导图社区 CFA一级数量思维导图
- 164
- 1
- 0
- 举报
CFA一级数量思维导图
一篇关于CFA一级数量思维导图,包含货币的时间价值、抽样与估计、假设检验等。
编辑于2023-11-24 14:21:22- CFA
- 证券投资
- 相似推荐
- 大纲
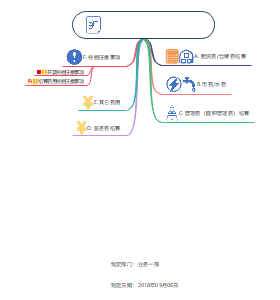



Study Session 1-7 Quantitative Methods
用统计方法研究变量和变量之间关联 方法理解 45s/题
R1 The Time Value of Money
1.Rate
Type
Required rate of return
R=Rn +RP
Required interest rate on a security = nominal risk-free rate + default risk premium + liquidity risk premium + maturity risk premium
default risk premium
liquidity risk premium
maturity risk premium
Discount rate
Opportunity cost
Nominal risk-free rate
Rr=Rn-i^e
Nominal risk-free rate = real risk-free rate + expected inflation rate
2.EAR
Effective annual rate 有效年利率
HPR=(FV-PV)/PV
EAR=(1+R/m)^m-1
其中R指的是Nominal rate,要求回报率,遇到Compounded monthly的利率需要主要和真实收益率区别
EAR=e^r-1
the future value of continuously compounding,保持r不变,m趋于无穷
FV=PV*(1+EAR)
FVn=PV*(1+EAR)^n=PV*(1+r/m)^(m*n)
Logarithm operation

a^b=c logac=b
3.Annuity
Elements
N
I/Y
PV
FV
PMT
Type
Annuity due
先付年金
Ordinary Annuity
后付年金
Perpetuity
永续年金
PV=PMT1/R
用数学方式推得永续年金等于第一笔PMT除以利息,P0=D1/R
Application

Uneven cash flows
单笔非相同现金流计算,PV等于每一笔折现,计算器PMT=0
Calculator usage
小数点调整成四位

链式计算/代数计算
2ND+Format 
功能键
单变量先数字后按键
双变量数字-按键-数字
Annuity五元素四缺一
BGN和END设置
AMORT
Pn和Pn+1,第n期期初到第n期期末
BAL第n期期末负债余额
PRN第n期偿还的本金
INT第n期偿还的利息
R2 Organizing, Visualizing, and Describing Data
1. Types of Data
Structure Data

Numerical data
或称quantitative data,数值数据
Continuous data
一段区间内可能性无穷
Discrete data
一段区间内取值可能性有限
Categorical data
分类数据
Nominal data
名目数据,只为区分,没有排序,比如男女
Application

Ordinal data
有序数据,比如差、中、好等
Unstructured data (alternative source)
非结构化数据,相对结构化数据可以在表格中呈现,非结构化数据(非传统数据)不可以在表格中呈现,比如聊天记录,检索数据等 
Variable
变量,未发生的可能性结果
Observation
观测值,已发生的结果
One-dimensional array
单维度数据 
Time-series data
时间维度数据
Application

Cross-sectional data
截面维度数据
Two-dimensional rectangular array (data table)
双维度矩阵列,包含横纵轴两个维度 
Panel data
面板数据
2. Data Visualization
数据展现形式 
Number data
数值型数据(展现形式)
Frequency distribution
频数分布(表) 
Absolute Frequency
绝对频数
Relative Frequency
相对频数
Cumulative Absolute Frequency
Cumulative Relative Frequency
Histogram
直方图,也可以理解为频数分布的另外一种形式 
Polygon
折线图
Scatter Plot
散点图,描述两个变量之间的潜在关联,和相关系数相关 
Categorical Data
分类型数据展现形式
Contingency Table
联列表,包含各类属性的联列,其中包含两个属性的频数为Joint Frequency,只包含一个属性的频数总和为Marginal Frequency 
Confusion matrix
混淆表,通常情况下用来评价业绩表现,同时可以通过真实情况和预估情况的差异来评价预估情况的准确程度 
Chi-square test of independence
卡方检验,即可以测试数据和数据之间的独立性和期望值 
Bar Chart
柱状图 
Pareto Chart
帕累托柱状图 1.其柱状图按照频数从高到低排序(逐步减少) 2.其折线图按照累进相对频率变化(逐步增高,趋近1)
Grouped bar chart(clustered bar chart)
分组柱状图,注重其中占主要的个体
Stacked bar chart
堆叠柱状图,注重整体
Tree-Map
树状图,使用颜色和面积来进行呈现比例关系 
Application

Heat Map
热力图,主要使用颜色的深浅来描述严重程度 
Application

Line chart
线图,主要描述的是数值的变化 
Bubble line chart
气泡线图,可以增加线图描述的维度,比如气泡的颜色和大小
Unstructured data
Word Cloud
字云,针对非结构化数据,通过大小描述名字的出现频率,通过颜色来描述增减 
3. Measures of Central Tendency
Mode
众数 具有一个、两个、三个众数的数据集合,分别称为单峰的(unimodal)、双峰的(bimodal)、三峰的(trimodal)
Median
中位数
Mean

