导图社区 流行病学、统计学
这是一篇关于流行病学、统计学的思维导图,流行病学是研究特定人群中疾病、健康状况的分布及其决定因素,并研究防制疾病及促进健康的策略和措施的科学。
社区模板帮助中心,点此进入>>
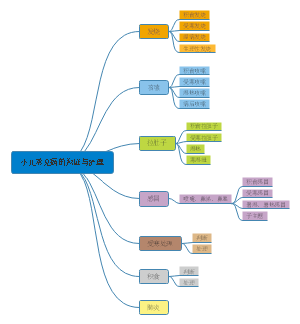
小儿常见病的辩证与护理
蛋白质
均衡饮食一周计划
消化系统常见病
耳鼻喉解剖与生理
糖尿病知识总结
细胞的基本功能
体格检查:一般检查
心裕济川传承谱
解热镇痛抗炎药
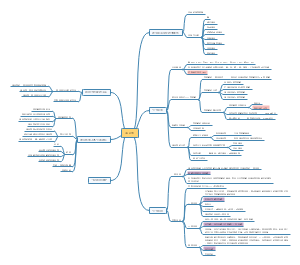
流、统
流行病学
发病率和罹患率都是描述最近新发病人数指标, 只是发病率表示的时间较长,罹患率较短
揭示暴露和疾病因果关系过程中最基础的步骤是
描述暴露和疾病的三间分布
偏倚
研究的系统误差部分
易感性偏倚
健康工人效应
分选择偏倚、信息偏倚、混杂偏倚三种
筛检
灵敏度
真阳性率
特异度
真阴性率
正确指数
灵敏度+特异度-1
续发率
最短潜伏期至最长潜伏期间易感接触者中发病的人数占所有易感接触者总数的比率
接触者隔离时间
最后接触之日开始,一个最长潜伏期止
描述性研究
疾病监测
疾病的分布
频率测量指标:K:百分之;千分之;万分之;十万分之皆可
发病频率 测量指标
发病率(K)
一定时间内,一定范围人群某病新发生病例的出现频率
罹患率(K)
某一较短时间范围内的发病率
续发率(100%)
某些传染病最短潜伏期到最长潜伏期之间,接触人员中发病者所占比例
患病频率 测量指标
患病率(现患率)(K)
某特定时间内,患某病人数(新旧都算)占总人数的比例
患病率=发病率*病程
感染率(100%)
受检者中感染人数所占比例
死亡生存频率
死亡率(K)
一定时间内,某人群死亡人数占该人群总数的比例
病死率(100%)
一定时间内,某病死亡人数占病人数的比例
生存率(100%)
接受某种治疗的病人中,N年后仍存活人数占治疗人数的比例
疾病流行强度
散发
和历年水平相当,病例间无时间地点上的明显联系
暴发
一个局部地区和集体中,短期内出现许多症状相同的病人
流行
某地区发病超过历年水平,且病例间有时空联系
大流行
涉及范围较广,跨越省、国、洲的流行
人群分布(人和)
年龄、性别、职业、种族及民族、婚姻、行为生活方式等
地域分布(地利)
行政划分或自然景观划分
时间分布(天时)
短期波动、周期波动、季节波动、长期变异
分类
现况研究、病例报告、病例系列分析、个案研究、历史资料分析、随访研究、生态学研究
现况研究
又叫横断面研究,包括普查及抽样调查,主要计算发病率,
生态学研究
又叫相关性研究,在发病率的水平上研究暴露与疾病间的关系,用于提供假设及检验干预效果
队列研究
基本特点
1、属于观察法;2、设立对照组;3、由因及果;4、能暴露因果联系
分为
前瞻性队列研究、历史性队列研究、双向性队列研究
研究人群
暴露人群
暴露于危险因素中的人群
对照人群
未暴露于危险因素中的人群
发病密度
病例数/人年数
人年数为所有观察组人年数的合计
率的计算
效应的估计
基本含义:Ie:暴露组的率;I0:对照组的率;It:全人群的率
相对危险度(RR)
Ie/I0
归因危险度(AR)
Ie-I0
归因危险度百分比(AR%)
(Ie-I0)/Ie
人群归因危险度(PAR)
(It-I0)/It
病例对照研究
病例对照不匹配
