导图社区 Java技能树
- 23.7k
- 631
- 96
- 举报
Java技能树
一张思维导图带你快速入门!下图整理了Java技能树的相关内容,包括前端及脚本语言、框架、语言、测试、安全、服务器和操作系统等。掌握这份导图中的知识,零基础也能轻松学习Java!
提示: 本内容由社区用户上传并分享。平台不对内容的真实性、合法性、知识产权归属及是否侵害第三方权利进行事前审核或保证。本内容可能包含受版权保护的图片、字体或其他第三方素材,使用前请自行确认授权范围。
- 技能树
 程序猿知识技能总结 含16个作品
程序猿知识技能总结 含16个作品程序猿知识技能总结大全,java、python、正则表达式、Linux等多方面知识导图
 运营基础知识总结、书籍汇总 含13个作品
运营基础知识总结、书籍汇总 含13个作品包含抖音运营、短视频运营要点、运营之光、从零开始做运营、学会写作等多个运营读书笔记、运营知识框架等
 产品、运营、程序猿常用工具汇总 含5个作品
产品、运营、程序猿常用工具汇总 含5个作品产品、运营工具包大全:办公工具、文字工具、音频工具、视频工具、社群工具、公众号辅助工具、排版工具、图片工具、H5工具、小程序工具等
- 2026年最新版视频号知识地图
微信视频号全维度思维导图,涵盖基础信息、内容认知、运营技巧、基础操作、变现路径、运营数据六大核心板块。从账号搭建、内容创作,到实操运营、数据复盘、商业变现,一站式梳理视频号从 0 到 1 的运营逻辑,不管是新手入门还是老手进阶,都能快速 get 关键要点,助力玩转微信生态流量!
- 年终总结全攻略地图
对于职场人而言,十二月是一个格外特殊的月份。 说它特殊,是因为这是一年工作的收官节点,过往的耕耘与收获都将在此沉淀;说它特殊,更因为这是复盘总结的关键时期 —— 既要回望全年的成绩与不足,也要锚定下一年的方向与规划。 在此分享一些心得,希望能为各位职场伙伴带来些许启发。
- 云平台系统架构图
这是一套架构分层清晰、功能协同高效的软件系统解决方案,以模块化设计构建全链路技术支撑体系。前端展示层聚焦用户交互体验,提供直观易用的操作界面;API 接口层作为通信桥梁,实现前后端数据高效流转;业务应用系统承载核心业务逻辑,精准响应实际场景需求;服务中心统筹资源调度,保障各模块协同运转;数据存储层构建安全可靠的数据底座,支撑数据的存储、管理与检索;运行环境层提供稳定适配的部署基础,确保系统持续高效运行。整套架构兼顾实用性、扩展性与稳定性,为业务场景提供全方位技术赋能。
Java技能树
社区模板帮助中心,点此进入>>
- 程序猿知识技能总结 含16个作品
程序猿知识技能总结大全,java、python、正则表达式、Linux等多方面知识导图
- 运营基础知识总结、书籍汇总 含13个作品
包含抖音运营、短视频运营要点、运营之光、从零开始做运营、学会写作等多个运营读书笔记、运营知识框架等
- 产品、运营、程序猿常用工具汇总 含5个作品
产品、运营工具包大全:办公工具、文字工具、音频工具、视频工具、社群工具、公众号辅助工具、排版工具、图片工具、H5工具、小程序工具等
- 2026年最新版视频号知识地图
微信视频号全维度思维导图,涵盖基础信息、内容认知、运营技巧、基础操作、变现路径、运营数据六大核心板块。从账号搭建、内容创作,到实操运营、数据复盘、商业变现,一站式梳理视频号从 0 到 1 的运营逻辑,不管是新手入门还是老手进阶,都能快速 get 关键要点,助力玩转微信生态流量!
- 年终总结全攻略地图
对于职场人而言,十二月是一个格外特殊的月份。 说它特殊,是因为这是一年工作的收官节点,过往的耕耘与收获都将在此沉淀;说它特殊,更因为这是复盘总结的关键时期 —— 既要回望全年的成绩与不足,也要锚定下一年的方向与规划。 在此分享一些心得,希望能为各位职场伙伴带来些许启发。
- 云平台系统架构图
这是一套架构分层清晰、功能协同高效的软件系统解决方案,以模块化设计构建全链路技术支撑体系。前端展示层聚焦用户交互体验,提供直观易用的操作界面;API 接口层作为通信桥梁,实现前后端数据高效流转;业务应用系统承载核心业务逻辑,精准响应实际场景需求;服务中心统筹资源调度,保障各模块协同运转;数据存储层构建安全可靠的数据底座,支撑数据的存储、管理与检索;运行环境层提供稳定适配的部署基础,确保系统持续高效运行。整套架构兼顾实用性、扩展性与稳定性,为业务场景提供全方位技术赋能。
- 相似推荐
- 大纲










Java技能树
[技能树-CSDN](https://blog.csdn.net/qq_25885525/article/details/80261550)[github page](https://www.yizhuxiaozhan.site)[coding page](https://userzhao.coding.me/)
协议规范
HTTP1.1/2.0
[HTTP 接口设计指北](https://github.com/bolasblack/http-api-guide#user-content-http-%E5%8D%8F%E8%AE%AE) [HTTP/2.0 中文翻译](https://yuedu.baidu.com/ebook/478d1a62376baf1ffc4fad99?pn=1)
HTTPS
TCP/IP协议
[TCP/IP详解 卷1:协议](http://www.52im.net/topic-tcpipvol1.html)
UDP/IP
RPC
Remote Procedure Call
JPA
Java Persistence API
Mulicast
组播:基于TCP协议 - 单播 - 广播 - 组播
JWT
JMS
Java Message Service
JSR
设计模式
[史上最全的设计模式导学目录](https://blog.csdn.net/lovelion/article/details/17517213/ )
七大原则
单一职责原则
一个类只负责一个功能领域中的相应职责
开闭原则
扩展开放,修改关闭
里氏替换原则
任何基类可以出现的地方,子类一定可以出现
依赖倒转原则
针对接口编程,依赖于抽象而不依赖于具体
接口隔离原则
使用多个隔离的接口
迪米特法则
一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立
合成复用原则
尽量使用合成/聚合的方式,而不是使用继承
GoF 23种设计模式
创建型
工厂方法模式(Factory Method)
**工厂方法模式(Factory Method)** - 流水线生产
抽象工厂模式(Abstract Factory)
建造者模式(Builder)
原型模式(Prototype)
**原型模式(Prototype)** - 孙悟空吹毫毛
单例模式(Singleton)
**单例模式(Singleton)** 1. 配置文件 2. 日历类 3. IOC容器 4. Windows任务管理器 [单例模式](https://blog.csdn.net/qq_25885525/article/details/79948630)
结构型
代理模式(Proxy)
**代理模式(Proxy)** - 租房中介 - 售票黄牛 - 婚介 - 经纪人 - 快递 - 事务代理 - 非侵入式日志监听
适配器模式(Adapter)
**适配器模式(Adapter)** - 编码解码 - 一拖三充电头 - HDMI转VGA - Type-C转USB
桥接模式(Bridge)
组合模式(Composite)
装饰者模式(Decorator)
**装饰者模式(Decorator)** - IO流包装 - 数据源包装 - 简历包装
门面模式(Facade)
享元模式(Flyweight)
行为型
解释器模式(Interpreter)
模板方法模式(Template Method)
**模板方法模式(Template Method)** - JDBC Template
责任链模式(Chain of Responsibility)
命令模式(Command)
迭代器模式(Iterator)
调解者模式(Mediator)
备忘录模式(Memento)
观察者模式(Observer)
**观察者模式(Observer)** - 监听器 - 日至收集 - 短信通知 - 邮件通知
状态模式(State)
策略模式(Strategy)
**策略模式(Strategy)** - 旅游出行方式
访问者模式(Visitor)
J2EE 模式
MVC 模式(MVC)
业务代表模式(Business Delegate)
组合实体模式(Composite Entity)
数据访问对象模式(Data Access Object)
前端控制器模式(Front Controller)
拦截过滤器模式(Intercepting Filter)
服务定位器模式(Service Locator)
传输对象模式(Transfer Object)
其他常用设计模式
简单工厂模式(Simple Factory )
委派模式(Delegate)
过滤器模式/标准模式(Filter、Criteria)
空对象模式(Null Object)
表达式
正则表达式
[正则表达式30分钟入门教程](http://deerchao.net/tutorials/regex/regex.htm)
Cron表达式
EL表达式
Expression Language
JSTL表达式
OGLN表达式
Object-Graph Navigation Language
数据结构和算法
算法
排序算法
插入排序
直接插入排序
平均时间复杂度
O(n^2)
空间复杂度
O(1)
优点
稳定
希尔排序
平均时间复杂度
O(n^3/2)
折半插入
平均时间复杂度
O(n^2)
选择排序
简单选择排序
平均时间复杂度
O(n^2)
缺点
不稳定
堆排序
平均时间复杂度
O(n log n)
优点
任何情况下,复杂度相同
缺点
元素较少时,建堆消耗时间,性能较差
不稳定
树形选择排序
平均时间复杂度
O(n^2)
交换排序
冒泡排序
平均时间复杂度
O(n^2)
优点
稳定
快速排序
平均时间复杂度
O(n log n)
最坏时间复杂度
O(n^2)
缺点
不稳定
归并排序
分治法
划分
治理
组合
平均时间复杂度
O(n log n)
优点
稳定
桶排序
计数排序
基数排序
常用算法
二分法
贪婪
分治
回溯
动态规划
分支界限
剪枝
哈希
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值 [hash算法原理详解](https://blog.csdn.net/tanggao1314/article/details/51457585)
GEO hash
[JAVA实现空间索引编码(GeoHash)](https://blog.csdn.net/xiaojimanman/article/details/50358506)
常见的hash函数
直接定址法
直接以关键字k或者k加上某个常数(k+c)作为哈希地址。
数字分析法
提取关键字中取值比较均匀的数字作为哈希地址。
除留余数法
用关键字k除以某个不大于哈希表长度m的数p,将所得余数作为哈希表地址。
分段叠加法
按照哈希表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短。然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址。
平方取中法
如果关键字各个部分分布都不均匀的话,可以先求出它的平方值,然后按照需求取中间的几位作为哈希地址。
伪随机数法
采用一个伪随机数当作哈希函数。
布隆过滤器
数据结构
线性结构
数组
单向链表
双向链表
循环链表
队列
链队列
双端队列
循环队列
栈
树型结构
树
二叉树
B Tree
每个节点都可以存储数据
B+ Tree
只有叶子节点可以存储数据
相邻叶子节点有关联
红黑树
赫夫曼树
堆
图
有向图
无向图
哈希表
工具
IDE
IntelliJ IDEA
[IntelliJ IDEA 简体中文专题教程](https://github.com/judasn/IntelliJ-IDEA-Tutorial) [蓝玉IDEA注册码](http://idea.lanyus.com/) [idea破解方法](https://blog.csdn.net/QQljh123456/article/details/81514150) [IDEA使用总结](https://userzhao.coding.me/2019/06/01/tool-idea/)
插件
FindBugs
CheckStyle
JRebel
Translation
Maven Helper
Alibaba cloud toolkit
GenerateAllSetter
GenerateSerialVersionUID
GsonFormat
JProfiler
Lombok
Eclipse
STS
Visual Studio Code
代码管理
Git
[Pro Git(中文版)](https://gitee.com/progit/index.html)
特点
直接记录快照,而非差异比较
近乎所有操作都是本地执行
时刻保持数据完整性
多数操作仅添加数据
文件的三种状态
已提交(committed),已修改(modified)和已暂存(staged)
常用命令
git init
ssh-keygen -t rsa -C "XXX@qq.com"
git status
git remote
git clone
克隆代码
git clone git@XXX.com
git pull
git push
git checkout
切分支
git chekout -b dev-0719-xxx
撤销更改
git checkout .