The Arithmetic Mean
算数平均,评价未来收益
The Weighted Mean
加权平均,应用Portfolio的权重
The Geometric Mean
几何平均,应用各期的收益率的平均值计算,复利思想,评价过去业绩表现 
The Harmonic Mean
调和平均,应用计算平均成本价格 
Selection of Different Means
A>=G>=H
可以按照字母表顺序记忆,当所有数相同,等号成立
4.Quantiles
分位数,fall at or below that value,小于等于这个数的占比(占比即用到Quartile /Quintile/Decile/Percentile),本身分位数不是描述的占比,而是被描述的这个数。
Quartile /Quintile/Decile/Percentile
4/5/10/100,应用在考试成绩中衡量名词
Ly = (n+1)y/100
位置Location,意味第几个数,而不是具体是哪个分位数,可以不是整数 n为总个数,1/y就是描述分位数的占比 
Box and whisker plot
箱线图,实质上是一个四分位数Quartile 其中interquartile就是第1分位数到第三个分位数的区间 
5. Dispersion
Absolute Dispersion
绝对离散程度,描述分布的范围是广泛还是集中的 
Range
极差,容易受极端值影响
MAD
Mean Absolute deviation平均绝对偏离,描述偏离均值距离的平均值 计算器无法公式计算,需要手动计算 
Variance
方差,方差可以用来描述风险(不确定性),对于均值的偏离程度描述,越偏离表示不确定(风险)越高,反之亦然 实际案例题目基本使用样本差或者样本方差
For population

For sample
分母用n-1 用无偏角度,用n-1更接近于总体方差;从自由度的角度,当了解均值和总个数时,一组数可以自由取的个数为n-1个 
Semivariance
半方差,即只考虑小于等于均值之后计算出的方差。可以统计基金在亏损时的离散程度(越小越高),赚钱的时候则不用考虑离散程度
Target Semivariance
目标半方差,小于等于目标值之后的方差
Calculator usage

Standard deviation
由于方差的是在原来单位上面进行了平方,为了和原来单位相同引入了标准差,即在方差基础上开根号
For population
For sample
Relative dispersion
相对离散程度
Coefficient of variation
变异系数,标准差和均值的比值,是一个相对均值mean的离散程度(Scale-free,是一个比值,没有单位) 每单位的均值对应的标准差,越大表示不确定(risk)越大 
Sharpe ratio
夏普比率,主要衡量portfolio的投资表现和风险的对应关系,越高越能表示单位风险(标准差)所获得的超额收益越高 
6. Skewness & kurtosis
Skewness
偏度 
Tpye
Symmetrical
无偏,S=0
Positive (right) skew
极端值出现在右边,右尾长,S>0,正偏
Negative (left) skew
极端值出现在左边
Mode/Median/Mean
可以理解在对称的情况下加入极端值对于三个参考值的影响程度 
Skewness calculation(power=3)
Return
从投资收益的角度,右偏的收益率分布更具有吸引力
Kurtosis
峰度  
Type
Mesokurtic
常峰态,K=0
Leptokurtic
高峰(尖峰)K>3
Platykurtic
低峰(矮峰)K<3
Kurtosis calculation(power=4)
Excess kurtosis
Sample kurtosis – 3
Leptokurtic——Fat tail
在方差相同的情况下,高峰对应肥尾,尾部出现极值可能性更高,反之亦然
7. Covariance &Correlation
 如果在等权重的情况下
Covariance
协方差,四个特点以及协方差表格计算 
Correlation Coefficient
相关系数 
Limitations to Correlation Analysis
 
R3 Probability Concepts
概率论
1.Basic Concepts,odds for/against
Form
关于事件,可以理解为分为互相独立;相加等于100% 
Objective Probability and Subjective probability

odds for/against

P(A)
Unconditional Probability (marginal probability): P(A) A事件自顾自发生的概率
P(A|B)
Conditional probability: P(A|B) 给定B事件的条件下A发生的概率
2.Calculation Rules for Probabilities
两个事件

Mutually exclusive
互斥事件 P(AB)=0 P(A or B)=P(A)+P(B)
Independent
互为独立事件 P(AB)=P(A)*p(B) P(A or B)=P(A)+P(B)-P(A)*P(B)
两个法则
Multiplication rule
乘法法则,AB两件事情同时发生的概率,Joint probability P(AB) 当A、B为独立互不影响的情况下P(AB)=P(A)*P(B) 
Addition rule
加法法则,需要减掉重复发生的中间面积,A、B互斥的情况下中间面积直接等于0 
Total probability formula
全概率公式 用韦恩图来理解,这里的W1和W2应为互斥 
3.Expected value and variance
某个随机变量的期望和方差 期望:本质上都是加权平均值,只是加权平均值的对象不同,可以理解为原来数的出现是等权的,而现在数的出现有了条件(权重) 方差:即加权情况下数值和加权平均数的偏差程度 所以不管期望和方差,都是在原来等权平均值和方差的公式都进行了加权修正 
Expected value
期望值本身是加权平均数的计算 
Variance
方差的本质在求期望,求的是(X-Ex)^2的期望,Ex是X的期望值 
4.Expected return and variance of portfolios
组合的收益和协方差(风险),协方差公式对应协方差矩阵 
Expected return of portfolios

