导图社区 初中化学知识点总结——化学与生活,化学与能源
初中化学知识点总结——化学与生活,化学与能源
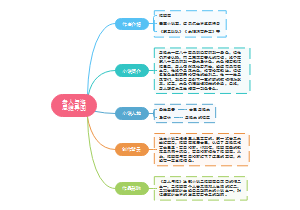
这是一篇关于化学的思维导图。化学与生活第三章 化学与能源 本章主要内容 能源概述常规能源新能源生物质能源化学电源 ,可以作为学习笔记和复习资料,帮助大家系统地回顾和巩固所学知识,学生更好地理解和记忆知识。
提示: 本内容由社区用户上传并分享。平台不对内容的真实性、合法性、知识产权归属及是否侵害第三方权利进行事前审核或保证。本内容可能包含受版权保护的图片、字体或其他第三方素材,使用前请自行确认授权范围。
- 图形与几何
【图形与几何:探索形状的奥秘】 从平面到立体,图形世界充满规律!三角形按最大内角分为锐角、直角和钝角四边形包含平行四边形、梯形等特殊类型,面积公式各异立体图形中,正方体(V=a³)和长方体(V=abh)的体积与表面积公式简洁实用梯形分等腰与直角,平行四边形含长方形和正方形,对角线特性鲜明周长与面积是核心指标,如三角形C=三边和,S=底×高÷2分类与定义揭示图形的本质,快来一起发现几何的魅力!
- 《简爱》人物关系图
简爱中各人物之间的关系简略图(较全),《简·爱》是夏洛蒂·勃朗特创作的一部经典小说,通过主人公简·爱的一生,展现了她在逆境中不屈不挠、追求自由平等与尊严的精神。人物关系图能够帮助读者清晰地梳理出小说中的主要人物及其相互关系,进而更好地理解故事的发展脉络和情节走向。通过这张图,读者可以一目了然地看到简·爱与罗切斯特先生、圣约翰·里弗斯、海伦·彭斯、里德太太等关键人物之间的复杂关系,以及这些关系如何推动故事向前发展。
- 初中化学知识点总结——物质的组成及分类
这是一篇关于物质的组成及分类的思维导图。 物质的组成构成及分类 组成:物质纯净物由元素组成只有一种分子或原子有固定的组成,有化学式 原子:金属稀有气体碳硅等。
初中化学知识点总结——化学与生活,化学与能源
社区模板帮助中心,点此进入>>
- 图形与几何
【图形与几何:探索形状的奥秘】 从平面到立体,图形世界充满规律!三角形按最大内角分为锐角、直角和钝角四边形包含平行四边形、梯形等特殊类型,面积公式各异立体图形中,正方体(V=a³)和长方体(V=abh)的体积与表面积公式简洁实用梯形分等腰与直角,平行四边形含长方形和正方形,对角线特性鲜明周长与面积是核心指标,如三角形C=三边和,S=底×高÷2分类与定义揭示图形的本质,快来一起发现几何的魅力!
- 《简爱》人物关系图
简爱中各人物之间的关系简略图(较全),《简·爱》是夏洛蒂·勃朗特创作的一部经典小说,通过主人公简·爱的一生,展现了她在逆境中不屈不挠、追求自由平等与尊严的精神。人物关系图能够帮助读者清晰地梳理出小说中的主要人物及其相互关系,进而更好地理解故事的发展脉络和情节走向。通过这张图,读者可以一目了然地看到简·爱与罗切斯特先生、圣约翰·里弗斯、海伦·彭斯、里德太太等关键人物之间的复杂关系,以及这些关系如何推动故事向前发展。
- 初中化学知识点总结——物质的组成及分类
这是一篇关于物质的组成及分类的思维导图。 物质的组成构成及分类 组成:物质纯净物由元素组成只有一种分子或原子有固定的组成,有化学式 原子:金属稀有气体碳硅等。
- 相似推荐
- 大纲