git checkout 1.txt
git merge
git fetch
git log
git stash
git rebase
git tag
git alias
git branch
SVN
检出
更新
提交
分支(新文件)
合并(修改旧文件)
项目管理
Maven
官网:[Maven](https://maven.apache.org/)
版本号
X.Y.Z版本号含义: - X表示主版本号,API的兼容性变化时,X需递 - Y表示次版本号,当增加功能时(不影响API的兼容性),Y需递增 - Z表示修订号,当bug修复时(不影响API兼容性高),Z需递增 `Snapshot`: 版本代表不稳定、尚处于开发中的版本 `Release`:版本则代表稳定的发行版本
Gradle
官网:[Gradle](https://gradle.org/)
Ant
Buck
- github地址:[buck](https://github.com/facebook/buck) - Encourages the creation of small, reusable modules consisting of code and resources. - from facebook
Bazel
- 官网:[Buck](https://bazel.build/) - Tool from Google that builds code quickly and reliably.
OSGI
团队共享沟通工具
Confluence
Confluence是一个专业的企业知识管理与协同软件,一个专业的wiki. 通过它可以实现团队成员之间的协作和知识共享。 Confluence使用简单,但它强大的编辑和站点管理特征能够帮助团队成员之间共享信息,文档协作,集体讨论
JIRA
apidoc
Redmine
Phabricator
集成
Jenkins
[官网](https://jenkins.io)
Continuous integration
持续集成
Continuous Delivery
持续交付
Hudson
TeamCity
Strider
GitLab CI
Travis
Go
Docker
[官网](https://www.docker.com/) [DockerHub](https://hub.docker.com)
Kubernetes(k8s)
Sonar
JNDI
Harbor
日志查看
SecureCRT
XShell
Putty
调试工具
Postman
Fiddler
Jmeter
SoapUI
tsung
文档生成
Swagger
常用注解
@ApiOperation
Rap
代码生成
Lombok
官网:[Lombok](https://projectlombok.org/)
auto
github地址:[auto](https://github.com/google/auto)
immutables
- 官网:[Immutables](https://immutables.github.io/) - github地址:[immutables](https://github.com/immutables/immutables/)
javapoet
github地址:[javapoet](https://github.com/square/javapoet)
generator-jhipster
github地址:[generator-jhipster](https://github.com/jhipster/generator-jhipster)
代码混淆
代码混淆(Obfuscation)是将计算机程序的代码,转换成一种功能上等价,但是难于阅读和理解的形式的行为。
ProGuard
- 使用maven的proguard插件对项目中的代码进行混淆。 - 由于web项目情况复杂,不同的项目存在差异,因此不能保证混淆规则能够适用于所有项目,请务必确保混淆后的项目会经过严格测试。 - 请在pom.xml中添加如下内容, 确保plugin顺序为:compiler plugin → proguard plugin ```pom.xml <plugin> <groupId>com.github.wvengen</groupId> <artifactId>proguard-maven-plugin</artifactId> <version>2.0.14</version> <executions> <execution> <phase>package</phase> <goals><goal>proguard</goal></goals> </execution> </executions> <configuration> <proguardVersion>6.0.3</proguardVersion> <injar>${project.build.finalName}.jar</injar> <outjar>${project.build.finalName}.jar</outjar> <obfuscate>true</obfuscate> <options> <option>-dontshrink</option> <option>-dontoptimize</option> <option>-ignorewarnings</option> <!--不产生区分大小写的类名--> <option>-dontusemixedcaseclassnames</option> <!-- 确定唯一的混淆类的成员名称来混淆--> <option>-useuniqueclassmembernames</option> <!-- 替换反射调用时候的类名字符串, 比如Class.forName('className')--> <option>-adaptclassstrings</option> <!-- 保留注解、自定义异常、内部类、泛型等--> <option>-keepattributes Exceptions,InnerClasses,Signature,Deprecated, SourceFile,LineNumberTable,*Annotation*,EnclosingMethod</option> <!-- 保留接口定义--> <option>-keepnames interface **</option> <!-- 保持目录--> <option>-keepdirectories</option> <!-- This option will save all original interfaces files (without obfuscate) in all packages.--> <option>-keep interface * extends * { *; }</option> <!--保留get set和is方法--> <option>-keepclassmembers public class * {void set*(***);*** get*();*** is*();}</option> <!-- 不混淆实体类以及类的属性及方法,实体包, 混淆了会导致ORM框架和序列化问题 需要根据实际情况修改 --> <option>-keep class xxx.xxx.entity.** {*;}</option> <!--不混淆service层的类名,混淆方法和成员变量 请根据实际情况修改 --> <option>-keep class xxx.xxx.xx.** </option> <!-- 保留入口Application和main函数--> <option>-keepclasseswithmembers public class com.pahf.arc.TestApplication{ public static void main(java.lang.String[]); } </option> </options> <libs> <!-- Include main JAVA library required.--> <lib>${java.home}/lib/rt.jar</lib> <lib>${java.home}/lib/jce.jar</lib> </libs> </configuration> <dependencies> <dependency> <groupId>net.sf.proguard</groupId> <artifactId>proguard-base</artifactId> <version>6.0.3</version> </dependency> </dependencies> </plugin> ```
浏览器
google浏览器
插件
Session Buddy
SwitchyOmega
Octotree
firefox浏览器
360浏览器
QQ浏览器
IE浏览器
日志收集
Logstash
Filebeat
Kibana
Flume
数据库
事务
事务隔离级别
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。 大多数的数据库默认隔离级别为 `Read Commited`,比如 SqlServer、Oracle 少数数据库默认隔离级别为:`Repeatable Read` 比如: MySQL InnoDB
Read-Uncommitted
可能导致脏读
Read-Committed
避免脏读,允许不可重复读和幻读
Repeatable-Read
避免脏读,不可重复读,允许幻读
Serializable
串行化读,事务只能一个一个执行,避免了脏读、不可重复读、幻读。执行效率慢,使用时慎重
数据库事务要满足的几点要求:ACID
Atomic(原子性)
事务必须是原子的工作单元
Consistent(一致性)
事务完成时,必须是所有数据保持一致状态
Isolation(隔离性)
并发事务所做的修改必须和其他事物所作的修改是隔离的
Duration(持久性)
事务完成之后,对系统的影响是永久性的
分布式事务
事务模型
X/Open DTP
协议
2PC
3PC
实现
JOTM
Atomikos
关系型数据库
[如果有人问你数据库的原理,叫他看这篇文章](http://blog.jobbole.com/100349/)
MySQL
[21分钟 MySQL 入门教程](http://www.cnblogs.com/mr-wid/archive/2013/05/09/3068229.html) [MySQL索引背后的数据结构及算法原理](http://blog.codinglabs.org/articles/theory-of-mysql-index.html) 相关书籍: 《MySQL性能调优与架构设计》
引擎
InnoDB(支持事务)
以主键为索引来组织数据聚集索引- 建议用自增id作主键- 分布式id生成算法snowflake可避免暴露自增id
MyISAM(支持全文索引)
非聚集索引
BerkeleyDB
分库分表
为什么要分库分表
单表超大容量
性能问题
如何分
垂直切分
垂直分库
解决表过多问题
垂直分表
解决单表列过多问题
水平切分
大数据表拆成小表
一致性hash
范围切分(可按照ID)
日期拆分
按月拆分
按天拆分
拆分以后可能带来的问题
跨库join
跨分片数据排序分页
唯一主键问题
分布式事务问题
主从
主从同步原理
1.master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务
2. slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志
3. SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致
主从同步延时问题
产生原因
1. 当master库tps比较高的时候,产生的DDL数量超过slave一个sql线程所能承受的范围,或者slave的大型query语句产生锁等待
2. 网络传输: bin文件的传输延迟
3. 磁盘的读写耗时:文件通知更新、磁盘读取延迟、磁盘写入延迟
解决方案
1. 在数据库和应用层增加缓存处理,优先从缓存中读取数据
2. 减少slave同步延迟,可以修改slave库sync_binlog属性; sync_binlog=0 文件系统来调度把binlog_cache刷新到磁盘sync_binlog=n
3. 增加延时监控Nagios做网络监控mk-heartbeat
SQL优化
[MySQL索引原理及慢查询优化](https://tech.meituan.com/mysql-index.html)[我必须得告诉大家的MySQL优化原理](http://www.iteye.com/news/32381)
索引
定义:帮助高效获取数据的一种数据结构
种类
B-Tree索引
Hash索引
Fulltext索引
R-Tree索引
pros
提高检索效率
降低排序成本
排序分组主要消耗的是我们内存和CPU的资源
cons
更新索引IO量
调整索引所致的计算量
存储空间
是否建索引
较频繁的作为查询条件的字段应建索引
唯一性太差的字段不适合单独创建索引
更新非常频繁的字段不适合创建索引
不会出现在where子句中的字段不该创建索引
原则
永远用小结果集驱动大结果集
join
只取出自己需要的列
数据量
排序占用空间
max_length_for_sort_data
仅仅使用最有效的过滤条件
key length
尽可能避免复杂的join和子查询
锁资源
explain
[explain官方文档](https://dev.mysql.com/doc/refman/5.7/en/explain-output.html)[mysql explain的解释](https://blog.csdn.net/qwentest/article/details/11143547)
join
优化
永远用小结果集驱动大结果集
保证被驱动表的join条件字段已经被索引
join buffer
join_buffer_size
order by
实现
有序
无序
排序字段和指针在Sort Buffer排序--->然后用指针去取数据
排序字段和所有字段全部取出--->排序字段+指针Sort Buffer排序(其他数据存到内存中)--->指针到内存里去取数据然后返回
节省IO
耗内存
空间换时间
优化
索引顺序一致的话不需要在排序
加大max_length_for_sort_data从而使用第二种排序方法(排序只针对需要排序的字段)
内存不足时,去掉不必要返回的字段
增大sort_buffer_size
减少在排序过程中对需要排序的字段进行分段
group by
基于排序,所以要优化好对应的排序
distinct
基于分组,所以要优化好对应的分组
limit
例子
select id,name from table where name='小明' limit 100,10