Variance of portfolios of portfolios
组合方差 
两类以上组合的计算

With Correlation
组合中相关系数和协方差的关系 
Covariance &Correlation

Covariance
协方差,四个特点以及协方差表格计算(个人理解协方差和组合方差的区别在于协方差中不涉及权重,只包含对应波动关系) 
Correlation
相关系数  5.缺点  
5. Bayes' Formula
贝叶斯公式  
Application
An analyst has established the following prior probabilities regarding a company's next quarter's earnings per share (EPS) exceeding, equaling, or being below the consensus estimate. Prior Probabilities EPS exceed consensus 25% EPS equal consensus 55% EPS are less than consensus 20% Several days before releasing its earnings statement, the company announces a cut in its dividend. Given this new information, the analyst revises his opinion regarding the likelihood that the company will have EPS below the consensus estimate. He estimates the likelihood the company will cut the dividend, given that EPS exceeds/meets/falls below consensus, as reported below. Probabilities the Company Cuts Dividends, Conditional on EPS Exceeding/Equaling/Falling below Consensus P(Cut div | EPS exceed) 5% P(Cut div | EPS equal) 10% P(Cut div | EPS below) 85% The analyst thus determines that the unconditional probability for a cut in the dividend, P(Cut div), is equal to 23.75%. Using Bayes’ formula, the updated (posterior) probability that the company’s EPS are below the consensus is closest to: 85%. 72%. 20%. Solution Solution B is correct. Bayes’ Formula:Updated probability of event given the new informationwhere Updated probability of event given the new information: P(EPS below | Cut div); Probability of the new information given event: P(Cut div | EPS below) = 85%; Unconditional probably of the new information: P(Cut div) = 23.75%; Prior probability of event: P(EPS below) = 20%. Therefore, the probability of EPS falling below the consensus is updated as: P(EPS below | Cut div) = [P(Cut div | EPS below)/P(Cut div)] × P(EPS below) = (0.85/0.2375) × 0.20 = 0.71579 ~ 72% B is incorrect. It is the given P(Cut div | EPS below). C is incorrect. It simply multiplies the unconditional probability for a cut in the dividend with the conditional probability of a cut in the dividend given that EPS falls below consensus: P(Cut div) × P(Cut div | EPS below) = 0.2375 × 0.85 = 20.188.% Probability Concepts Learning Outcome Calculate and interpret and updated probability using Bayes' formula
6. Factorial & combination & permutation
阶乘,排列,组合 
Multiplication rule
乘法法则,可以理解为每个步骤有不同种做法,总共有多少种可能性,例如从A地到B地的途径顺序
Factorial
阶乘,例如5人排队拍照,即再乘法的基础上,步骤不变,但是可能性会越变越小
Labeling (or Multinomial)
贴标签,可以理解为5人拍照片,但是被进行了颜色分组,在原来的基础上需要去重相同的颜色计数(相当于独立的个体元素被某种属性的群体所代替)
Application

Combination
组合,可以理解为拍照时从5个人中选3个拍照(所以排列是特殊的贴标签,分为可以拍照标签和不可以拍照两种标签) 
Permutation
组合,在排列的基础上(5个人中选3个拍照片),进一步对3个人站的位置进行区别(这个步骤相当于做一次阶乘Factorial)
Calculator usage
Factorial阶乘

排列组合

R4 Common Probability Distributions
描述型统计学(分布)
1. Properties of discrete distribution and continuous distribution

Discrete random variables
Continuous random variables
Probability density function (p.d.f): f(x)
密度函数
Cumulative probability function (c.p.f): F(x)
累计概率函数,小于等于某个数的概率,这里的F(X)是最终的概率(即小于X取值时所围成的面积),不是y轴取值 
2. Discrete distribution
Discrete uniform distribution
离散均匀分布,掷骰子 1.离散,可数n有限 2.均匀,概率相等
Binomial distribution
二项分布和期望以及方差 1.伯努利分布(伯努利可以理解为掷一次硬币,二项分布可以理解为掷两次及以上硬币) 2.n次,确定n和p就能决定二项分布 3.计算r次试验的概率(后面的乘积表示分布在两种结果的N次结果,前面的系数可以理解为出现该状态的次数,即是组合而不是排列) 4.期望和方差 
Expectation&variance

Probability Calculation

Application
 
3. Continuous distribution
Continuous Uniform Distribution
连续均匀分布 1.不可数 2.相同长度概率相等 3.计算概率是线段比值 
Normal Distribution
正态分布 1.性质 2.置信区间,区间内和区间外概率 3.计算标准正态分布Z转换
Properties
X~N(μ , σ²)

