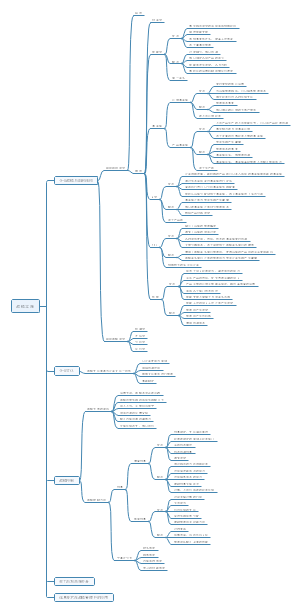
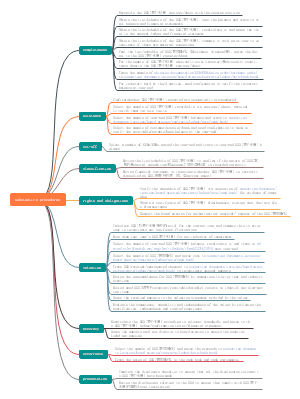
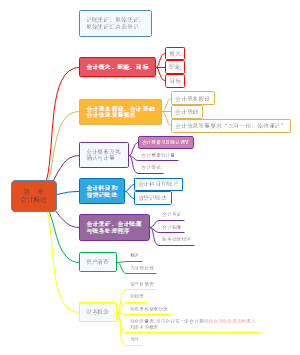
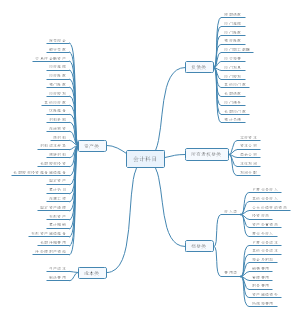
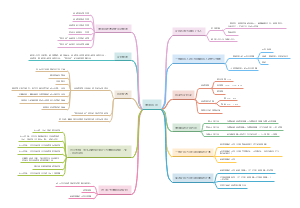
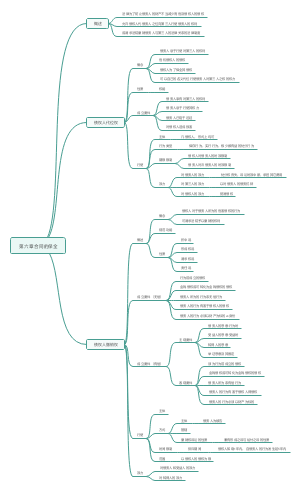
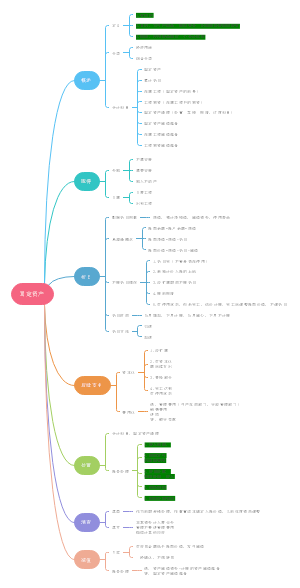
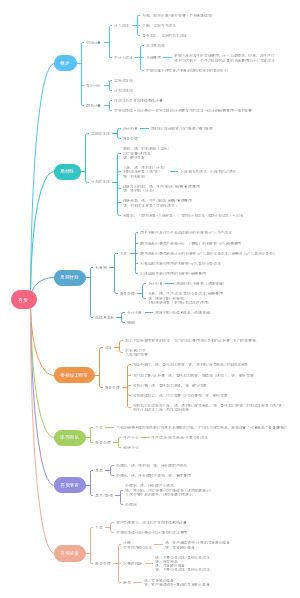
导图社区 经济师 经济基础 第23-27章: 统计
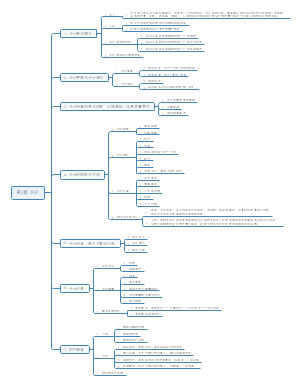
经济师 经济基础 第23-27章: 统计
这是一篇关于经济师 经济基础 第23-27章: 统计的思维导图,介绍详细,描述全面,希望对感兴趣的小伙伴有所帮助!
提示: 本内容由社区用户上传并分享。平台不对内容的真实性、合法性、知识产权归属及是否侵害第三方权利进行事前审核或保证。本内容可能包含受版权保护的图片、字体或其他第三方素材,使用前请自行确认授权范围。
他的近期作品
查看更多>>
- 知识产权第11章:商业秘密
2024年最新教材,商业秘密是指不为公众所知悉、具有商业价值并经权利人采取相应保密措施的技术信息和经营信息等商业信息。
- 知识产权第10章:地理标志
2024年最新教材,地理标志是指标示某商品来源于某地区,该商品的特定质量、信誉或者其他特征,主要由该地区的自然因素或者人文因素所决定的标志。它是由“原产地+商品名称”组成,是一种独立的知识产权类型,在属性上具有地方性特色。
- 知识产权第7章: 商标权保护
2024年最新知识产权实务,商标权保护是知识产权法律体系中的重要组成部分,旨在保护商标注册人对其注册商标的独占使用权,防止他人未经许可使用相同或近似商标,造成消费者混淆和市场秩序紊乱。
经济师 经济基础 第23-27章: 统计
社区模板帮助中心,点此进入>>
他的近期作品
查看更多>>
- 知识产权第11章:商业秘密
2024年最新教材,商业秘密是指不为公众所知悉、具有商业价值并经权利人采取相应保密措施的技术信息和经营信息等商业信息。
- 知识产权第10章:地理标志
2024年最新教材,地理标志是指标示某商品来源于某地区,该商品的特定质量、信誉或者其他特征,主要由该地区的自然因素或者人文因素所决定的标志。它是由“原产地+商品名称”组成,是一种独立的知识产权类型,在属性上具有地方性特色。
- 知识产权第7章: 商标权保护
2024年最新知识产权实务,商标权保护是知识产权法律体系中的重要组成部分,旨在保护商标注册人对其注册商标的独占使用权,防止他人未经许可使用相同或近似商标,造成消费者混淆和市场秩序紊乱。
- 相似推荐
- 大纲