这条sql会查出110条,然后取出后10条,所以要优化查询速度
锁
行锁
pros
粒度小
cons
获取、释放所做的工作更多
容易发生死锁(多个表时)
锁优化
尽可能让所有的数据检索都通过索引来完成
合理设计索引
减少基于范围的数据是检索过滤条件
尽量控制事务的大小
业务允许的情况下,尽量使用较低级别的事务隔离
Innodb引擎
表级锁的争用状态变量
show status like 'table%';
页锁
介于行锁和表锁之间
BerkeleyDB引擎
表锁
pros
实现逻辑简单
获取、释放快
避免死锁(不会出现死锁的问题)
cons
粒度太大,并发不够高
MyISAM引擎
行级锁争用状态变量
show status like 'innodb_row_lock%';
共享锁
排他锁
间隙锁
通过在指向数据记录的第一个索引键之前和最后一个索引键之后的空域空间上标记锁定信息来实现的
乐观锁
悲观锁
事务
Oracle
SQL Server
PostgreSQL
[21分钟 MySQL 入门教程](http://www.cnblogs.com/mr-wid/archive/2013/05/09/3068229.html) [MySQL索引背后的数据结构及算法原理](http://blog.codinglabs.org/articles/theory-of-mysql-index.html) 相关书籍: 《MySQL性能调优与架构设计》
PgSql
数据库设计
范式
E-R图
NoSql
Redis
[Redis命令](https://redis.io/commands) [redis命令参考](http://redisdoc.com/) [redis设计与实现](http://redisbook.com/) [The Little Redis Book](https://github.com/JasonLai256/the-little-redis-book/blob/master/cn/redis.md) [带有详细注释的 Redis 2.6 代码](https://github.com/huangz1990/annotated_redis_source) [带有详细注释的 Redis 3.0 代码](https://github.com/huangz1990/redis-3.0-annotated) **应用场景:** 1.数据缓存 2.单点登录 3.秒杀、抢购 3.网站访问排名 5.微博粉丝。。。
数据结构
字符类型
散列类型
列表类型
集合类型
有序集合
事务
WATCH
监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断
UNWATCH
取消 WATCH 命令对所有 key 的监视。
EXEC
执行所有事务块内的命令
MULTI
标记一个事务块的开始。事务块内的多条命令会按照先后顺序被放进一个队列当中,最后由 EXEC 命令原子性(atomic)地执行。
DISCARD
取消事务,放弃执行事务块内的所有命令。如果正在使用 WATCH 命令监视某个(或某些) key,那么取消所有监视,等同于执行命令 UNWATCH 。
lua脚本
优点
减少网络开销
原子操作
复用性
轻量级
Pika
pika主要是使用持久化存储来解决redis在内存占用超过50G,80G时遇到的如启动恢复时间长,主从同步代价大,硬件成本贵等问题 [Pika介绍](https://www.jianshu.com/p/878812193de4)
与redis对比的优缺点
优点
容量大
加载数据快
恢复数据快
节省机器内存资源
采用binLog,实现全同步 + 增量同步,不存在缓存区写满问题
多数据key快速删除
快照式备份
缺点
单线程下性能不如redis
Memcache
BerkeleyDB
Voldemort
MongoDB
[The Little MongoDB Book](https://github.com/justinyhuang/the-little-mongodb-book-cn/blob/master/mongodb.md)
BSON
CouchDB
Membase
Couchbase
[官网](https://www.couchbase.com)
NewSql
Spanner
VoltDB
Clustrix
NuoDB
中间件
[Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能](http://jm.taobao.org/2016/04/01/kafka-vs-rabbitmq-vs-rocketmq-message-send-performance/?utm_source=tuicool&utm_medium=referral) 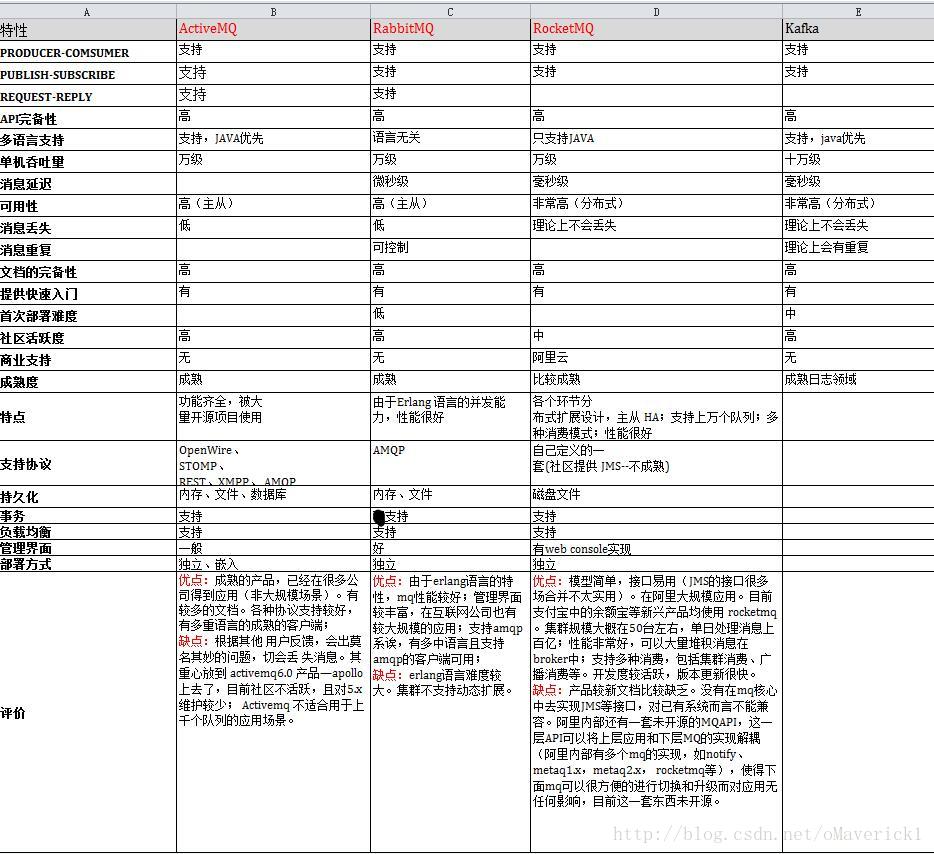
Kafka/Jafka
优点
时间复杂度O(1)
TPS高
缺点
不支持定时消息
Kafka Streams
ActiveMQ
RabbitMQ
优点
高并发(erlang语言实现特性导致)
高可靠、高可用
缺点
重量级
RocketMQ
[十分钟入门RocketMQ](http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/)
java语言实现
组件
nameserver
broker
producer
consumer
两种消费模式
PULL
DefaultMQPullConsumer
PUSH
DefaultMQPushConsumer
优点
数据可靠性高
支持同步刷盘、异步实时刷盘、同步复制、异步复制
消息投递实时性
支持消息失败重试
高TPS
单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节
严格的消息顺序
支持定时消息
支持按照时间回溯消息
亿级消息堆积
缺点
消费过程要做到幂等(去重)
ZeroMQ
优点
TPS高
缺点
不支持持久化消息
可靠性、可用性较差
JMS
API
ConnectionFactory
Connection
Session
Destination
MessageProducer/consumer
消息组成
消息头
消息体
TextMessage
MapMessage
BytesMessage
StreamMessage
ObjectMessage
消息属性
JMS可靠机制
消息被确认才认为是被成功消费。消息的 消费包含三个阶段:客户端接收消息,客户端处理消息,消息被确认
事务性会话
消息在session.commit后自动提交
非事务性会话
应答模式
AUTO_ACKNOWLEDGE
自动确认
CLIENT_ACKNOWLEDGE
textMessage.acknowledge()确认消息
DUPS_OK_ACKNOWLEDGE
延迟确认
点对点(P2P模式)
发布订阅(Pub/Sub模式)
持久订阅
非持久订阅
Disque
[Disque 使用教程](http://disque.huangz.me/)
Cassandra
Neo4j
InfoGrid
大数据
Hadoop
MapReduce
HDFS
HBase
Spark
Hive
大数据搜索
[搜索引擎选择: Elasticsearch与Solr](http://www.cnblogs.com/chowmin/articles/4629220.html)
Lucene
ElasticSearch
特点
基于Lucene基本架构
java搜索界的鼻祖
实时搜索性能高
正则、substring、内存数据库
构件
Document行(Row)文本
Index索引(数据关键值)
Analyzer分词器(打标签)
Solr
特点
不能用于实时搜索
Nutch
嵌入式数据库
H2
HSQL
Derby
SQLite
UnQLite
Berkeley DB
eXtremeDB
Progress
Empress
Firebird
mSQL
OpenBASE Lite
服务器
负载均衡服务器
Nginx
[Nginx开发从入门到精通(淘宝团队出品)](http://tengine.taobao.org/book/index.html#id1) [Nginx教程从入门到精通(PDF版本,运维生存时间出品)](http://www.ttlsa.com/nginx/nginx-stu-pdf/)
f5
4层负载
redware
7层负载
Tomcat
架构
目录结构
conf
catalina.policy
Tomcat安全策略文件,控制JVM相关权限,具体参考java.security.Permission
catalinna.properties
Tomcat Catalina行为控制配置文件,比如Common ClassLoader
logging.properties
Tomcat日志配置文件,JDK Logging
server.xml
GlobalNamingResource
Jetty
WebSphere
Apache
[Apache 中文手册](http://www.jinbuguo.com/apache/menu22/index.html)
Jboss
WebLogic
DNS
CDN
Resin
TOMEE
Undertow
lighttpd
glassfish
操作系统
Windows
Linux
命令
[命令](http://man7.org/linux/man-pages/man1/top.1.html)
cd
ls
ll
mkdir
rmdir
mv
rm
cp
pwd
打印当前目录(print working directory)
df
man
info
help
info --help
tail
tail -f SystemOut.log
实时显示最新日志
tail -200 SystemErr.log
查看最新的200行日志
head
head -200 SystemOut.log
查看最开始的200行日志
sz
sz a.war
下载war包
vi
vi a.txt
打开或新建文件,并将光标置于第一行首
vi +/pattern a.txt
打开a文件,并将光标置于第一个与pattern匹配的串处
top
iostat
iostat -dx l
vmstat
free
free /m
free /g
nicstat
Mac
前端及脚本语言
AngularJS
[官网]()[中文网](http://www.angularjs.net.cn/)
JQuery
[官网](https://jquery.com/) [jQuery遮罩插件jQuery.blockUI.js简介 ](http://bookshadow.com/weblog/2014/09/26/jquery-blockui-js-introduction/)
Node.js
Vue.js
React
JSP
热加载机制
**jsp热加载** 自定义类加载器,可以加载类之后,加密保存,防止被窃取。。。 为什么热加载技术没有广泛应用:类变了,里面的变量保存的信息变了,不可用了,差生大量垃圾,高并发场景不适用
CSS
HTML
JqGrid
Markdown
一、[MarkdownPad 2 安装和破解](https://blog.csdn.net/github_35160620/article/details/52158604) **二、实现首行缩进的两种方法** 1.把输入法由半角改为全角。 两次空格之后就能够有两个汉字的缩进。 2.在开头的时候,先输入下面的代码,然后紧跟着输入文本即可。分号也不要掉。 直接写 `半方大的空白 或 ` `全方大的空白 或 ` `不断行的空白格 或 `
ECharts
Velocity
Lua
[官网](https://www.lua.org/)
Shell
Webpack
框架
Spring Framework
Core
IOC
[Spring:源码解读Spring IOC原理](https://www.cnblogs.com/ITtangtang/p/3978349.html#a1)
常用注解
类级别注解
@Component
since 2.5
@Controller
since 2.5
@Service
since 2.5
@Repository
since 2.0
@Configuration
since 3.0
@ComponentsScan
since 3.1
@Bean
since 3.0
@Scope
@since 2.5
方法变量级别注解
@Autowire
@Qualifier
@Resource
@Value
@Cacheable
@since 3.1 - 当标记在一个方法上时表示该方法是支持缓存的 - 当标记在一个类上时则表示该类所有的方法都是支持缓存的 ``` @Cacheable(value="accountCache")// 使用了一个缓存名叫 accountCache public Account getUserAge(int id) { //这里不用写缓存的逻辑,直接按正常业务逻辑走即可, //缓存通过切面自动切入 int age=getUser(id); return age; } ```
@CacheEvict
@since 3.1 - 用来标记要清空缓存的方法,当这个方法被调用后,即会清空缓存。 - 参数列表 | 参数 | 解释 | 例子 | | ------ | ------ | ------ | | value | 名称 | @CachEvict(value={”c1”,”c2”} | | key | key | @CachEvict(value=”c1”,key=”#id”) | | condition | 缓存的条件,可以为空 | | allEntries | 是否清空所有缓存内容 | @CachEvict(value=”c1”,allEntries=true) | | beforeInvocation | 是否在方法执行前就清空 | @CachEvict(value=”c1”,beforeInvocation=true) |
三种注入方式
构造器注入
好处
官方解释; The Spring team generally advocates constructor injection as it enables one to implement application components as immutable objects and to ensure that required dependencies are not null. Furthermore constructor-injected components are always returned to client (calling) code in a fully initialized state.