Symmetrical distribution: skewness=0; kurtosis=3; excess kurtosis=0
A linear combination of random variables these are in normally distribution is also normally distributed.
当X符合正态分布,aX+b依旧符合正态分布
As the values of x gets farther from the mean, the probability density get smaller and smaller but are always positive.
X取值范围为正无穷和负无穷
The confidence intervals
置信区间,以均值为中心的区间为置信区间,研究的是区间和概率一一对应的关系,分为在区间内的置信度和区间外的显著性水平 
K和置信区间(概率)的关系

Standard normal distribution
标准正态分布,即均值m=0,方差=1,N(0,1)或称Z的正态分布 我们可以人为创造出一个标准正太分布(即对X进行标准化) 1.即对X整体进行线性调整,得出调整后的数字和对应的概率 2.查表 3.负数转化  
Application
  
Application
  转化成标准正态分布
Univariate distributions(multivariate distribution)
单元(多元)分布
Application
 n(n – 1)/2 distinct correlations
Shortfall risk
短缺风险,实际回报率小于要求最低回报率风险的概率衡量,计算式可以写成P(Rp<Rl)=1-F(SFR),SFR不是风险,P才是风险,所以SFR越大越好  SFR越大表示出现上述的可能性越小,最大化SFR相当于最小化短缺风险
Safety first ratio
罗伊第一安全比例,可以类比夏普比例,只是把无风险收益率Rf替换成要求回报率Rl,同时夏普比例为组合收益率(后视),SFR中的为期望收益率(前置) 罗伊第一安全定律的本质还是求几倍的标注差,即负方向偏离的几倍的标准差之后仍然满足盈利,所以偏离的越多,说明越极端的情况下仍然可以满足最低收益率,所以是越大越好,而用正态分布求的是短缺风险的概率则是对应的越小越好
Lognormal Distribution
对数正态分布,即LnX符合正态分布,X则满足对数正态分布,其中X必须大于0,通常描述资产的价格,通常利息R符合正态分布,R和P之间又有对数关系,因此价格P满足对数正态分布 
Application

Application
  计算两个价格之间的Continuously compounded rate
Several Other Distributions
主要使用在估计和假设检验中
The Chi-Square (X^2)Distribution
卡方分布,对K个独立标准正态分布取平方后求和 1.非对称 2.用在假设检验,针对正参数 3.描述自由度(K),K越大形状越趋向于正态分布 
Student's T-distribution
T分布,在卡方分布(U)的基础上,结合标准正态分布Z和自由度K得出,从图像上来说像对标准正态分布的压缩 1.图像对称 2.峰度低于正态分布,尾巴肥于正态分布,峰度k>3(这里的峰度不是由高峰决定,而是由肥尾决定,因为T分布的尾巴分布比Z分布要肥) 3.自由度K越小,更矮峰,尾巴越肥(K是不是更大?);自由度K越大,更尖峰,更瘦尾,趋向于正态分布 可以用K越小越矮胖来形容 
Application of T-distribution
当标准差已知时,k和Z分布相关;但当标准差未知时,引入t分布,z,t本身都有相应的表格可以查询,其实际即对应标准正态分布上的X轴坐标 判断规则根据n是否大于30;是否正态分布;是否知道方差 1.对称无偏 2.自由度n-1 3.和正态分布比较之下,低峰肥尾,原因是t方差大于N的方差 4.样本越大,越趋近于正态分布  
Application

The F-Distribution
F分布,相当于两个卡方分布(U)和各自自由度K的关系 1.不对称,X大于0 2.K1和K2越来越大,越趋向于正态分布 
4. Monte Carlo simulation
蒙托卡罗模拟(模拟是输入分布到输出分布的过程,比如通过输入利率的概率分布导出价格的概率分布),通过数据模型的建立来预测未来,注意这是个纯统计的过程,结果是纯统计结果 例如:预测第10天的股价 1.通过观察1-9天股价的每天变化R符合正态分布(观察得到的假设) 2.生成随机数10个符合正态分布,得到第十天的价格 3.重复第二个过程无数次,观察价格的区间分布  
Application

R5 Sampling and Estimation
推断型统计学(抽样,估计)
1. Sampling methods

Probability Methods
概率抽样,前提条件抽样结果为等概率 
Simple Random Sampling
简单随机抽样,随便抽
Stratified Random Sampling
分层抽样,比如先划分男女,在按照男女占总体比例抽样
Systematic Sampling
系统抽样,比如每三人位一组,选择第一个人,(个人理解,和分层抽样比,选择的标准有一定随机性而不是主观定义)
Cluster Sampling
分组抽样,比如以家庭作为单位来进行抽样(首先要对样本聚类)
Non-Probability Methods
非概率抽样,抽样结果不等概率
Convenience Sampling
便利抽样,怎么方便怎么来,例如商店内部做用户调研,实际使用用户和购买用户可能不重合
Judgment Sampling
判断抽样,比如审计对特定项目进行抽样或者老师选题考试
Application
  C为什么是错误的?
Sampling error
抽样误差,样本均值(变量)-整体均值(常数),取样时希望样本误差(绝对值)越小越好
2.Central Limit Theory
中心极限定理,针对样本均值,只要样本容量足够大(大于等于30个),总体的均值、方差存在,样本均值(不是样本)满足正态分布,且其均值和标准差可以计算,样本均值等于总体均值  
Standard error
样本误,即X拔的标准差,要和样本标准差区别开,一个是样本平均值的标准差,一个是样本的标准差 已知总体方差即使用总体方差,未知总体方差则使用样本方差替代(注意这里针对的是样本均值,不是整体均值) 
3.Properties of Estimators
估计量的性质 The desirable properties of an estimator良好估计量的性质如下: 
Unbiasedness
无偏性,样本均值的均值等于总体均值(X拔的期望值等于m),比如使用定位软件N次定位取平均值如果是我们真正的目的地即无偏,反之则有偏 
Efficiency
有效性,方差越小越有效,波动性更小意味更准,比如定位软件在定位无偏性的情况下,每次离目的地距离越远意味着方差越大,有效性越差 
Consistency
一致性,趋势越来越准确,随着个数N的增加,准确定越来越高,例如中心极限定理中方差的计算和样本量呈反比,样本量越大,方差越小,结果越精确 
Application

