导图社区 人教版六年级上册分数除法
人教版六年级上册分数除法
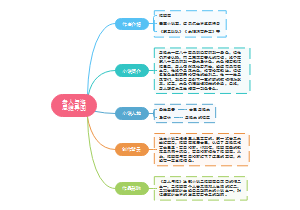
分数除法是分数乘法的逆行运算(逆运算)。分数除法的计算法则为:甲数除以乙数(0除外),等于甲数乘乙数的倒数。分数除法的结果能约分的要约分。
编辑于2022-09-30 09:27:32 新疆- 分数除法
- 相似推荐
- 大纲
导图社区 人教版六年级上册分数除法
分数除法是分数乘法的逆行运算(逆运算)。分数除法的计算法则为:甲数除以乙数(0除外),等于甲数乘乙数的倒数。分数除法的结果能约分的要约分。
编辑于2022-09-30 09:27:32 新疆