保证依赖不可变(final关键字)
保证依赖不为空(省去了我们对其检查)
保证返回客户端(调用)的代码的时候是完全初始化的状态
避免了循环依赖
提升了代码的可复用性
field注入
setter注入
AOP
定义: - 将那些与业务无关,却被业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。(通过预 编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能的一种技术) 实现: - 实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。 优秀博客 [Spring AOP 实现原理](https://blog.csdn.net/moreevan/article/details/11977115/)
实现原理
动态代理
JDK实现
需要实现至少一个接口
CGlib
ASM操作字节码实现生成目标类的子类
静态代理
编译时织入
类加载时织入
关键字
Join Point(连接点)
Poincut(切入点)
Advice(通知)
Before advice
执行在join point之前的advice,但是它不能阻止joint point的执行流程,除非抛出了一个异常(exception)。
After returning advice
执行在join point这个方法返回之后的advice。
After throwing advice
执行在join point抛出异常之后的advice。
After(finally) advice
执行在join point返回之后或者抛出异常之后的advice,通常用来释放所使用的资源。
Around advice
执行在join point这个方法执行之前与之后的advice。
Introduction
Target Object
AOP proxy
Aspect(切面)
Weaving
实现方式
注解
@AspectJ
@Pointcut
@Before
@After
@Around
配置文件
常见应用
事务
日志
权限
events
resources
i18n
validation
data binding
type conversion
SpEL
Testing
mock objects
TestContext framework
Spring MVC Test
WebTestClient
Data Access
transactions
DAO support
JDBC
ORM
Marshalling XML
Spring MVC
Spring Web MVC
常用注解
类级别注解
@EnableWebMvc
since 3.1
@SessionAttributes
- 默认情况下Spring MVC将模型中的数据存储到request域中。当一个请求结束后,数据就失效了。如果要跨页面使用。那么需要使用到session。而@SessionAttributes注解就可以使得模型中的数据存储一份到session域中 - 参数: 1. names:这是一个字符串数组。里面应写需要存储到session中数据的名称。 2. types:根据指定参数的类型,将模型中对应类型的参数存储到session中 3. value:和names是一样的。 ``` @Controller @SessionAttributes(value={"names"},types={Integer.class}) public class ScopeService { @RequestMapping("/testSession") public String test(Map<String,Object> map){ map.put("names", Arrays.asList("a","b","c")); map.put("age", 12); return "hello"; } } ```
方法变量级别注解
@RequestBody
@ResponseBody
@RequestMapping
@GetMapping
spring 4.3新增
@PostMapping
spring 4.3新增
@PutMapping
spring 4.3新增
@DeleteMapping
spring 4.3新增
@PatchMapping
spring 4.3新增
@ModelAttribute
@RequestParam
@requestHeader
@CookieValue
@PathVariable
@CrossOrigin
@Valid
校验参数
@Validated
校验参数
@ExceptionHandler
全局异常处理@ExceptionHandler(Throwable.class)
@ControllerAdvice
切面通知@ControllerAdvice(assignableTypes = xxx.class)
核心组件
DispatcherServlet
HandlerMapping
HandlerAdapter
ViewResolver
···
Spring Web Flux
Reactor基础
Lambda
Mono
Flux
核心
Web MVC注解
函数式声明
RouteFunction
异步非阻塞
使用场景
Integration
remoting
JMS
JCA
JMX
tasks
scheduling
cache
Languages
Kotlin
Groovy
dynamic languages
MVC框架
Struts
JSF
JavaServer Faces
WebWork
ORM框架
SpringData
Spring Data JDBC
Spring Data JPA
sql生成
通过方法名拼接sql
- 匹配正则:^(find|read|get|query|stream|count|exists|delete|remove)((\p{Lu}.*?))??By
查询
正则匹配:(find|read|get|query|stream)(Distinct)?(First|Top)(\d*)?(\p{Lu}.*?)??By
find
```javaList<User> findByName(String name);```
read
get
query
stream
First
```java List<User> findFirst10ByName(String name); ```
Top
```java List<User> findTop10ByName(String name); ```
count
exists
Distinct
```java List<User> findDistinctByName(String name) ```
OrderBy
删除
remove
delete
其他
IsBetween/Between
```java List<User> findByAgeBetween(Integer fromAge, Integer endAge); ```
IsNotNull/NotNull
IsNull/Null
IsLessThan/LessThan
IsLessThanEqual/LessThanEqual
IsGreaterThan/GreaterThan
IsGreaterThanEqual/GreaterThanEqual
IsBefore/Before
IsAfter/After
IsNotLike/NotLike
IsLike/Like
IsStartingWith/StartingWith/StartsWith
IsEndingWith/EndingWith/EndsWith
IsNotEmpty/NotEmpty
IsEmpty/Empty
IsNotContaining/NotContaining/NotContains
IsContaining/Containing/Contains
IsNotIn/NotIn
IsIn/In
IsNear/Near
IsWithin/Within
MatchesRegex/Matches/Regex
IsTrue/True
IsFalse/False
IsNot/Not
Is/Equals
@Query
JPQL
```java @Query(value = "select u from User u where u.name= :name") List<User> findUsersByName(@Param("name") String name); @Query(value = "select u from User u where u.name= ?1") List<User> findUsersByName(String name); ```
原生SQL
```java @Query(value = "select * from t_user where name = :name", nativeQuery = true) List<User> findAllByName(@Param("name") String name); @Query(value = "select * from t_user where name = ?1", nativeQuery = true) List<User> findAllByName(@Param("name") String name); ```
编程式
```java public class UserSpecs { public static Specification<User> listQuerySpec(UserQueryDto userQueryDto){ return (root, query, builder) -> { List<Predicate> predicates = new ArrayList<>(); Optional.ofNullable(userQueryDto.getId()).ifPresent(i -> predicates.add(builder.equal(root.get("id"), i))); Optional.ofNullable(userQueryDto.getUserName()).ifPresent(n -> predicates.add(builder.equal(root.get("userName"), n))); Optional.ofNullable(userQueryDto.getUserAge()).ifPresent(a -> predicates.add(builder.equal(root.get("userAge"), a))); Optional.ofNullable(userQueryDto.getOrgId()).ifPresent(oi -> predicates.add(builder.equal(root.get("orgId"), oi))); Optional.ofNullable(userQueryDto.getOrgName()).ifPresent(on -> { Join<User, Organization> userJoin = root.join(root.getModel().getSingularAttribute("org", Organization.class), JoinType.LEFT); predicates.add(builder.equal(userJoin.get("orgName"), on)); }); return builder.and(predicates.toArray(new Predicate[predicates.size()])); }; } } ``` ```java @Service public class UserService { @Autowired private UserRepository userRepository; public List<User> findUsersDynamic(UserQueryDto userQueryDto){ return userRepository.findAll(UserSpecs.listQuerySpec(userQueryDto)); } } ```
JPA自带常用API
JpaRepository<T, ID>
findAll
```java List<T> findAll(); List<T> findAll(Sort var1); <S extends T> List<S> findAll(Example<S> var1); <S extends T> List<S> findAll(Example<S> var1, Sort var2); ```
findAllById
```java List<T> findAllById(Iterable<ID> var1); ```
saveAll
```java <S extends T> S saveAndFlush(S var1); ```
saveAndFlush
```java void deleteAllInBatch(); ```
deleteInBatch
```java void deleteInBatch(Iterable<T> var1); ```
deleteAllInBatch
```java void deleteAllInBatch(); ```
getOne
```java T getOne(ID var1); ```
PagingAndSortingRepository<T, ID>
findAll
```java Iterable<T> findAll(Sort var1); Page<T> findAll(Pageable var1); ```
CrudRepository<T, ID>
save
```java <S extends T> S save(S var1); ```
saveAll
```java <S extends T> Iterable<S> saveAll(Iterable<S> var1); ```
findAll
```java Iterable<T> findAll(); ```
findById
```java Optional<T> findById(ID var1); ```
existsById
```java boolean existsById(ID var1); ```
count
```java long count(); ```
deleteById
```java void deleteById(ID var1); ```
delete
```java void delete(T var1); ```
deleteAll
```java void deleteAll(Iterable<? extends T> var1); void deleteAll(); ```
其他
flush
```java void flush(); ```
Spring Data Mongodb
Spring Data Redis
Spring Data Elasticsearch
Spring Data Apache Solr
Spring Data Apache Hadoop
Hibernate
MyBatis
[官网帮助文档](http://www.mybatis.org/mybatis-3/zh/index.html) **什么是Mybatis** MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
两种sql配置方式
XML配置方式
优点: - 跟接口分离、统一管理 - 复杂语句可以不影响接口的可读性 缺点: - 过多的xml文件
Annotation注解方式
优点: - 接口就能看到sql语句,可读性高,不需要再去找xml文件,方便 缺点: - 复杂的联合查询语句不好维护,代码可读性差
configuration 配置各个元素
properties
setting
typeAliases
typeHandlers
objectFactory
plugins
environments
databaseProvider
mapper
分页
pageHelper
批量操作
联合查询
可能遇到的坑
jdbcType与数据库字段类型的匹配
Morphia
MongoDB的一个ORM框架
数据库连接池
C3P0
DBCP
druid
HikariCP
proxool
Tomcat jdbc pool
tomcat7.0引入
BoneCP
缓存框架
Ehcache
[Ehcache官网](http://www.ehcache.org/)
缓存策略
TTL
LRU
caffeine
github地址:[caffeine](https://github.com/ben-manes/caffeine)
Infinispan
官网:[Infinispan](http://infinispan.org/)
日志处理
Log4j
sl4j
安全框架
Spring Security
Shiro
计算框架
Storm
[Storm:最火的流式处理框架](https://www.cnblogs.com/langtianya/p/5199529.html) [Storm 入门的Demo教程](https://www.cnblogs.com/xuwujing/p/8584684.html)
Nimbus
Supervisor
Worker
Executor
Task
Topology
Spout
Bolt
Tuple
Stream分组
Shuffle
Fields
All
Global
None
Direct
Local or shuffle
JStorm
[JStorm中文开发文档](https://github.com/alibaba/jstorm/wiki/JStorm-Chinese-Documentation)
Spark Streaming
[Spark 编程指南简体中文版](https://legacy.gitbook.com/book/aiyanbo/spark-programming-guide-zh-cn/details)
Flink
Blink
job框架
Quartz
[Quartz官网](http://www.quartz-scheduler.org/)
常用注解
@DisallowConcurrentExecution
禁止并发执行同一个 Job Definition(由 JobDetail 定义),但是可以同时执行多个不同的 JobDetail
组件
JobDetail
Trigger
SimpleTrigger
CronTrigger
Calendar
Schedule
ElasticJob
微服务&分布式框架
RPC框架
跨语言RPC框架
Hessian
Apache Thrift
gRPC
Hprose
服务治理RPC框架
Dubbo
组成
Provider
Consumer
Registry
Monitor
支持的容器
Spring
Jetty
Log4j
Logback
支持的协议
默认dubbo同一个服务可配置多种协议,需配置协议对应端口
dubbo(默认)
RMI
hessian
webservice
http
thrift
支持的注册中心
支持多注册中心- 中英文网站,配置中心分离
zookeeper
redis
multicast
simple
服务治理
负载均衡
随机负载(默认)
可设置权重
一致性哈希
最小活跃度
....