4. Point & confidence interval estimate
点估计与区间估计 点估计用样本平均值估算总体平均值;区间估计用样本平均值+置信度*标准误来估计一定概率下平均值的区间 
Point estimate
点估计(如前述用样本均值推测总体均值m)
Confidence interval estimate
置信区间估计,(置信)区间估计,例如研究学生每个月消费的样本均值X推测总体平均值m是点估计,那么研究通过X拔所在的区间的概率(比如X拔落在一段区间的概率是多少)进而研究出m所在区间的概率,就是区间估计(又因为中心极限定理X拔的分布符合正态分布,所以可以使用标准正态分布的结论作为条件估算) (这里完成了样本均值和整体均值的转换) 其中置信度即落在区间内的概率(比如1.96对应的95%),alpha则是1-95%=5%(显著性水平,即失误概率),Reliability factor(RF)为1.96 应用中,希望区间能越小越好 1.通过样本量的增加,可以在置信度不变的情况下(Reliability factor不变),缩小范围,增加准确性,但是成本会增加 2.RF(Reliability factor)降低,因此置信度也要下降,显著性水平也要上升  
Application
 实际区间估计时,使用样本方差替代整体方差(样本方差更容易获得)
Determining Statistics for Confidence Intervals
1.小样本下,总体方差知晓使用Z分布(标准正态分布),总体方差未知使用T分布(其实就是RF的取值) 2.大样本下近似正态分布,即使不知道方差,也可以使用Z分布替代T分布 3.非正态小样本没办法估计  其中Zα/2的意思是标准正态分布累计概率函数的取值 
Application

5. Resampling
重复抽样,传统抽样估计步骤如下,目的在于获得m在一定概率下的范围,但是不能得到中位数,众数等,重复抽样的目的在于研究中位数,众数,峰度等不同维度的数据,核心方法在于重复取样(传统抽样只取一次样本量或者X拔,样本标准差S,样本数n)  重复抽样中 1.Bootstrapping需要多次抽样,Jackknife抽样数取决于样本中数的个数 2.Jackknife样本差异性小,Bootstrapping样本差异性大 
Bootstrapping
自举法,可以不使用Z分布或者T分布,该方法可以针对n小于30的样本使用  1.总体中抽取样本 2.对样本进行重复抽样(可放回抽样) 3.形成B个子样本(抽取B次) 4.看样本中例如mode的经验分布(确定RF),样本标准差(SE),平均数 5.计算获得mode的区间范围  
Jackknife
刀切法,即从总体中抽样,再从样本每次删去其中一个数形成子样本(n-1个数),抽取n次 1.减少偏差 2.可以获得样本标准差,置信区间 
6. Biases
偏见
Data snooping bias/Data-mining bias
偶然因素当成必然因素,集中的使用一个源头的数据过度解析,缺点是样本外数据拟合度差,比如100只股票中尾号为7的一定涨
Sample selection bias
样本选择偏误,例如之前的Non-Probability Methods
Survivorship bias
幸存者偏差,比如只选择业绩好的基金分析,但是没有考虑业绩亏损的(破产了就看不到了)
Self-selection bias
自主选择偏差,按照个人意愿只选择好的,不选择差的
Implicit selection bias
隐形偏差,隐含了一些门槛在抽样的选择中
Backfill bias
回填偏差,比如沪深300新加入公司之后会进行追溯调整
Look-ahead bias
前视性偏差,用了未公开数据建模
Application