病例对照匹配
频数匹配
病例和对照不一定数量相等,但是各种人群占比相等,比如男女
个体匹配
病例与对照一对一或者一对多匹配,其中一对一又叫配对
资料分析
不匹配资料
比值比(OR)
(a/c)/(b/d)=ad/bc
卡方值()
(ad-bc)n/(m1*m0*n1*n0)
匹配资料
比值比(OR)
c/b
(b-c)/(b+c)
归因分值()
计算同归因危险度百分比
实验流行病学
临床实验、现场试验、社区试验
相对危险度降低(RRR)
(对照组事件发生率-实验组事件发生率)/对照组事件发生率
绝对危险度降低(ARR)
对照组事件发生率-实验组事件发生率
需要治疗人数(NNT)
1/ARR
表示防治1例不良事件发生需要用试验组方法干预多少人
保护率(PR)
公式同RRR
效果指数(IE)
对照组事件发生率/实验组事件发生率
抗体阳转率
抗体阳性人数/疫苗接种人数*100%
真实性
灵敏度(真阳性率)
a/c1*100%
假阴性率
c/c1*100%
特异度(真阴性率)
d/c2*100%
假阳性率
b/c2*100%
1-(假阴性率+假阳性率)
似然比
阳性似然比(+LR)
灵敏度/(1-特异度)
数值越大,表明阳性为患者的可能性越大
阴性似然比(-LR)
(1-灵敏度)/特异度
数值越小,表明阴性为非患者的可能性越大
可靠性
符合率
(a+d)/N*100%
预测值
阳性预测值
a/R1*100%
表明阳性患病的可能性
阴性预测值
d/R2*100%
表明阴性不患病的可能性
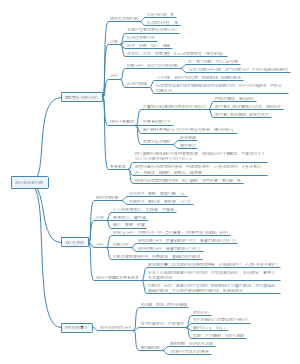
偏倚及其控制
选择偏倚、信息偏倚、混杂偏倚
因果
因果论证强度
流行病学试验研究>队列研究>病例对照研究>现况研究
实验研究>观察研究
有对照的>无对照的
个体的>群体的
统计学
单侧>1.96
2.5%
单侧>2.58
0.5%
标准误
标准误越大,离散程度越大
样本量越大,标准误越小
方差/根号n
卡方检验
多个样本率的比较
统计表
标题在表的上端
标准化死亡率
不受年龄影响,反映整个人群的死亡水平
泊松分布
由率和抽样次数决定
均数=标准差平方
统计表标题在上,统计图标题在下
统计描述
定量
分布类型
离散型、连续型
分布特征
集中趋势
平均数
算数平均数
对称分布
所有观察值的和除以N
几何平均数G
等比、对数正态
所有观察值得积开N次方
中位数M
偏态、不确定、离群值
离散趋势
标准差(S)
四分位数间距:Q=P75-P25
变异系数:CV
标准差/平均数*100%
用于不同类型数值变化程度大小的比较
统计图表
条图、箱式图
定性
相对数、构成比、率、相对比
标准化法
直接标准化
用率计算标准人口的预期治愈数,然后不同组拿预期治愈数进行比较
间接标准化
用第三组的率将前面两组的率标准化,再拿标准化后的率进行比较
动态数列
统计图表、直条图、构成图、线图
统计学的一些概念
总体与样本
总体为想要研究的范围内的所有对象,样本为从其中抽取的部分的集合
参数与统计量
参数为总体的分布特征,统计量为样本的分布特征
抽样
误差由大到小
整群抽样
单纯随机抽样
系统抽样
分层抽样
常用概率分布
二项分布
只有两种互相排斥的结果,进行了N次
设每一次出现预期的概率为π,则当nπ、n(1-π)均大于5时,二项分布趋于对称,集中位置位于nπ。
概率
P(X)=n!/(X!*(n-X)!)*