配置
注册中心支持本地缓存(缓存在文件系统)
file="c:/dubbo-server"
DubboX
JSF
Motan
SpringBoot
[SpringBoot源码分析之---SpringBoot项目启动类SpringApplication浅析](https://www.yizhuxiaozhan.site/2018/09/06/SpringApplication-analyze/)
常用注解
类级别注解
@SpringBootApplication
@RestController
@EnableAutoConfiguration
@EntityScan
方法变量级别注解
三大特性
组件自动装配
web MVC
支持的模板引擎
FreeMarker
Groovy
Thymeleaf
Mustache
JSP
不推荐 [官网给出一些已知的限制](https://docs.spring.io/spring-boot/docs/2.1.1.RELEASE/reference/htmlsingle/#boot-features-jsp-limitations)
web Flux
支持的模板引擎
FreeMarker
Thymeleaf
Mustache
JDBC
···
嵌入式Web容器
Tomcat
Jetty
Undertow
生产准备特性
指标
健康检查
外部化配置
···
自动装配
实现方法
激活自动装配-@EnableAutoConfiguration
实现自动装配-XXXAutoConfiguration
配置自动装配实现-META-INFO/spring.factories
扩展点
SpringApplication
自动配置(Auto-Configuration)
诊断分析(Diagnostics Analyzer)
嵌入式容器(Embedded Container)
工厂加载机制(Factories Loadding Mechanism)
配置源(Property Sources)
端点(Endpoints)
监控和管理(JMX)
事件/监听器(Event/Listener)
SpringCloud
[史上最简单的 SpringCloud 教程 | 终章](https://blog.csdn.net/forezp/article/details/70148833/)
主要组件
消息总线
服务发现
路由网关
服务链路追踪
负载均衡
Ribbon
负载规则
随机规则
RandomRule
最可用规则
BestAvailableRule
轮训规则
RoundRobinRule
重试实现
RetryRule
客户端配置
ClientConfigEnabledRoundRobinRule
可用性过滤规则
AvailabilityFilteringRule
RT权重规则
WeightedResponseTimeRule
规避区域规则
ZoneAvoidanceRule
断路器
服务监控
Nacos
阿里开源分布式配置中心
Apollo
携程开源分布式配置中心 [Apollo github地址](https://github.com/ctripcorp/apollo)
Disconf
百度开源分布式配置中心
Zookeeper
[Zookeeper官网]()
数据模型
节点类型
持久化节点
持久化有序节点
临时节点
临时有序节点
命令
创建和删除节点有顺序,创建时需要先创建父节点,删除时反过来,需先删除子节点
创建节点
create [-s] [-e] path data acl
获取节点
get path [watch]
zookeeper提供了分布式数据发布/订阅,zookeeper允许客户端向服务器注册一个watcher监听。当服务器端的节点出发事件的时候会触发watcher。服务端会向客户端发送一个事件通知 `watcher的通知是一次性的,一旦触发一次后,watcher就失效`
列出节点
ls [path]
修改节点
set path data [version]
version实现乐观锁
删除节点
delete path [version]
适用场景
订阅发布/配置中心
watcher机制实现
实现配置信息的集中式管理和数据的动态更新
服务发现
分布式锁
临时有序节点及watcher机制实现
排他锁
临时节点实现
共享锁
临时有序节点实现
负载均衡
请求/数据分摊多个计算机单元上
ID生成器
分布式队列
统一命名服务
master选举
可以避免脑裂问题
限流
etcd
Apache Mesos
Helidon
Service Mesh
Service Mesh(服务网格)是一个基础设施层,让服务之间的通信更安全、快速和可靠。
Linkerd
[官网](https://linkerd.io/)
Istio
[官网](https://istio.io)
Envoy
被部署为`sidecar`
动态服务发现
负载均衡
轮询
随机
带权重的最少请求
TLS 终止
HTTP/2 & gRPC 代理
熔断器
健康检查、基于百分比流量拆分的灰度发布
故障注入
丰富的度量指标
Mixer
访问控制
使用策略
收集数据
Pilot
服务发现
弹性(超时、重试、熔断器等)流量管理
智能路由
Citadel
Galley
Envoy
nginmesh
工具类库
Apache Commons
Google Guava
lombok
字节码操作类库
ASM
Cglib
Javassist
官网:[Javassist](http://www.javassist.org/)
Byteman
官网:[Byteman](http://byteman.jboss.org/)
Byte Buddy
官网:[Byte Buddy](http://bytebuddy.net/#/)
bytecode-viewer
github地址:[bytecode-viewer](https://github.com/Konloch/bytecode-viewer)
json
FastJson
Gson
Jackson
Json-lib
reactive框架
Vert.x
[官网](https://vertx.io/)
异步框架
Netty
其他
Tiles
架构
分布式
分布式事务
2PC
3PC
JOTM
JOTM(java open transaction manager)
Atomikos
分布式锁
mysql行锁实现
redis setnx实现
zk、etcd实现
SOA
Service-Oriented Architecture
RESTful
[Representatiomal state transfer](https://en.wikipedia.org/wiki/Representatiomal_state_transfer)
WebService
安全
单项散列算法
MD5
SHA
对称加密
DES
非对称加密
RSA
HTTPS
网络安全
XSS
CSRF
注入攻击
文件上传漏洞
DDOS攻击
测试
黑盒测试
白盒测试
Junit
Spring Test
Jmeter
Sonar
语言
Java
JDK
[JDK 10 Documentation](https://docs.oracle.com/javase/10/)
JRE
JVM
内存模型
方法区
jdk1.8前
永久代(PermGen)
堆内存
为什么分代: - 对象的生命周期不一样
老年代
新生代
eden:8
s0:1
s1:1
本地内存
jdk1.8
元空间(Meta Space)
运行时数据区
数据、指令、控制
数据
方法区
- 类信息、常量(1.7有变化)、静态变量、JIT(1.7以前) - 线程共享的 - 死循环、集合元素过多、内存加载数据过于庞大等会导致报错`java.lang.OutOfMemoryError: PermGen space` - 在JDK6、JDK7、JDK8运行结果均不一样。原因就在于字符串常量池在JDK6的时候还是存放在方法区(永久代)所以它会抛出`java.lang.OutOfMemoryError:Permanent Space`;而JDK7后则将字符串常量池移到了Java堆中,代码不会抛出OOM,若将堆内存改为20M则会抛出`java.lang.OutOfMemoryError:Java heap space`;至于JDK8则是纯粹取消了方法区这个概念,取而代之的是”`元空间`(`Metaspace`)“,所以在JDK8中虚拟机参数”`-XX:MaxPermSize`”也就没有了任何意义,取代它的是”`-XX:MetaspaceSize`“和”`-XX:MaxMetaspaceSize`”等。 - 可能导致OOM:PermGen space的场景:大量使用Cglib、大量JSP或动态产生JSP、基于OSGi的应用. .