Time-period bias
时间偏差,某个特定时间得出结论,比如在金融危机的两年得出收益率使用在各个年份
R6 Hypothesis Testing
假设检验,实质上是反证法,演绎法(样本)和归纳法(总体)的验证 
1. Critical value method
关键值法
Test of mean
以验证月收入9000为例,允许5%错误,alpha=5%(因为抽样值X拔为8400,所以其实目的在于推翻m=9000的假设)  
Step 1: State the hypothesis
列出假设,承认假设,即总体(不是样本)平均工资=9000(H0:m=9000,Ha≠9000) 其中H0=9000,所以为双尾 
Null hypothesis
原假设,1、希望否定的假设 2、假设为总体而不是样本,例如H0:m=9000,等号一般放在原假设中
Application
 原假设为希望推翻的假设,assess Alternative hypothesis(希望看到的事情),推翻Null hypothesis(不希望看到的事情) 
Alternative hypothesis
备择假设,希望得到的论断,例如Ha≠9000 As stated in the text, we often set up the “hoped for” or “suspected” condition as the alternative hypothesis.
Step 2: Test statistic
检验统计量 思路1,利用之前的“Confidence interval estimate”,测试出总体平均工资m在95%的概率上应该落在8388-8412之间,不符合H0=9000(其中使用到计算m的公式),即通过预测概率获得Reliability factor(RF),最终计算得到m所在区间,验证是否落在区间中 思路2,即由于X拔符合正态分布,利用假设的m测试(X拔-m)/标准误,测试获得具体是几个标准误,即Reliability factor(RF),和实际概率对应的RF做比较,比如Ha=9000和实际的取样偏差了100个标准误   思路1  思路2 
Step 3: Significance Level
确定显著性水平,即允许误差值,例如本次α=5%,对应的1.96即关键值Critical value,同Reliability factor(RF),可以理解为几个标准误 
Critical value
关键值,由显著性水平alpha决定,用他来和实际的检验统计量通过图来对比 
Step 4: Decision rule
决策法则,落入Reject region拒绝原假设,如案例中则落在5%的区间,即拒绝域中,则拒绝原假设,实际则是Critical value<-1.96或者Critical value>1.96则落入拒绝域 
Reject region
拒绝域,具体确认时需要确定单尾还是双尾
Step 5: Draw a conclusion
得出结论,由于Test statistic=-100,落入拒绝域(Critical value<-1.96或者Critical value>1.96),所以m≠9000(95%情况下) 如果落在置信区间内,最终结论不是接受原假设,而是不能拒绝原假设(希望论证全世界的天鹅是白色的,找到100只天鹅都是白色的,只能证明不排除全世界天鹅是白色的,但是不能证明全世界的天鹅是白色的) 
Application1
   第二步的公式计算,难点在于第三步,t分布+双尾查表+自由度(n-1)
Application2
  第三步需要单尾查表 第四步面对CV,需要看Ha(备择假设)的符号,符合符合则拒绝(难点)
Application3
 原假设一般包含等号
Significance test of correlation
相关系数显著性检验(不是相关系数检验),只要两组数据相关性不等于0即代表显著性相关(而相关系数检验指的是检验具体是不是某个值,比如0.7),所以其原假设是相关系数等于0不显著,备择假设是不等于0,相关性显著 1.其中将均值的关键值(样本均值和假设的整体均值偏差几个单位的标准误)进行了替换(主要在分母层面,分子层面还是相关系数r-0) 2.T分布,双尾 3.自由度n-2(相关系数需要两组变量) 
Application
 
Application2

Test of independence
独立性测验(对比相关系数只是线性关系),以投资规模和投资类型两者关系为例使用卡方检验,原假设为两者独立 1.m为联列表中的行*列,即所有格子数 2.Oij为i行j列的具体数字 3.Eij为i行j列的期望值,期望值的计算方式为该行数字总和*该列数字总和/总数(独立的情况下) 所以Oji和Eij越接近(差值小)意味着数据的独立性越大,相反独立性越小 4.确定显著性水平查询卡方分布表确定关键值(单尾,和相关系数不同,卡方值本身会大于等于0,右侧超过关键值可以拒绝,左侧则不可以拒绝原假设) 
Application

Other Hypothesis Tests
Mean hypothesis testing
除了Z和T分布之外,均值检验还包含 1.两组独立数据,均值是否相等?假设方差相同(第三行),其中Sp^2为Pool variance(相当于加群平均的样本方差,虽然总体方差假设一样,但是样本方差不同),t分布,自由度n1+n2-2 2.两组独立数据,均值是否相等?假设方差不同(第四行),t分布,自由度复杂 3.两组不独立数据,均值是否相等(成对数检验) Paired comparisons test  
Application

Variance hypothesis testing
方差检验 一组数据方差是否为某个值的检验(卡方分布) 两组数据方差是否相同的检验(F分布) 
Application1
 
Application2
 由于F的关键值默认是大于1的,所以在查分布表时查询双尾的右侧,不用考虑左侧)
Application3

2. P-value method
P值法,P值本身为原假设可以被拒绝的最小的显著性水平,相当于Alpha从原来拒绝一直减少到不能拒绝即为P值(图像上看,相当于边界不断外推,直到把样本所在的位置包含在内),所以alpha>P值,拒绝原假设,反之不能拒绝原假设,P值越小越容易拒绝原假设(alpha很容易就大于P值) P值一般在题目中给定,试错法给出 
Application

