导图社区 光泉-程前访谈“宠物家电赛道”霍曼烘干箱刘坤
光泉-程前访谈“宠物家电赛道”霍曼烘干箱刘坤
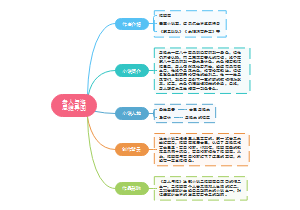
这是一篇关于7-程前20230826霍曼烘干箱-刘坤的思维导图,主要内容包括:八、“和光泉一起学习”梳理总结,七、未来,六、信念,五、团队,四、短视频平台电商的意义,三、开始创业,二、为什么创业,一、创始人背景。
编辑于2024-04-16 21:03:30- 程前朋友圈
- 宠物家电赛
- 霍曼烘干箱
- 42-《人生只有一件事》
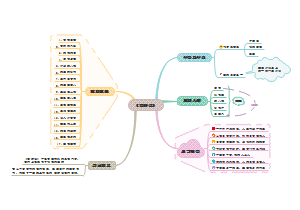
这是一篇关于42-《人生只有一件事》的思维导图,主要内容包括:一、基础信息,二、内容大纲与章节逻辑,三、关键知识点与理论模型,四、金句提炼,五、争议与延展,六、案例与工具,七、总结。
- 40-《即兴演讲》
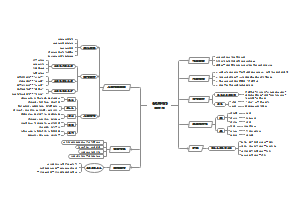
这是一篇关于40-《即兴演讲》的思维导图,主要内容包括:八、遇见光整理分享,七、争议与延展,六、关联扩展,五、金句提炼,四、关键知识点与案例,三、核心理论提炼,二、内容大纲与章节逻辑,一、基础信息。
- 39-《如何让你爱的人爱上你》
这是一篇关于39-《如何让你爱的人爱上你》的思维导图,主要内容包括:八、遇见光整理分享,七、【记忆强化系统】,六、【延展知识网络】,五、【认知升级模块】,四、【实战工具库】,三、【核心理论模型】,二、【内容结构全景】,一、【基础信息体系】。
光泉-程前访谈“宠物家电赛道”霍曼烘干箱刘坤
社区模板帮助中心,点此进入>>
- 42-《人生只有一件事》
这是一篇关于42-《人生只有一件事》的思维导图,主要内容包括:一、基础信息,二、内容大纲与章节逻辑,三、关键知识点与理论模型,四、金句提炼,五、争议与延展,六、案例与工具,七、总结。
- 40-《即兴演讲》
这是一篇关于40-《即兴演讲》的思维导图,主要内容包括:八、遇见光整理分享,七、争议与延展,六、关联扩展,五、金句提炼,四、关键知识点与案例,三、核心理论提炼,二、内容大纲与章节逻辑,一、基础信息。
- 39-《如何让你爱的人爱上你》
这是一篇关于39-《如何让你爱的人爱上你》的思维导图,主要内容包括:八、遇见光整理分享,七、【记忆强化系统】,六、【延展知识网络】,五、【认知升级模块】,四、【实战工具库】,三、【核心理论模型】,二、【内容结构全景】,一、【基础信息体系】。
- 相似推荐
- 大纲