运行时常量池
堆
- 实例和数组对象 - 线程共享的 - new太多对象,会导致`java.lang.OutOfMemoryError:java heap space`错误 - 导致OOM的两个原因:内存泄漏和内存溢出
指令
程序计数器
- 指向当前线程正在执行的字节码指令的地址 行号 - 是线程独享的 - 这是JVM规范中唯一一个没有规定会导致OutOfMemory(内存泄露)的区域
虚拟机栈
- 执行Java方法 - 存储当前线程运行方法时所需要的`数据`、`指令`、`返回地址` - 线程私有的 - `虚拟机栈`是线程私有的,每创建一个线程,`虚拟机`就会为这个线程创建一个`虚拟机栈`,`虚拟机栈`表示Java方法执行的内存模型,每调用一个方法就会为每个方法生成一个`栈帧`(Stack Frame),用来存储`局部变量表`、`操作数栈`、`动态链接`、`方法出口`等信息。每个方法被调用和完成的过程,都对应一个`栈帧`从`虚拟机栈`上入栈和出栈的过程。`虚拟机栈`的生命周期和`线程`是相同的 - XSS:指定`虚拟机栈`可以存放的最多的栈帧数量 - 递归调用时,递归的方法有多个 - 死循环递归和定义了大量的方法本地变量会报`java.lang.StackOverflowError`的Error,所以递归一定要有收敛条件,避免死循环栈溢出 - 如果虚拟机栈可以动态扩展,如果扩展时无法申请到足够内存时,则会抛出`java.lang.OutOfMemoryError` - 每个栈帧的大小都可能不一样
栈帧
局部变量表
内存空间编译期分配完成
方法运行期间大小不变
操作数栈
动态链接
方法出口
。。。
本地方法栈
- 执行带有`native`关键字的方法 - 可能会抛出`java.lang.StackOverflowError`和`java.lang.OutOfMemoryError`
JVM优化调优
类加载机制
JVM的类加载是通过ClassLoader及其子类来完成的,类的层次关系和加载顺序可以由下图来描述:  **1. Bootstrap ClassLoader:** 负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类 **2. Extension ClassLoader:** 负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包 **3. App ClassLoader:** 负责记载classpath中指定的jar包及目录中class **4. Custom ClassLoader:** 属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader ---------- 加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个classloader已加载就视为已加载此类,保证此类只所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
双亲委派
OSGI(Open Service Gateway Initiative)
GC
回收算法
对象存活判断
引用计数法
可达性分析
GC Roots
虚拟机栈中本地变量表引用的对象
方法区中
类静态变量引用的对象
常量引用的对象
本地方法栈中JNI引用的对象
不可达还会发生什么
finalize()
引用
强引用
软引用
内存不足时回收
缓存
弱引用
下一次垃圾回收会回收掉,不管内存是否足够
大对象
虚引用
缺点
无法处理循环引用
引用产生和消除时存在加减操作,影响性能
标记-清除算法
优点
first
缺点
效率不高
回收后的空间是不连续的
复制算法
优点
实现简单、高效,不用考虑碎片
缺点
要分一块出来做复制
标记-整理算法
垃圾回收器
Minor GC
新生代收集器
Serial
ParNew
Parallel Scavenge
Full GC/Major GC
老年代收集器
Serial Old
Parallel Old
CMS
Java运行类库
基本数据类型
boolean
char
byte
short
int
long
float
double
集合
[Java集合常用类继承关系图示-个人博客](https://blog.csdn.net/qq_25885525/article/details/80793997)
Collection
List
ArrayList
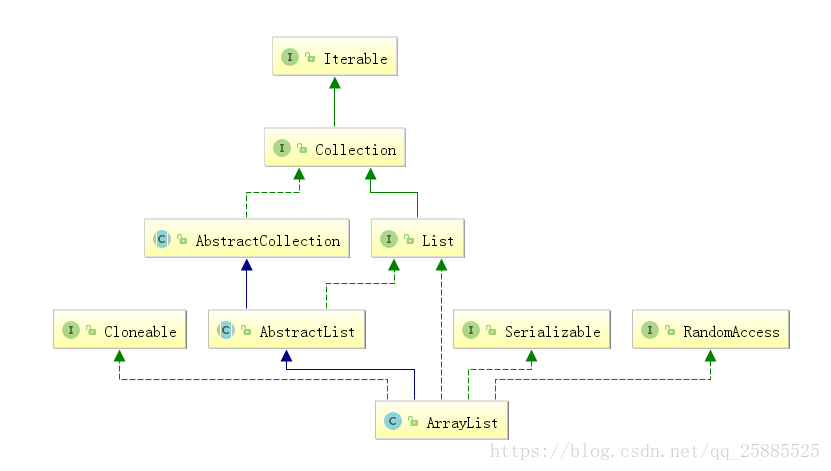
可null、线程不安全
底层动态数组实现
查改快、尾部添加快、删除慢、中间插入慢
动态扩容
JDK1.6默认10、1.5倍+1(整除实现)
JDK1.7默认0、1.5倍扩容(位运算实现)、加了容量上限
JDK1.8默认0、1.5倍扩容
Vector
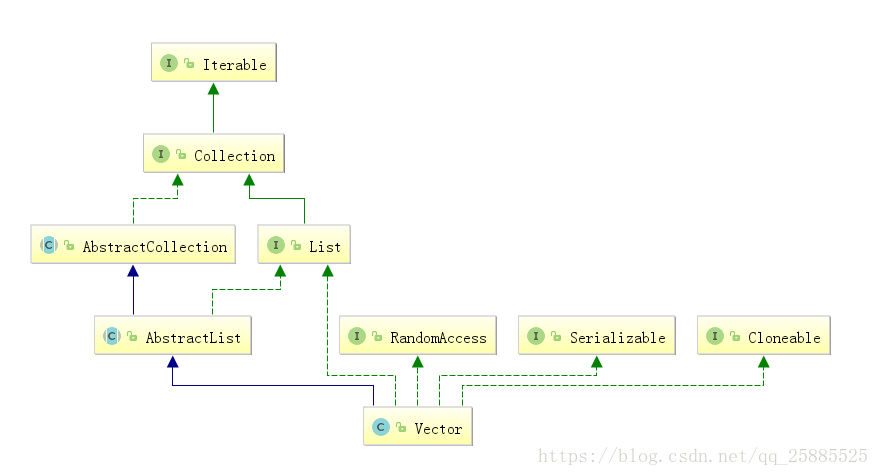
底层动态数组实现
效率低
Stack
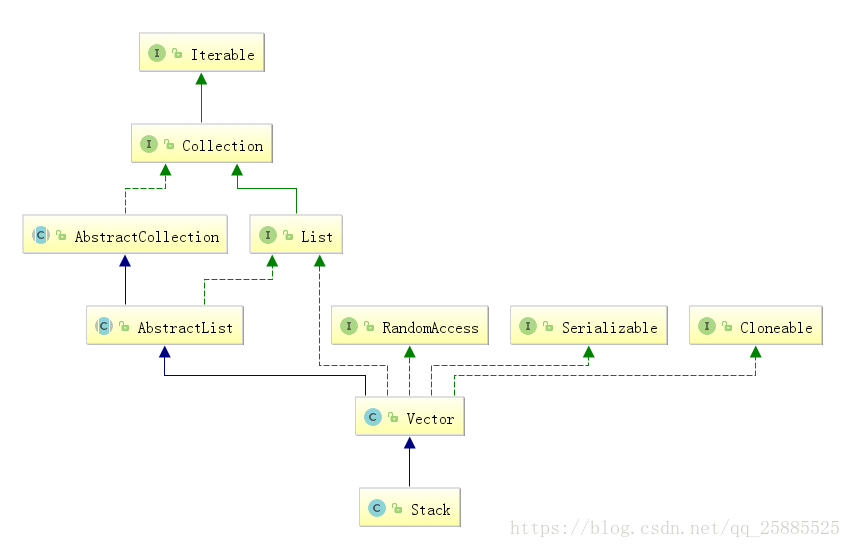
先进后出(FILO)
LinkedList
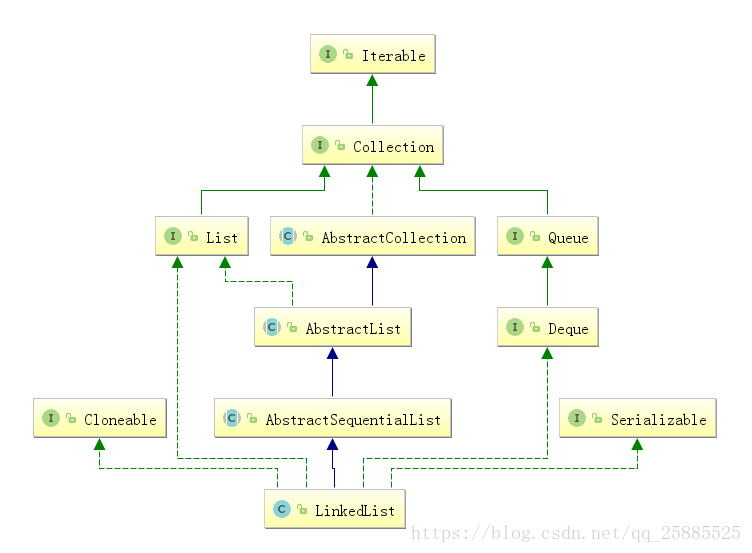
底层基于双向循环链表
添加快、删除快、查询需要遍历,较慢
CopyOnWriteArrayList
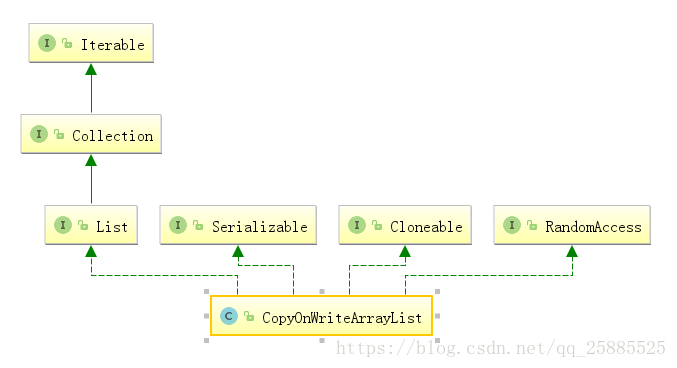 底层实现添加的原理是先copy出一个容器(可以简称副本),再往新的容器里添加这个新的数据,最后把新的容器的引用地址赋值给了之前那个旧的的容器地址,但是在添加这个数据的期间,其他线程如果要去读取数据,仍然是读取到旧的容器里的数据。
数据最终一致、占用内存大
Set
HashSet
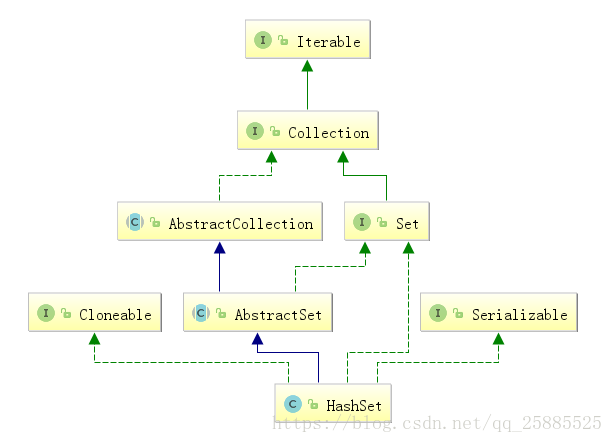
equals、hashCode判断是否相等
hash算法存取快
HashMap实现
LinkedHashSet
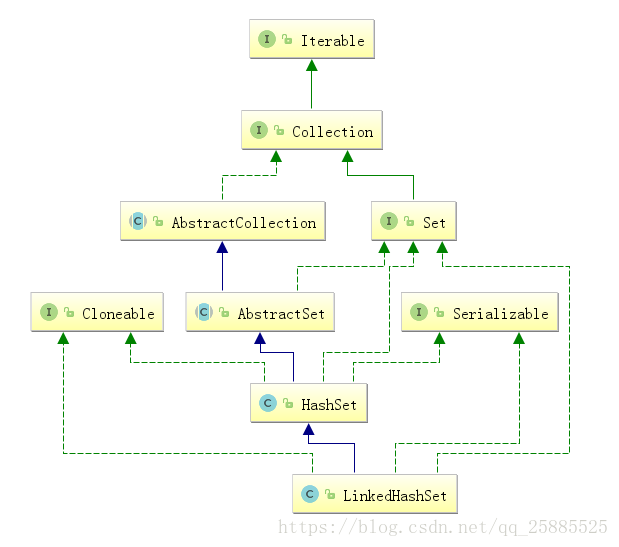
链表维护顺序
LinkedHashMap实现
随机访问慢、迭代访问快
TreeSet
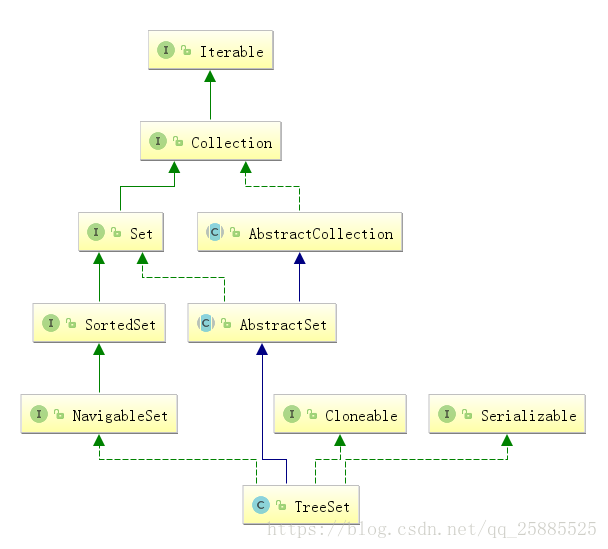
红黑树结构
TreeMap实现
EnumSet
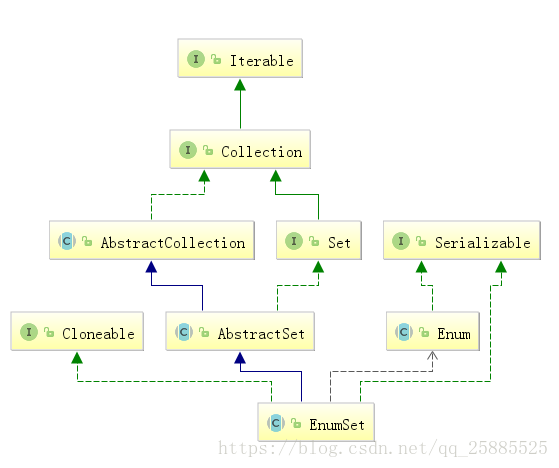
Queue
Deque
ConcurrentLinkedDeque
ConcurrentLinkedDeque
ConcurrentLinkedQueue
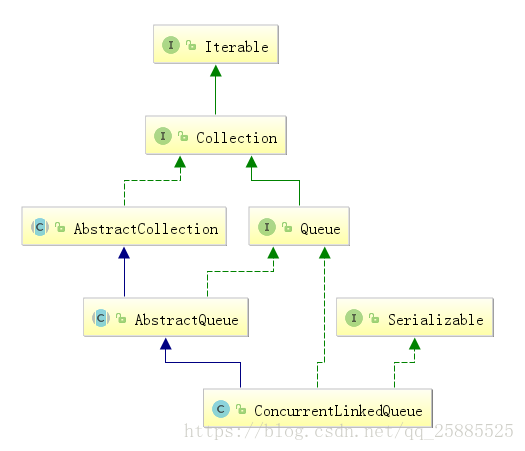
LinkedBlockingQueue
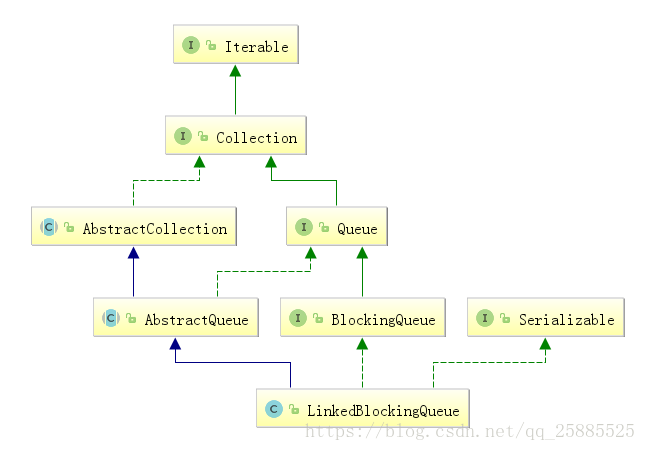
Map
HashMap
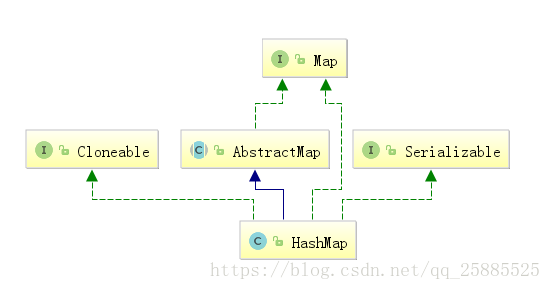 - java2引入 - key和value都可以为null - 无序 - key不可重复 - 线程不安全的
1.8之前底层数组+链表实现
1.8之后底层数组+链表/红黑树实现
LinkedHashMap
- 有序 - 线程不安全
HashTable
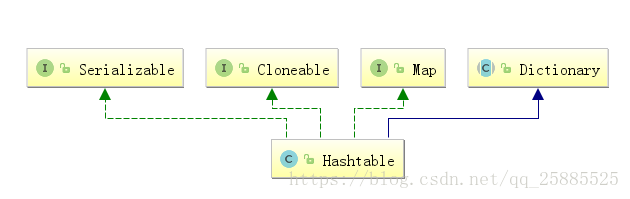 - key和value均不能null - 线程安全的
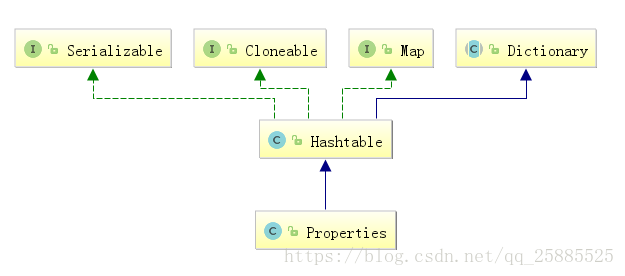
Properties
WeakHashMap
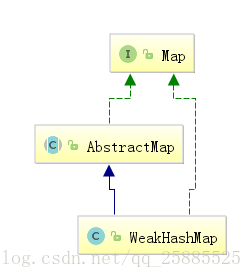
弱键,可能被GC
TreeMap
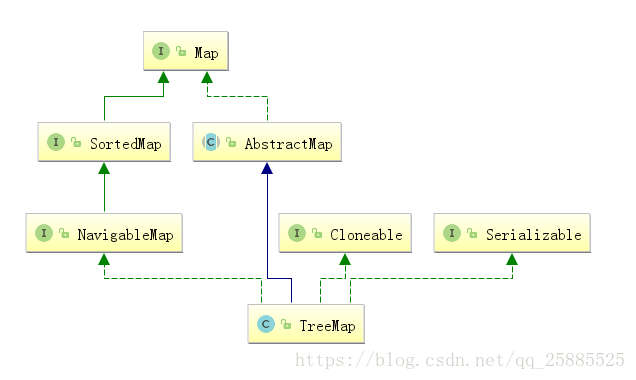 - 红黑树算法实现 - 线程不安全
红黑树结构
支持两种顺序
自然顺序
定制顺序
EnumMap

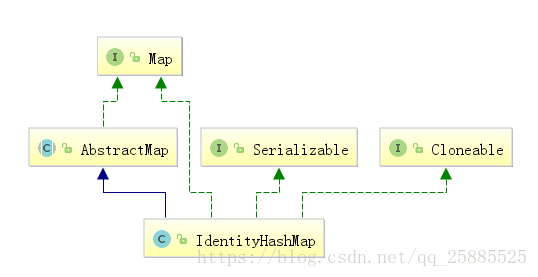
IdentityHashMap
ConcurrentHashMap
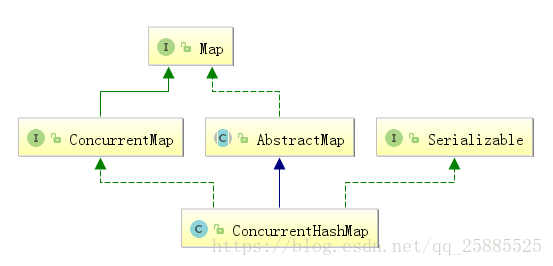 - java5引入 - 线程安全的 - 分段锁
底层分段的数组+链表实现
jdk1.7分段锁
jdk1.8CAS和synchronized只锁首节点
ConcurrentSkipListMap
 - java6引入 - 线程安全
java6引入
Collections
集合工具类
工具类
Google guava
Apache conmon lang/BeanUtils/Conllections/IO
JSON
[JSON官网](http://www.json.org/json-zh.html)[几种常用JSON库性能比较](https://blog.csdn.net/vickyway/article/details/48157819)[JSON风格指南](https://github.com/darcyliu/google-styleguide/blob/master/JSONStyleGuide.md)
fastjson
[JSON字符串和java对象的互转【json-lib】](https://www.cnblogs.com/free-dom/p/5801866.html)
gson
jackson
多线程
状态
New
Runnable
Blocked
Waiting
Timed-Waiting
Termnated
ThreadLocal
适用场景
连接池
session管理
泛型
IO
NIO
同步非阻塞IO
java1.4引入NIO
java7完善NIO
BIO
- Blocking IO- 同步阻塞IO
AIO
异步非阻塞IO
Throwable
Error
Exception
