导图社区 统计推断复习
统计推断复习
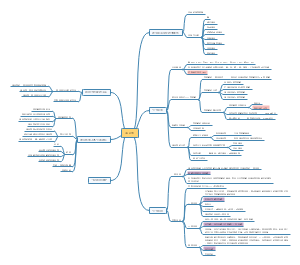
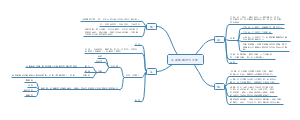
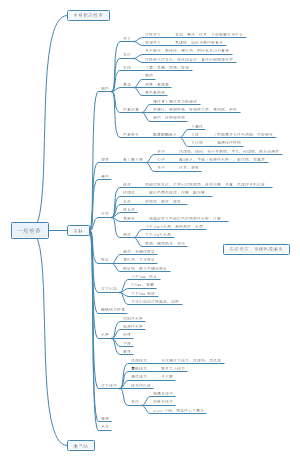
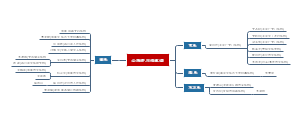
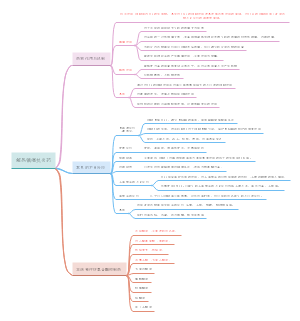
医学统计学推断部分复习总结,"统计推断的核心:从数据中挖掘真相!本文系统梳理统计推断要点,涵盖参数估计(可信区间计算、中心极限定理应用)、假设检验(z检验、两类错误控制)和方差分析(变异分解思想)重点解析:①置信区间与医学参考值范围的区别②标准差与标准误的异同③多重比较替代t检验的原因④不同设计类型的变异分解附统计描述技巧(频数表、直方图绘制)和资料类型处理(计量/计数/等级资料),助你掌握数据分析底层逻辑。
编辑于2025-09-25 09:10:05- 医学统计学
- 假设检验
- 参数估计
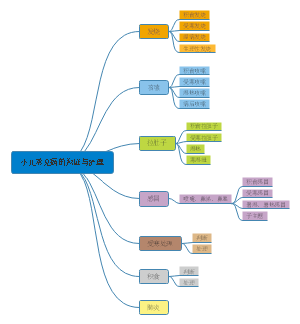
- 药理学中枢神经系统药物表格
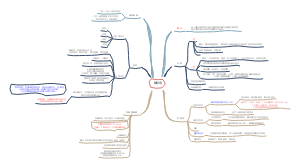
药理学中枢神经系统表格总结,【中枢神经系统药物全览】从镇痛消炎到精神调节,这些药物守护大脑健康!内容涵盖:1.中枢神经系统药物表格系统分类速查2.解热镇痛抗炎药和抗痛风药对抗疼痛与炎症3.中枢镇痛药强效缓解剧痛4.抗精神失常药稳定情绪思维5.治疗退行性疾病药延缓阿尔茨海默等进展6.抗癫痫药和抗惊厥药控制神经异常放电7.镇静催眠药与促觉醒药调节睡眠与清醒节律一表掌握神经药物关键信息!
- 统计推断复习
医学统计学推断部分复习总结,"统计推断的核心:从数据中挖掘真相!本文系统梳理统计推断要点,涵盖参数估计(可信区间计算、中心极限定理应用)、假设检验(z检验、两类错误控制)和方差分析(变异分解思想)重点解析:①置信区间与医学参考值范围的区别②标准差与标准误的异同③多重比较替代t检验的原因④不同设计类型的变异分解附统计描述技巧(频数表、直方图绘制)和资料类型处理(计量/计数/等级资料),助你掌握数据分析底层逻辑。
- 统计学复习
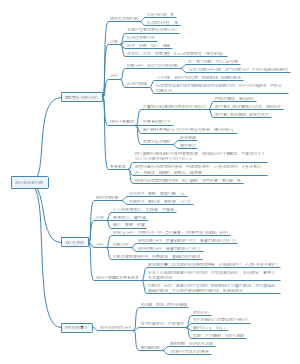
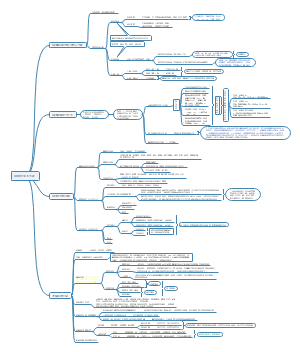
医学统计学个人总结,医学统计学的核心:从数据中发现真相!本文涵盖统计基础到实践应用,包括总体与样本、同质与变异、抽样误差等核心概念重点解析统计工作四步骤(设计、收集、整理、分析)和两类统计方法(描述与推断),详解t检验、卡方检验等方法的适用场景特别探讨参数估计(点估计/区间估计)与假设检验的完整流程,以及不同资料类型(定量/定性)的描述技巧理解这些工具,助你准确分析医学数据差异!
统计推断复习
社区模板帮助中心,点此进入>>
- 药理学中枢神经系统药物表格
药理学中枢神经系统表格总结,【中枢神经系统药物全览】从镇痛消炎到精神调节,这些药物守护大脑健康!内容涵盖:1.中枢神经系统药物表格系统分类速查2.解热镇痛抗炎药和抗痛风药对抗疼痛与炎症3.中枢镇痛药强效缓解剧痛4.抗精神失常药稳定情绪思维5.治疗退行性疾病药延缓阿尔茨海默等进展6.抗癫痫药和抗惊厥药控制神经异常放电7.镇静催眠药与促觉醒药调节睡眠与清醒节律一表掌握神经药物关键信息!
- 统计推断复习
医学统计学推断部分复习总结,"统计推断的核心:从数据中挖掘真相!本文系统梳理统计推断要点,涵盖参数估计(可信区间计算、中心极限定理应用)、假设检验(z检验、两类错误控制)和方差分析(变异分解思想)重点解析:①置信区间与医学参考值范围的区别②标准差与标准误的异同③多重比较替代t检验的原因④不同设计类型的变异分解附统计描述技巧(频数表、直方图绘制)和资料类型处理(计量/计数/等级资料),助你掌握数据分析底层逻辑。
- 统计学复习
医学统计学个人总结,医学统计学的核心:从数据中发现真相!本文涵盖统计基础到实践应用,包括总体与样本、同质与变异、抽样误差等核心概念重点解析统计工作四步骤(设计、收集、整理、分析)和两类统计方法(描述与推断),详解t检验、卡方检验等方法的适用场景特别探讨参数估计(点估计/区间估计)与假设检验的完整流程,以及不同资料类型(定量/定性)的描述技巧理解这些工具,助你准确分析医学数据差异!
- 相似推荐
- 大纲