导图社区 健康医疗大数据
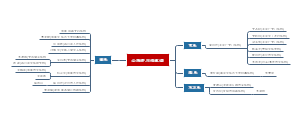
健康医疗大数据思维导图,如⽣物信息⼤数据指⼤数据背景下通过⽣物医学技术获取的有关细胞或⽣物体的核酸、蛋⽩质和代谢产物等数据的集合
社区模板帮助中心,点此进入>>
小儿常见病的辩证与护理
蛋白质
均衡饮食一周计划
消化系统常见病
耳鼻喉解剖与生理
糖尿病知识总结
细胞的基本功能
体格检查:一般检查
心裕济川传承谱
解热镇痛抗炎药
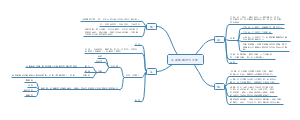
健康医疗大数据
第三章 生物信息大数据建模方法与应用
生物信息大数据概述
⽣物信息⼤数据的含义
1.指⼤数据背景下通过⽣物医学技术获取的有关细胞或⽣物体的核酸、蛋⽩质和代谢产物等数据的集合
2.既包括实验或测序所得的⼀次数据,也包括分析所得的⼆次数据
⽣物信息⼤数据的特征5V
Volume 量⼤、Variety 多样性、Value 价值性、Velocity ⾼速性、Varacity 真实性
⽣物信息⼤数据的类型
1.根据对象类型:可分为核酸⼤数据、蛋⽩质⼤数据、⽣物信号⼤数据、肿瘤⼤数据和模式⽣物⼤数据等
2.根据公开程度:可分为公开的⽣物⼤数据(NCBI的GEO、GeneBank)、半公开的⽣物信息⼤数据(STRING)、私密的⽣物信息⼤数据(公司或单位私有的⽣物信息⼤数据)
3.根据加⼯程度:⼀次性⽣物信息⼤数据(如序列读取存档⽂件SRA)、⼆次性⽣物信息⼤数据(如Oncomine等
⽣物信息数据库指的是在计算机等存储设备上合理存放且相互关联 的⽣物信息集合,是⾮常重要的⽣物信息资源。
生物信息大数据网址
核酸大数据
蛋⽩质⼤数据
是指通过⾼通量技术,获取并整合了⼤量蛋⽩质相关的数据,包括蛋⽩质序列数据、结构数据、功能数据、相互作⽤/关系数据、质谱数据等信息。
生物通路大数据
肿瘤大数据
生物信息大数据建模
Hub基因挖掘方法与应用
第四章
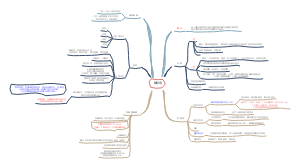
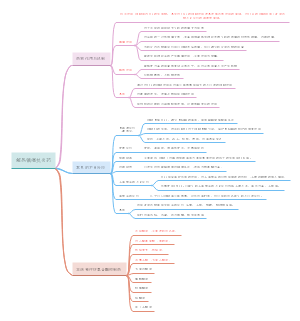
第五章医学⽂本与语⾳⼤数据
⾃然语⾔处理NLP概述
1.⾃然语⾔(natural language):⼈类说的语⾔,⼈类沟通的基本⽅法。⾃然进化⽽来,⾮⼈类设计的。 2.形式化语⾔(Formal language):⼈类为了特殊应⽤⽽设计的语⾔。如数学符号,化学分⼦式、编程语⾔
⾃然语⾔处理( Natural Language Processing, NLP)是计算机科学领域与⼈⼯智能领域中的⼀个重要⽅向。它研究能实现⼈与计算机之间⽤⾃然语⾔进⾏有效通信的各种理论和⽅法。
⾃然语⾔的语⾔学结果层次
词汇形态、词法、句法、语义、语⽤、语篇、
医学⽂本数据及⽂本挖掘
按结构化程度分类
结构化—逻辑上以表格或其它严格统⼀形式存储的⽂本
半结构化—结构与内容混在⼀起的⽂本,兼具格式性和可扩展性
⾮结构化—完全没有结构或只含有语义结构的⼀类⽂本,扩展性强,没有统⼀规则,需要机器学习⽅法才能处
医学⽂本数据的特点
数据多源复杂、 信息存在缺陷、多点时空掺杂、专业词汇繁多、逻辑关系特殊
⽂本挖掘的基本概念和原理
文本挖掘对象
中文文本
中⽂分词: 中⽂⽂本词与词之间没有空格,语⾔复杂,分词困难。需要分词算法
英文文本
英⽂分词:预处理包括词⼲提取stemming和词形还原lemmatization。
1.词⼲提取:抽取词语的词⼲或词根形式
2. 词形还原:把不同形态形式的词汇还原为⼀般形式
3.相同点:对词汇进⾏规范化从⽽找到词的原始形式
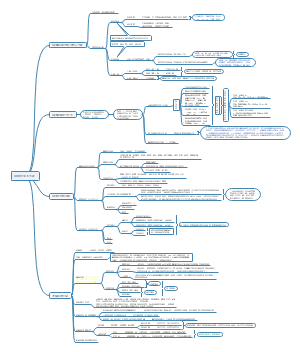
中⽂分词⽅法
中⽂分词: 对中⽂中的各个词进⾏分隔,且⼀般以语句为单位对各个词进⾏分离
有词典分词:也称为基于规则的分词,是指分词系统利⽤系统预先收集存储的词进⾏分词,这样能提⾼分词效率
⽅法分类
字符串扫描⽅向,分为正向匹配和逆向匹配
优先匹配的词⻓:最⼤匹配和最⼩匹配
常使⽤⽅法
正向最⼤匹配分词
反向最⼤匹配分词
⽆词典分词
利⽤相邻字的共同出现的频率作为分词标准,根据两个字相邻出现的频率体现词的可信程度来判别
统计分词模型
隐⻢可夫模型hidden Markov model HMM 最⼤熵模型 N-gram模型等
基于词⽹格的N-gram统计分词技术
词⽹格 word lattices 指描述⼀个需要被分词的语句和其所形成的候选词共同形成的路径的⽅法
候选词⽹格构造:利⽤词典匹配,列举输⼊句⼦所有可能的切分词语,并以词⽹格形式保存。
医学⽂本挖掘步骤
⽂本挖掘步骤
⽂本获取
⽂本预处理
⽂本表示
特征选择
分类器进⾏分类
⽂本聚类
医学语⾳数据
主题