运行时异常
编译时异常
序列化
不参与序列化的情况
静态变量
transient修饰的变量
父类未实现序列化,则父类的变量不参与序列化
反射
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。 [Java基础之反射](https://blog.csdn.net/sinat_38259539/article/details/71799078)
获取对象的三种方式
对象.getClass()
类.class
Class.forName(String calssName)---常用
调用方法
getConstructor()
获取公有构造方法
getDeclaredConstructors()
获取所有构造方法
newInstance()
调用构造方法
setAccessible(true)
解除私有限定
获取变量信息
getFields()
获取所有公有变量
getDeclaredFields()
获取所有变量
获取方法信息
getMethods()
获取所有公有方法
invoke()
getDeclaredMethod()
获取所有方法
clone
servlet
组件
Servlet
Filter
Listener
socket
连接数据库
连接数据库步骤
1.加载驱动类(JDBC驱动)
2.建立连接(客户端Connection)
3.建立语句集(SQL Statement)
4.执行语句集(execute())
6.关闭结果、语句,连接
数据库连接池
dbcp
应用广泛,比较稳定,
速度稍慢,在大并发量的压力下稳定性有所下降,不提供连接池监控
c3p0
持续运行的稳定性相当不错,在大并发量的压力下稳定性也有一定保证
不提供连接池监控
proxool
提供连接池监控
稳定性存在问题
druid
完善的监控系统,可扩展性强,稳定
HikariCP
号称性能最好的连接池
BoneCP
Javac
Java5
2004年10月发布 [New Features and Enhancements J2SE 5.0](https://docs.oracle.com/javase/1.5.0/docs/relnotes/features.html) [Java5新特性](https://segmentfault.com/a/1190000004417288)
泛型
枚举
自动装箱、自动拆箱
可变参数
Annotations
Tiger预定义的三种标准annotation
@Override
指出重写父类方法
@Deprecated
指出子类不能覆盖的方法
@SupressWarnings
去掉编译期警告
自定义annotation
meta-annotation
@Target
@Retention
@Documented
@Inherited
Annotation的反射
foreach
静态导包
格式化
新线程模型和并发库
ConcurrentHashMap
CopOnWriteArrayList
Java6新特性
2006年4月发布 [Update Release Notes](http://www.oracle.com/technetwork/java/javase/releasenotes-136954.html) [Java6新特性](https://segmentfault.com/a/1190000004417536)
Java7新特性
2011年7月28日发布 [Java SE 7 Update Release Notes](http://www.oracle.com/technetwork/java/javase/7u-relnotes-515228.html) [Java7新特性](https://segmentfault.com/a/1190000004417830)
switch支持字符串
multicatch和final重抛
try-with-resources
try( ObjectInputStream on = new ObjectinputStream(new FileInputStream("XXX.txt"))){}
支持泛型实例化类型自动推断
钻石语法
NIO.2 API
新增一些获取环境信息的工具方法System类
Boolean类型反转,空指针安全、参与位运算
两个char间的equals
boolean Character.equalslgnoreCase(char ch1,char cha2)
安全的加减乘除
Java8新特性
2014年3月发布 [What's New in JDK 8](http://www.oracle.com/technetwork/java/javase/8-whats-new-2157071.html) [Java8新特性](https://segmentfault.com/a/1190000004417536) [官方Java8更新说明](http://www.oracle.com/technetwork/java/javase/8-whats-new-2157071.html)
Lambda表达式
[Java Lambda表达式入门](https://blog.csdn.net/renfufei/article/details/24600507)
Collectons.sort(names, (a, b) -> b.compareTo(a));
集合的流氏操作
[将Java代码重构为Java8 Stream 风格三则示例](https://blog.csdn.net/TCXP_for_wife/article/details/52094445) [Java8 新特性之流式数据处理](https://www.cnblogs.com/shenlanzhizun/p/6027042.html)
List<User> users =users.stream().filter(user -> user.getAge() > 18).map(user::getName).limit(3).collect(toList());
方法和构造函数引用
Integer::valueOf
接口默认方法
日期处理类LocalDate、LocalTime
Java9新特性
2017年09月22日发布 [Java Platform, Standard Edition What’s New in Oracle JDK 9](https://docs.oracle.com/javase/9/whatsnew/toc.htm#JSNEW-GUID-C23AFD78-C777-460B-8ACE-58BE5EA681F6) [Java9新特性概述](https://www.ibm.com/developerworks/cn/java/the-new-features-of-Java-9/index.html)
模块化
Java10新特性
2018年03月20日发布 [JDK 10 Release Notes](http://www.oracle.com/technetwork/java/javase/10-relnote-issues-4108729.html)
局部变量类型推断
Java11新特性
2018年9月25日发布 [OpenJDK 11](http://openjdk.java.net/projects/jdk/11/)
Nest-Based Access Control
Dynamic Class-File Constants
Improve Aarch64 Intrinsics
Epsilon: A No-Op Garbage Collector
Remove the Java EE and CORBA Modules
HTTP Client (Standard)
Local-Variable Syntax for Lambda Parameters
Key Agreement with Curve25519 and Curve448
Unicode 10
Flight Recorder
ChaCha20 and Poly1305 Cryptographic Algorithms
Launch Single-File Source-Code Programs
Low-Overhead Heap Profiling
Transport Layer Security (TLS) 1.3
ZGC: A Scalable Low-Latency Garbage Collector
Deprecate the Nashorn JavaScript Engine
Deprecate the Pack200 Tools and API
Java12新特性
2019年3月19日发布 [OpenJDK12](http://openjdk.java.net/projects/jdk/12/)
Shenandoah: A Low-Pause-Time Garbage Collector (Experimental)
Microbenchmark Suite
Switch Expressions (Preview)
JVM Constants API
One AArch64 Port, Not Two
Default CDS Archives
Abortable Mixed Collections for G1
Promptly Return Unused Committed Memory from G1
Groovy
Kotlin
[Kotlin代码检查在美团的探索与实践](https://tech.meituan.com/Kotlin_code_inspect.html) [Kotlin官网](https://kotlinlang.org/) [Kotlin中文站](https://www.kotlincn.net)
其他
Session/Cookie
