导图社区 多层次模型
多层次模型 by 道格拉斯·A.卢克,读书笔记。主要内容有:多层次模型的目的、基本二层模型、建立与测量多层次模型——以烟草工业为例。
感知觉障碍:感觉障碍 disorder of sensation:感觉减退 hypoesthesia、内感性不适/体感异常 senestopathia。
社区模板帮助中心,点此进入>>
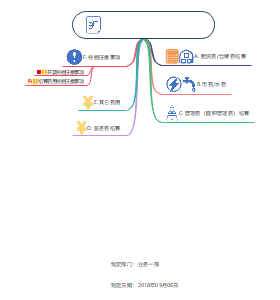
费用结算流程
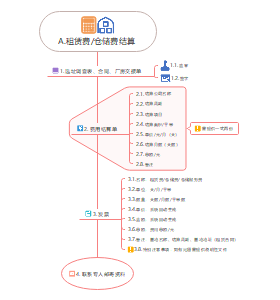
租赁费仓储费结算
E其它费用
F1开票注意事项
F2结算费用特别注意事项
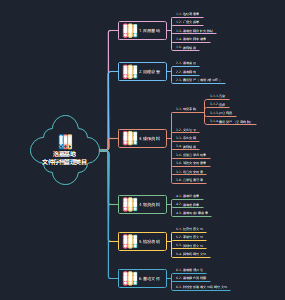
洛嘉基地文件存档管理类目
CFA一级Ethics-standard思维导图
货币政策对黄金价格的传导机制
CPA战略风险管理、战略实施
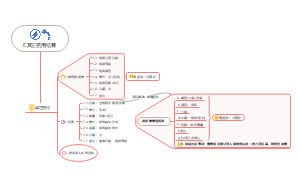
云报税(个税)
多层次模型
目的
基于一系列非同一层次的自变量,对因变量的值进行估计
基本二层模型
核心观点
将截距和斜率作为第二层自变量的结果
二层结构
第一层
个体观测指标(因变量)=组平均因变量水平+组内斜率*个体自变量+随机效应
第二层
组平均因变量水平=总体因变量均值+组均斜率*组自变量+未被模型化的误差项
组内斜率=组均斜率+组内斜率斜率*组自变量
第二层代入第一层
含固定效应部分&随机效应部分
混合模型/混合效应模型
斜率截距并不直接被估计,二十通过第二层参数γ间接获得
随机效应依赖于各个层级单位
最终模型的决定
一、 现有几层数据?期中有几层将被模型化?
二、 各层次分别有多少自变量需要加以考虑?
三、 将一层的斜率and/or截距作为二层特征的结果?
四、 模型的那部分需引入随机效应?
建立与测量多层次模型 ——以烟草工业为例
确立1997年至2000年间国会成员对烟草工业相关法案的投票行为的重要影响因素
分层
假设,国会议员获得的资金越多,越有可能支持烟草工业
各州烟草种植场的经济情况【1999年各州收获的烟草数量(英亩数)】
数据管理
各层信息录入同一数据文件
SAS,S-Plus
各层信息录入两个数据文件
HLM
STATA??
可直接整合成一个数据文件
多层次模型必要性的评估
实证方面
地图分布
散点图
各组内部线性拟合图
画图工具拟合
组间相关系数ICC
测量因变量的方差被组别(二层单位)所解释的部分
通过拟合零模型得出
高组间相关系数提示应使用多层次模型拟合有用的各州的特征
统计方面
数据的结构特性
单层次最小二乘法的重要假设之一:各项观察值(以及误差项)彼此独立; 数据出现嵌套结构,假设被违背
加大第一类错误的几率
数据的聚类本质
多层次模型放松独立性假设并允许相关误差结构的存在
理论方面
研究者使用的理论框架或建构的理论为多层次运作
从简单模型到复杂模型
解释性 or 验证性
参数估计/模型拟合/预测
典型方法:由下而上
第一层次自变量出发
第一层次被满足时,考虑潜在的第二层次变量
首先考虑仅将截距作为二层自变量结果
当有实证或理论证据时,再引入斜率也作为二层自变量结果
方差分量
非零——有未被模型化的差异存在
较大——提示可考虑加入更多自变量
较大如何判断
三个模型
模型估计
拟合方法选择
最大似然法
约束最大似然法
固定效应相同
约束法随机效应误差较小,二层单位较多时可忽略
最大似然法的理查统计量可用于比骄傲两个模型中的固定效应和随机效应
模型检验:假设检验
参数系数/标准误-->自由度(t):J-p-1
J:第二层单位的个数
p:第二层自变量的个数
其他
最大似然法wald检验,可被看作标准正态分布z值
模型拟合度检验——离差和判定系数
看模型与数据拟合得是否紧密,用于模型的比较
离差:对数据和模型间未被拟合部分的测量
似然估计量取自然对数并乘以-2
似然估计量:多层次回归的最大似然估计中被最小化的部分
离差越小,拟合程度越高(不取绝对值)
通常参数越多,拟合程度越高
自由度的计算
同时要求运用最少的参数来最大化地解释数据中的因变量变动
其他方式
赤池信息准则
贝叶斯信息准则
p:模型中参数的总量
N:样本量
越低拟合越好
可用于比较两个互不嵌套的模型
方差R^2
去除随机斜率再计算方差
第一层预测削减误差比例
第二层预测削减误差比例
相较零模型,预测力被提高了大约……
模型评估:模型诊断
检验模型的潜在假设是否成立
(1) 第一层组内误差相互独立并服从均值为0的正态分布
(2) 随机效应服从均值为0的正态分布,并且再组间相互独立
模型化过程中一二层的残差评估
盒形图
残差是否集中于0,方差是否在各组保持不变
标准化残差与拟合值间的散点图
需集中于0
残差变化在组间基本相同
残差的QQ图(分位比较图)
呈正态分布则直线
散点图矩阵
随机效应是否集中化
随机效应是否在组间独立
预测:后验均值
经典贝叶斯估计(β的计算)
第一层模型的截距、斜率在第二层单位间变化的具体情况
组信度越高,越倾向于用所有组的总体均值作为估计。
主要由组内第一层单位数目n决定-->样本大,信度高,偏向组内Y
用途
收缩估计用于检验或辨识研究者感兴趣的二层单位(截距,斜率s)
检验所有的经验贝叶斯预测方程来探索各组模型的差异
考察其对原始数据的拟合程度
经典贝叶斯估计散点图
中心化处理
多层次模型中,不同斜率