小平理论、“三个代表”重要思想、科学发展观、***新时代中国特色社会主义思想。
是指导党和人民实现中华民族伟大复兴的正确理论,是立足时代前沿、与时俱进的科学理论。赋予马克思主义新的鲜活力量,写出了科学社会主义的“新版本”。
制度对一个国家的重要意义
我国国家治理体系和治理能力是中国特色社会主义制度及其执行能力的集中体现。制度优势是一个国家的最大优势。制度竞争是国家间最根本的竞争。制度稳则国家稳。
如何发展中国特色社会主义文化?
以马克思主义为指导,坚守中华文化立场,立足当代中国现实,结合当今时代条件,发展面向现代化、面向世界、面向未来的,民族的科学的大众的社会主义文化,推动社会主义精神文明和物质文明协调发展。
如何坚持中国特色社会主义?
①中国特色社会主义道路、理论、制度、文化相互联系、相互作用,统一于中国特色社会主义伟大实践。 ②我们要始终高举中国特色社会主义伟大旗帜,坚定道路自信、理论自信、制度自信、文化自信