压缩
算法
Gzip
高压缩率,慢速
deflate
deflate(lvl=1)
低压缩率,快速
。。。
deflate(lvl=9)
高压缩率,慢速
Bzip2
LZMA
XZ
LZ4
LZ4(high)
LZ4(fast)
很快,可达320M/S
LZO
Snappy
Snappy(framed)
Snappy(normal)
编码
ASCII
ISO-8859-1
GB2312
GBK
GB18030
UTF-16
UTF-8
面试
面试题
[Java面试题全集(上)](https://blog.csdn.net/jackfrued/article/details/44921941) [Java面试题全集(中)](https://blog.csdn.net/jackfrued/article/details/44931137) [Java面试题全集(下)](https://blog.csdn.net/jackfrued/article/details/44931161) [面试题专栏](https://userzhao.coding.me/categories/interview/)
非技术因素
责任心
团队精神
主动性
性格
年龄
期待
职业规划
工作业绩
技术攻关
应急
创新
分享
项目管理
程序开发案例
项目设计案例
技术面试范围
Java基础
集合
子主题
#### 1. HashMap是使用了哪些方法来有效解决哈希冲突的:1. 使用链地址法(使用散列表)来链接拥有相同hash值的数据;2. 使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均;3. 引入红黑树进一步降低遍历的时间复杂度,使得遍历更快;#### 2. HashMap为什么不直接使用hashCode()处理后的哈希值直接作为table的下标?答:hashCode()方法返回的是int整数类型,其范围为-(2 ^ 31)~(2 ^ 31 - 1),约有40亿个映射空间,而HashMap的容量范围是在16(初始化默认值)~2 ^ 30,HashMap通常情况下是取不到最大值的,并且设备上也难以提供这么多的存储空间,从而导致通过hashCode()计算出的哈希值可能不在数组大小范围内,进而无法匹配存储位置;#### 面试官:那怎么解决呢?答:HashMap自己实现了自己的hash()方法,通过两次扰动使得它自己的哈希值高低位自行进行异或运算,降低哈希碰撞概率也使得数据分布更平均;在保证数组长度为2的幂次方的时候,使用hash()运算之后的值与运算(&)(数组长度 - 1)来获取数组下标的方式进行存储,这样一来是比取余操作更加有效率,二来也是因为只有当数组长度为2的幂次方时,h&(length-1)才等价于h%length,三来解决了“哈希值与数组大小范围不匹配”的问题;#### 面试官:为什么数组长度要保证为2的幂次方呢?答:只有当数组长度为2的幂次方时,h&(length-1)才等价于h%length,即实现了key的定位,2的幂次方也可以减少冲突次数,提高HashMap的查询效率;如果 length 为 2 的次幂 则 length-1 转化为二进制必定是 11111……的形式,在于 h 的二进制与操作效率会非常的快,而且空间不浪费;如果 length 不是 2 的次幂,比如 length 为 15,则 length - 1 为 14,对应的二进制为 1110,在于 h 与操作,最后一位都为 0 ,而 0001,0011,0101,1001,1011,0111,1101 这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!这样就会造成空间的浪费。#### 面试官:那为什么是两次扰动呢?答:这样就是加大哈希值低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性&均匀性,最终减少Hash冲突,两次就够了,已经达到了高位低位同时参与运算的目的;#### 3. HashMap在JDK1.7和JDK1.8中有哪些不同?答:| 不同 | JDK 1.7 | JDK 1.8 || ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ || 存储结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 || 初始化方式 | 单独函数:`inflateTable()` | 直接集成到了扩容函数`resize()`中 || hash值计算方式 | 扰动处理 = 9次扰动 = 4次位运算 + 5次异或运算 | 扰动处理 = 2次扰动 = 1次位运算 + 1次异或运算 || 存放数据的规则 | 无冲突时,存放数组;冲突时,存放链表 | 无冲突时,存放数组;冲突 & 链表长度 < 8:存放单链表;冲突 & 链表长度 > 8:树化并存放红黑树 || 插入数据方式 | 头插法(先讲原位置的数据移到后1位,再插入数据到该位置) | 尾插法(直接插入到链表尾部/红黑树) || 扩容后存储位置的计算方式 | 全部按照原来方法进行计算(即hashCode ->> 扰动函数 ->> (h&length-1)) | 按照扩容后的规律计算(即扩容后的位置=原位置 or 原位置 + 旧容量) |#### 4.为什么HashMap中String、Integer这样的包装类适合作为K?答:String、Integer等包装类的特性能够保证Hash值的不可更改性和计算准确性,能够有效的减少Hash碰撞的几率1. 都是final类型,即不可变性,保证key的不可更改性,不会存在获取hash值不同的情况2. 内部已重写了`equals()`、`hashCode()`等方法,遵守了HashMap内部的规范(不清楚可以去上面看看putValue的过程),不容易出现Hash值计算错误的情况;#### 面试官:如果我想要让自己的Object作为K应该怎么办呢?**答:重写`hashCode()`和`equals()`方法1. **重写hashCode()是因为需要计算存储数据的存储位置**,需要注意不要试图从散列码计算中排除掉一个对象的关键部分来提高性能,这样虽然能更快但可能会导致更多的Hash碰撞;2. **重写equals()方法**,需要遵守自反性、对称性、传递性、一致性以及对于任何非null的引用值x,x.equals(null)必须返回false的这几个特性,**目的是为了保证key在哈希表中的唯一性**;好文章列表1. [全网把Map中的hash()分析的最透彻的文章,别无二家。](
ArrayList
#### 1.ArrayList和LinkedList的区别?答:1. LinkedList 实现了 List 和 Deque 接口,一般称为双向链表;ArrayList 实现了 List 接口,动态数组;2. LinkedList 在插入和删除数据时效率更高,ArrayList 在查找某个 index 的数据时效率更高;3. LinkedList 比 ArrayList 需要更多的内存;#### **面试官:Array 和 ArrayList 有什么区别?什么时候该应 Array 而不是 ArrayList 呢?**答:它们的区别是:1. Array 可以包含基本类型和对象类型,ArrayList 只能包含对象类型。2. Array 大小是固定的,ArrayList 的大小是动态变化的。3. ArrayList 提供了更多的方法和特性,比如:addAll(),removeAll(),iterator() 等等。对于基本类型数据,集合使用自动装箱来减少编码工作量。但是,当处理固定大小的基本数据类型的时候,这种方式相对比较慢。
多线程
JVM
IO
设计模式
子主题
框架
Spring体系
SpringBoot体系
SpringCloud体系
Dubbo体系
Mybatis
Hibernate
Netty
分布式
分布式事务
分布式缓存
分布式通信
子主题
子主题
微服务
注册中心
服务发现
服务网关
配置中心
负载均衡
服务治理
服务监控
数据库及中间件
Mysql
Oracle
Redis
Kafka
RabbitMQ
RocketMQ
ElasticSearch
Mongo
Zookeeper
数据结构
数组
队列
栈
树
红黑树
B-Tree
B+Tree
算法
排序算法
查找算法
工具使用
Git
Maven
Linux
Docker
K8s
Jenkins
Tomcat
Nginx
项目经验
项目内职责
贡献
收获
项目痛点及解决方案
区块链
比特币
以太坊
超级账本
云计算
服务模式
IaaS
IaaS(Infrastructure as a Service)基础设施即服务
PaaS
PaaS(Platform as a Service)平台即服务
SaaS
SaaS(Software as a Service)软件即服务
Serverless
DaaS
DaaS(Data as a Service)数据即服务
CaaS
CaaS(Communications as a Service)
FaaS
FaaS(Functions as a Service)
BaaS
BaaS(Backend as a Service)后端即服务
组成
DevOps
持续交付(Continuous Delivery)
微服务(MicroServices)
敏捷基础设施(Agile Infrastructure)
康威定律(Conways Law)
部署模型
公有云
私有云
社区云
混合云
特征
按需自助服务
多租户的资源池
快速伸缩
广泛的网络访问
按使用量收费的服务
人工智能
数学基础
机器学习
深度学习
常用框架
DL4J
Deeplearning4j- 使用java和Scala编写的深度学习库- 支持GPU
神经网络
应用场景
IOT