导图社区 医学统计学思维导图
医学统计学思维导图
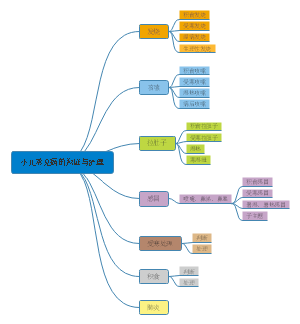
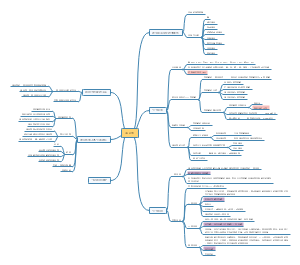
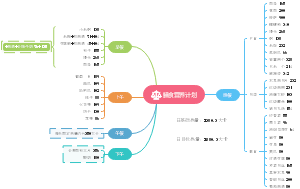
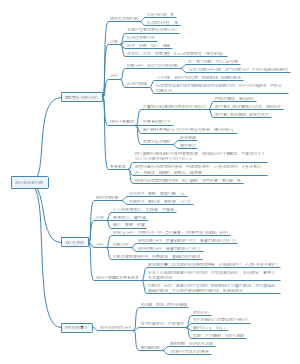
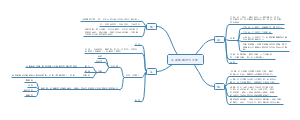
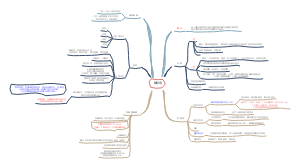
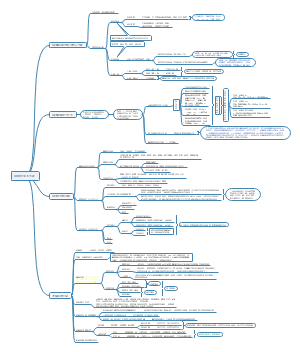
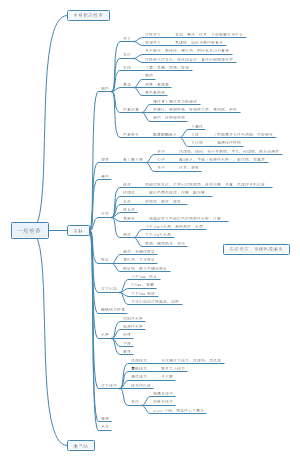
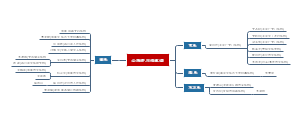
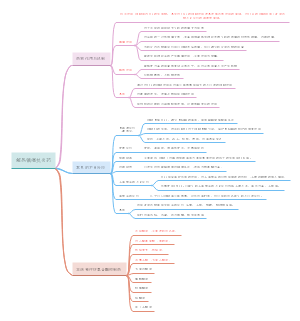
详细概述了医学统计学的主要内容和关键步骤。在“统计描述”部分详细讨论了统计描述的表达方式,包括绪论、统计推断、同质与变异、变量与数据类型、基本概念、总体和样本、误差、概率与运算法则、定量数据以及特定数据类型的统计描述等。在“统计推断”部分,介绍了正态曲线和正态分布的特征,布局清晰,内容丰富,涵盖了医学统计学的主要知识点和流程,对于理解和应用医学统计学具有重要的指导意义。
编辑于2024-06-08 14:46:04- 统计学
- 相似推荐
- 大纲
导图社区 医学统计学思维导图
详细概述了医学统计学的主要内容和关键步骤。在“统计描述”部分详细讨论了统计描述的表达方式,包括绪论、统计推断、同质与变异、变量与数据类型、基本概念、总体和样本、误差、概率与运算法则、定量数据以及特定数据类型的统计描述等。在“统计推断”部分,介绍了正态曲线和正态分布的特征,布局清晰,内容丰富,涵盖了医学统计学的主要知识点和流程,对于理解和应用医学统计学具有重要的指导意义。
编辑于2024-06-08 14:46:04