总体平均数
μ=nπ
总体标准差
σ=√(nπ(1-π))
单位时间、空间、人群罕见事件的发生概率
λ:总体平均数

总体均数和标准差
总体均数为λ;标准差为√λ
正态分布
均数为μ;在σ处出现拐点
t分布当自由度越小,曲线越平;自由度越大,越接近正态分布
概率曲线下的面积
μ±σ
68.27%
μ±1.64σ
90%
μ±1.96σ
95%
μ±2σ
95.44%
μ±2.58σ
99%
μ±3σ
99.74%
参数估计
多次抽样的样本均数的标准差(均数的标准误)
置信区间 在(1-a)下
双侧
即均数+_对应的1.96或者2.58与标准差的乘积
单侧
假设检验
P<a,即在a的标准下拒绝原假设(H0),认为备择假设(H1)有意义
P>=a,即在a的标准下不拒绝H0假设,即尚不能认为H1成立
样本推断总体
样本应为总体有代表性的一部分
α
不拒绝实际成立的H0的概率
t检验
条件
随机、正态、方差齐
单样本
t=(-μ0)/(s/√n)
配对样本
t=(d-μ0)/(sd/√n)
d为差的平均数
Sd为差的标准差
自由度(γ)=n-1
两独立样本
方差齐性检验
二项分布与poison 分布的z检验
二项
poison
方差分析
独立、随机、正态、方差齐
P129页
完全随机设计资料
P131页
随机区组设计资料
P132页
多个样本均数的两两比较
P134页
检验
取值
0-正无穷
独立
独立四格表
(ad-bc)n/((a+b)*(c+d)*(a+c)*(b+d))
R*C联表
154页
配对
配对四格表
=(b-c)/(b+c)
R*R联表
158页
应使用校正公式但未用
卡方值增大,P值减小
秩和检验
配对资料
以对配对资料差值的绝对值进行排序,负值排序后前面添加负号,0舍去不计,两者相同取平均值,将秩次正值与负值分别相加,求绝对值记做T(+)、T(-),样品数量减差值为0的数量的差记做n,用n查T临界值表(附表9),判断T是否在范围内,在则P>a,否则则<。
两独立
连续变量
两组数据放一起排序,全为正,数据相同秩次求平均。排出秩次两组分别求和,用两组样本数n1-n2绝对值及较小的样本数n查表,用较小的秩和与表中范围比较,表中各行表示不同a下的数值,在范围内的P>a。
有序分类变量
多独立样本
178页
相同秩次过多时校正U值
使U值增大、P值减小
两变量关联性分析
线性相关
ιxx:x的离均差平方和;ιyy:y的离均差平方和;ιxy:x和y的离均差积之和
ιxx:所有x值与x的平均值之差的平方和除以(n-1);ιyy:类同x的;ιxy:x和y分别与其各自平均数的差,在用差求积,积求和后除以(n-1)
相关系数(r)
r绝对值越接近1,说明相关性越好
r=ιxy/√(ιxx*ιyy)
当r>0时
b>0
秩相关
对不服从正态分布的资料可以采用秩相关,对X、Y分别求取秩次,。。。。
简单线性回归
I类回归
散点图具有线性特征
II类回归
数据中的X和Y都是随机变化的,且符合双变量正态分布。
y=a+bx
b=ιxy/ιxx
求出b后利用(x均数,y均数这一点求出a)
寿命表
371页
假设检验错误
一类错误
无病判断有病
拒绝实际上成立的H0
二类错误
单侧数据用了双侧标准,增加了二类错误
有病的判断成没病
不拒绝实际上不成立的H0
变异系数
标准差/平均数
根据以往发病情况预测将来一段时间的发病情况