3. Type I and type II errors
一类错误与二类错误 H0:嫌疑人无罪(通常法院按照无罪推定原则),Ha:嫌疑人有罪 一类错误:拒真,原假设正确(条件)但是拒绝了原假设(条件概率),即显著性水平(比如5%的显著性水平,犯错的概率为5%),例如嫌疑人本身是好人,但是拒绝无罪,抓错好人(一类错误其实质就是alpha,显著性水平),可以理解为执法过严 置信度:原假设正确(条件),没有拒绝原假设,例如嫌疑人本身是好人,不拒绝无罪 二类错误:取伪,原假设错误(条件)但是没有拒绝原假设(条件概率),1-Power of a test,例如嫌疑人本身是坏人,但是不拒绝无罪,放走坏人,可以理解为执法过宽 Power of a test :原假设错误(条件)但是拒绝了原假设(条件概率),例如嫌疑犯本身是坏人,拒绝无罪 1.样本量不变,无法同时降低一类错误(宁可错杀一千也绝不放过一个)和二类错误(绝不可以冤枉一个好人),两个概率此消彼长 2.增加样本量可以同时降低两类错误 
Application
 
4. Parameter tests and non-parameter tests
参数与非参数检验 
Parametric tests
参数检验,比如总体的均值,差值,偏度,峰度等符合特定的分布
Nonparametric tests
非参数检验,比如分布未知,如样本值小、异常值,分类数据、是否独立等,有关T分布,卡方分布,F分布都属于parametric tests,根据分布决定,非参数检验则不是根据分布决定 1.总体非正态分布的小样本 2.数据只能排序而不能加减 3.检验对象不是平均方差等参数,比如计算正负数的数量
R7 Introduction to Linear Regression
1. Basics of simple linear regression
Linear regression
回归分析,即是在坐标系上找到每个X对应的Y,将拟合的比较好的线画出,因此将X和Y的线性关系用线性直线描述,这个过程就是回归分析(“Portfolio”章节中的“Beta”涉及到回归分析) 相比用相关系数去描述两者的关系,回归分析不但直观,且可以预测 
The dependent variable, Y
The independent variable, X
自变量
Dummy variable (indicator variable)
虚拟变量,Xi如满足某条件为1,不满足为0,此时为虚拟变量, 1.如果多个条件,可以通过X项的增加来解决,但是每个X项只有1或者0两种取值 2.如果研究时分出N种情况,只需要N-1个亚变量,比如说三种情况(001,100,010,只需要前两个条件就能清楚第三个是1还是0) 3.截距b0的意义在于当X=0时Y的取值 
Application
indicator variable
Slope coefficient,b1
斜率
Intercept term, b0
截距
The error term, εi
错误项(残差项),回归曲线和真实值的差值
Assumptions of the Linear Regression
回归模型的假设 1.在b0和b1的条件下X和Y线性相关(具体可参考当X=1时,方程式为线性表达式,假设满足) 2.自变量X和残差项ε不能有关系(可以理解用X和ε来解释Y,ε作为X的补充,b1和b0都是常数不参与解释,因此如果X和ε相关,单纯用X即可以描述Y,就不需要额外的ε) 3.残差项ε的期望值为0,根据ε的定义,其最理想的状态应该均匀的分布在拟合曲线的周围 4.同方差性,即残差项的方差是连续的,而不是异方差性(参考图示) 5.残差项不能有相关性,加入残差项彼此有关系,呈现出如周期性,那本身就可以用周期性变化替代线性回归,而不再适用于线性回归 6.残差项符合正态分布  
2. Estimate
Point estimate
点估计,目的在于使用样本预测总体(确定其b0和b1),要求满足无偏性,有效性,一致性 
Ordinary least squares (OLS)
最小二乘法,用于预测最优的回归拟合直线,具体指将所有的残差项平方求和,得到的最小值时的b1和b0即为理想的回归曲线 b1(斜率)=X和Y的协方差/X方差(参考Portfolio章节中“Beta”的计算方式) b0(截距)=Y的均值-b1*X的均值(即Y=aX+b求截距) 斜率的意义即X变动1单位,Y变动b1单位,也可以理解为敏感度 截距的意义即表示X=0时Y的值 
Application

Confidence interval estimate
置信区间估计 1.斜率在点估计的基础上加入Reliability factor(RF)和标准误(标准误题目中给出) 2.T分布,自由度n-2(两组变量) 3.拟合度越好,标准误越小,区间更窄 4.可以应用于假设检验(使用类双尾的假设检验) 
3. Hypothesis testing

Test of regression coefficients
回归系数的假设检验
By Critical value method
关键值法求斜率 1.其中检验统计量为(样本斜率-目标斜率)/斜率系数标准误,很像总体均值检验 2.假设的斜率等于0,此时为Significance test 
Application

