导图社区 高中历史《新民主主义革命》
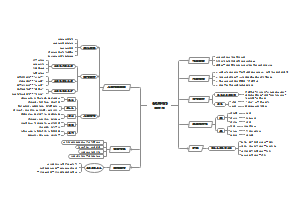
高中历史《新民主主义革命》思维导图,新民主主义革命,是由中国共产党领导人毛泽东创造的一个历史阶段概念,指从1919年五四运动到1949年中华人民共和国成立为止的一段时间内,由中国共产党领导的资产阶级民主革命。
私域流量-运营四个阶段(规划、策略、营销、触达)
专升本语文常识隋唐五代,擅长七律,七绝,《阿房宫赋》《赤壁赋》《过华清宫绝句》《江南春绝句》《清明》《泊秦》《秋夕);赋作散文对后世影响较大。
竞品分析是产品经理的一项常规工作,分析质量决定着决策质量,影响着对业务取长补短的效果。 但在竞品分析时,常遇到以下问题: ❓没有养成日常习惯,分析时无从下手 ❓企图以此寻找需求或印证自己的观点 ❓由领导发起,找模板套公式,交作业 ❓分析维度杂乱浅显,结论无参考价值 ✍🏻️那么,竞品分析应该怎么做呢?
社区模板帮助中心,点此进入>>
《老人与海》思维导图
《钢铁是怎样炼成的》章节概要图
《傅雷家书》思维导图
《阿房宫赋》思维导图
《西游记》思维导图
《水浒传》思维导图
《茶馆》思维导图
《朝花夕拾》篇目思维导图
英语词性
生物必修一
新民主主义革命
总结升华
学习误区
抗战胜利的根本原因是中共的领导
抗战胜利的根本原因是全民族抗战的结果,包括国民党正面抗战和共产党敌后抗战
知能提升
如何客观、公正评价个人,尤其是领袖的巨大作用
比较分析,明确阶段特征
马克思主义和中国实际结
新旧民主主义的比较
学法指导
深刻领会共产党诞生的意义
确立科学理论马克 思主义为指导思想
形成坚定 领导核心
立足对中国 国情的分析
斗争最坚决
分析国民党的抗战表现
片面抗战路线
沉重打击日本侵略者
出现正面战场的大溃退
发动反攻摩擦
国民党政权的本性决定
没有破裂统一战线
支持反法西斯战争
形成共同对敌局面
参与国际合作,有利于国际地位提高
总结抗战胜利的影响
中国历史的转折,增强国人的自尊心和自信心
增强了民主意识,有利于形成反对国民党的政治同盟
提高中国的国际地位
增强了中国的国际影响
知识梳理
五四运动
原因
北洋军阀的黑暗统治, 国内阶级矛盾尖锐 巴黎和会中国外交的失败 俄国十月革命的影响等
概况
开始 发展 高潮
影响
体现爱国精神,显示工人阶级力量 新旧民主主义的分水岭
结果
罢免三个卖国拒绝和约签字
中国共产党成立和工人运动
党的成立
条件
条件无产阶级的发展壮大
马克思主义的传播
共产党早期组织的建立
共产国际的帮助
时间:1921年地点:上海和嘉兴南湖
中国革命的面貌焕然一新
工人运动的 兴起和发展
领导机构:中国劳动组合书记部
概况:工会组织成立和工人罢工开展
成就:建立革命统一战线
国民大革命
国共合作
共产党寻求同盟者
国民党赞同合作
共产国际的支持
标志
国民党“一大
作用
壮大革命力量作用
推动了国民革命发展
北伐
对象
吴佩孚、孙传芳、张作霖
分路进军基本推翻军阀统治
成果
基本上统一全国
两次反革命政变
四一二政变
七一五政变
国共十年对峙
武装斗争
武装斗争方针的确定 八七会议
三次武装斗争
南昌起义打响武装起义的第一枪
秋收起义为建立井冈山革命根据地创造条件
广州起义 对国民党反动统治的再次反击
土地革命
内容
变封建、半封建土地所 有制为农民土地所有制
实质
建立农民土地所有制,调动土地革命 农民积极性,促进革命发展
巩固和发展了农村根据地 调动农民革命积极性
农村革命根据地的建立和发展
井冈山根据地建立的条件
根据地的建立
1928年和朱德、陈毅会师,革命力量壮大
根据地的发展
工农武装割据理论
内容:武装斗争、土地 革命、根据地建设结合
意义:马克思主义和 中国革命结合的典范
反围剿和红军的长征
反围剿斗争
农村根据地的大发展
中华苏维埃共和国的成立
长征
背景
第五次反围剿失利
为保存革命力量进行战略转移
1934年10月开始
遵义会议
三大主力会师
意义
使中国革命转危为安
保留了革命的主干力量
播下了革命的火种
西安事变:扭转时局的关键
日本对中国的侵略扩大
中国共产党主张团结抗日
国民党顽固坚持“攘外必先安内”政策
张杨扣留蒋介石,逼蒋抗日
亲日派密谋轰炸西安
在中共努力下和平解决
成为扭转时局的关键
为国共合作和统一战线的建立创造条件
解放战争
两种命运的选择
重庆谈判
签订《双十协定》
政治协商会议
内容:围绕政府组织等五个问题讨论
结果:确认和平 建国方针,否定国民党独裁
战争爆发
1946年国民党撕毁协定,进攻中原解放区
全面进攻和重 点进攻的粉碎
全面进攻
粉碎全面进攻 进攻其他解放区 进攻中原解放区
重点进攻
粉碎重点进攻 进攻山东解放区 进攻陕甘宁解放区
战略反攻和决战
战略反攻
作用:扭转战局 中原野战军千里跃进大别山
战略决战
平津战役 淮海战役 辽沈战役
为全国解放奠定基础
国民党主力被消灭
七届二中全会
全国即将解放
解决全国解放后路线政策
告警惕“糖衣炮弹”的袭击
规定了总任务 和基本政策
党的工作重心转移到城市
为新中国的成立做了准备
解决了新民主主义向社会主义转变的重大问题
北平谈判和进军江南
北平谈判
结果 国民党拒绝签字
进军江南
渡江战役
解放全国
解放战争的胜利
毛泽东思想的胜利
改变了国际政治格局
标志百年屈辱和分裂的历史结束
抗日战争
日本的全面侵华和掠夺
日本的全面侵华
日军的全面进攻
七七事变
日军的暴行
七三一部队和细菌战等
三光”政策
南京大屠杀等
日本对中国的掠夺
掠夺矿产资源等
掠夺劳动力
掠夺土地和农产品
掠夺金银等
两条路线和两个战场
两条路线
国民党片面抗战路线
中共全面抗战路线
两个战场
正面战场
敌后抗日根据地的建立和扩大
抗日民族统一战线的建立
中国的抗日民族统一战线政策
统一战线的建立
团结抗日 是大势所趋
中日矛盾成为中国 社会的主要矛盾
中国确立统一战线政策
1937年国民党公布《国共合作宣言)
统一战线的维护
保证了抗战的胜利
实现了全民族的抗战
中国远征军入缅作战
目的
共同对日作战
确保国际交通线
1942年远征军进入缅甸失利
仁安羌大捷
远征军反攻
增强了国际合作
支援了国内战场
抗战的胜利
日本的无条件投降
第一次取得反侵略战争的胜利
增强了民族自尊心和自信心
中国国际地位得到提高