Application2
 测试statistics时,分母直接使用Standard Error,而不用考虑项数
By P-value method
用P值法来验证斜率,原假设一定为斜率为0(significant test),如果拒绝原假设,则结论相当于显著不等于0 
Measure of model fitness
F-test
F检验,检验模型整体是否失效(这里的F检验和“The F-Distribution”描述相同,只是公式进行了变形),假设有多个自变量,有各自的斜率b,此时原假设H0为所有的斜率全部为0,相当于自变量和应变量无显著相关,备择假设Ha即至少有一个不等于0,当拒绝原假设即代表模型显著 1.其中公式中MSR和MSE需要查表得到,单元时k=1,计算的F统计量越大越容易拒绝原假设(样本的结果偏离的越厉害) 3.由于F分布的特性,得到“类似单尾”的结论查表得到关键值 
Analysis of variance (ANOVA) table
方差分析表,总体的方差由回归项方差(如果以此为主,更优)和残差项方差(以此为主比较差)组成,因为回归的目的即希望主要由回归值来解释X和Y的关系(MSS描述的是原假设Y(水平直线)上点、样本拟合的Y^(倾斜直线)上点、实际Y的点,三者相差结合各自自由度的方差关系) Coefficient of determination (R²) =RSS(回归相关项)/SST(总体相关),结果越大越表示主要受回归影响,拟合度越好,it shows that n% of the variability in Y is explained by changes X. Standard error of estimate(SEE),即残差的标准差,越低越好 这里的Total variation(SST)和方差有区别,前者加总不平均,后者需要平均 
Multiple R
Multiple R 表示真实值和预测值的相关程度(相关系数的绝对值),如果斜率大于0,正相关,斜率小于0,负相关,只能用于单元回归(R^2可以用于多元回归) 
Application
 标准误由“检验统计量(t-statistic)=(样本斜率-目标斜率)/斜率系数标准误”获得
4. Estimate of Y
Y的估计相当于是模型的最终的应用,同样设计到点估计和区间估计 1.其中残差项的期望值为0,所以省去 2.Sf一般题目中会给出 3.Y估计的误差来源于两点,残差项和b1/b0(因为只取了一组样本数据)
Application
 Y的期望值为+-R.F(通过边界给出,计算的边界,不是显著性水平给出的)*标准误
5. Forms of Simple Linear Regression
线性回归形式,自变量和应变量引入对数,引入对数的原因在于实际的收益率会按照复利增加,有指数形式,通过对指数形式的变形得到对数的对应形式 
Application
 为什么使用log函数?
Statistical Concepts and Market Returns(old version)
Descriptive statistics描述型统计学(特征) 描述样本数据的角度,如均值,标准差(描述性统计)和假设检验(推断性统计,样本推导总体)
Measurement Scales
测量维度
Types of measurement scales
Nominal scales
Ordinal scales (>, <)
Interval scales (>, <, +, -)
Ratio scales (>, <, +, -, *, /)
Population and Sample

Frequency distribution
Interval
Absolute Frequency
Relative Frequency
Cumulative Absolute Frequency
Cumulative Relative Frequency
Histogram
直方图
Polygon
折线图
Measures of Central Tendency
中心趋势
Mean

Mode
众数
Median
中位数
The Arithmetic Mean
算数平均
评价next year's returns
未来收益
The Weighted Mean
加权平均
应用Portfolio的权重
The Geometric Mean
几何平均
应用各期的收益率的平均值计算

复利思想,评价past performance
The Harmonic Mean
调和平均
应用计算平均成本价格

A>=G>=H
可以按照字母表顺序记忆,当所有数相同,等号成立
Absolute Dispersion
离散程度,描述分布的范围是广泛还是集中的 
Range
极差,容易受极端值影响
MAD
Mean Absolute deviation平均绝对偏离,描述偏离均值距离的平均值 计算器无法公式计算,需要手动计算 
Variance
方差,方差可以用来描述风险(不确定性),对于均值的偏离程度描述,越偏离表示不确定(风险)越高,反之亦然
总体方差

样本方差
分母用n-1 用无偏角度,用n-1更接近于总体方差;从自由度的角度,当了解均值和总个数时,一组数可以自由取的个数为n-1个 
Standard deviation
由于方差的是在原来单位上面进行了平方,为了和原来单位相同引入了标准差,即在方差基础上开根号
总体标准差
样本标准差
Chebyshev's Inequality, CV and SR
Chebyshev's Inequality
切比雪夫不等式,描述的是个体分布在均值周围的概率情况,相当于区间和概率的关系。  
Coefficient of variation
变异系数,标准差和均值的比值,是一个相对均值mean的离散程度(Scale-free,是一个比值,没有单位) 每单位的均值对应的标准差,越大表示不确定(risk)越大 
Sharpe ratio
夏普比率,主要衡量portfolio的投资表现和风险的对应关系,越高越能表示单位风险(标准差)所获得的超额收益越高 
Skewness &Kurtosis
Skewness
偏度 
Tpye
Symmetrical
无偏,S=0
Positive (right) skew
极端值出现在右边,右尾长,S>0,正偏
Negative (left) skew
极端值出现在左边
Mode/Median/Mean关系
可以理解在对称的情况下加入极端值对于三个参考值的影响程度 
Skewness计算power=3
Return
从投资收益的角度,右偏的收益率分布更具有吸引力
Kurtosis
 
Type
Mesokurtic
常峰态,K=0
Leptokurtic
高峰(尖峰)K>3
Platykurtic
低峰(矮峰)K<3
Kurtosis计算power=4
Excess kurtosis
Sample kurtosis – 3
Leptokurtic——Fat tail
在方差相同的情况下,高峰对应肥尾,尾部出现极值可能性更高,反之亦然
计算器使用
计算平均值和方差

Floating Topic