导图社区 数据关联的探索
卫生统计学8版教材,内容有 数据的关联、散点图、相关、回归现象、相关与回归的陷阱、分类变量的相关、关联与因果,一起来看吧!
卫生统计学 人卫8版,整理了概率、概率分布、蒙特卡罗模拟的内容,希望这份脑图会对你有所帮助。
这是一个关于医学模式的思维导图,包括了古代和现代的医学模式。
社区模板帮助中心,点此进入>>
小儿常见病的辩证与护理
蛋白质
均衡饮食一周计划
消化系统常见病
耳鼻喉解剖与生理
糖尿病知识总结
细胞的基本功能
体格检查:一般检查
心裕济川传承谱
解热镇痛抗炎药
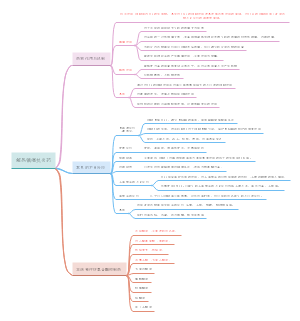
数据关联的探索
数据的关联
两变量的关联性分析
互依关系:相关分析
变量Y与变量X间的相互关系
从属关系:回归分析
应变量Y随自变量X变化而变化
定量描述两变量的关联时需考虑:
(1)两变量是否真的存在关联 Eg:某君喜得贵子,庭前种一小树,每日测子高与树高,积累数据发现子高与树高具有相关性。(伴随关系) (2)两变量的关联方向和关联强度 (3)两变量间的数量依存关系 (4)两变量的关联关系中是否受到其他因素的影响和干扰
散点图
如何描述两连续变量之间的关系?
散点图: 用点的密集程度、趋势表示两变量间的相关关系。(探索关联性的第一步)
图的解释
制作散点图
评价散点图步骤
(1)观察图的总体趋势和明显偏离该趋势的观测单位 (2)通过散点图的总体趋势来呈现关联的形式、方向和密切程度
散点图解释
(1)散点呈现线性趋势 (2)两变量同时增大或减小,即呈正相关
相关
概述
两个变量之间,一个增大,另一个也相应地增大(或减小),这种现象称为共变,即这两个变量间有“相关关系”
两个随机变量之间这种呈线性趋势的关系称为线性相关 (linear correlation) ,又称简单相关(simple correlation) ,简称相关 (correlation)
散点呈圆形分布
X、Y同时增减---正相关(positive correlation)
X、Y此增彼减---负相关(negative correlation)
散点在一条直线上
X、Y变化趋势相同----完全正相关
X、Y反向变化----完全负相关
X、Y变化互不影响或无直线相关关系----零相关(zero correlation)
直线相关系数
概念
相关系数(correlation coefficient),又称积差相关系数,或Pearson 相关系数(Pearson product moment coeficient) (软件常用此名)用以定量描述两变量间线性关系的密切程度和相关方向的统计指标
r——样本相关系数 ρ——总体相关系数
意义与计算
公式1
对于n个观测单位的变量x和变量y,其均数和标准差分别为 则x和y的直线相关系数r为
r说明了两变量间线性关系的密切程度与相关方向。 r无单位,-1≤r≤1。 |r|=1--- 完全相关 |r|≥ 0.7---高度相关 0.7>|r|≥0.4---中度相关 |r| < 0.4---低度相关 |r|=0 --- 零相关。
r值为正---正相关,为负---负相关 (与回归系数b的符号相同)
解释:两变量呈正相关关系,OAP随粮食中DON含量升高而增大,相关强度为0.7863。
公式2
例题
解释:12名调查对象的体重与肺活量之间呈线性正相关关系,关系的强度为0.944。
相关系数的假设检验
在调查对象总体中,两变量之间也存在这种线性关系吗? r≠0原因:由于抽样误差引起,ρ=0 存在相关关系,ρ≠0
注意事项
(1)直线相关要求两个变量均为定量变量(用于双变量正态分布资料) (2) r的计算去掉了量纲的影响,本身无单位,只是一个数值 (3)直线相关只衡量两个变量间线性关系的方向和密切程度,不能描述其他情形的关系(曲线关系不可) (4)相关系数受离群点的影响,当散点图中出现离群点时应慎用相关 (5)相关无需区分反应变量和解释变量,但也不排斥 (6)完整描述两变量需相关系数结合两变量的均数和标准差
秩相关系数
等级相关(秩相关)rank correlation :反映两个变量间的相关性
适用资料:(1)不服从双变量正态分布(无法用均数和标准差描述) (2)总体分布类型未知 (3)原始数据用等级表示
秩相关系数/等级相关系数(Spearman Correlation Coefficient):反映两变量间相关的密切程度与方向
秩次/秩(rank):将数值从小到大排序、等级变量值从弱到强排列的序号。 出现相等数据造成秩次相同称相持 (tie),则计算平均秩次。
计算及意义
先将n对观测值xi与yi(i=1,2,3...,n) 分别从小到排序编为pi、qi (相持时取平均值)
分别计算pi、qi的均数和标准差
最后再把秩次代入直线相关系数的计算公式,即: 算出结果后,要解释 公式2,这里的X和Y分别代表每对观察值的秩次p和q,打错了。
rs说明了两变量间线性关系的密切程度与相关方向。 rs无单位,-1≤r≤1。 |rs|=1--- 完全相关 |rs|=0 --- 零相关。 rs值为正---正相关,为负---负相关
回归现象
简单回归的概念
当研究两个变量间数量依存关系时,需区分反应变量和解释变量。 解释变量/自变量X(independent variable):解释或引起反应变量Y改变的变量 (Y所依存的变量) 反应变量/应变量/结局变量Y(dependent variable) :是对研究结局的测量(被估计或被预测的变量)
简单线性回归:某一变量Y随着另一变量X的变动而变动,其散点图呈直线趋势,则把这种描述两变量间依存变化的数量关系的现象称为简单线性回归 (simplelinearregression)
回归关系与函数关系的区别:函数关系:x与y一 一对应 回归关系:x并非确定性的决定y
回归直线的拟合
基本概念
回归直线(regression line) : 描述反应变量Y如何随解释变量X改变而改变的直线。 回归方程: 刻画回归直线的方程
读作Y哈特 b0:截距(interept) b0>0: 回归线与纵轴交点在原点上方。b0<0:回归线与纵轴交点在原点下方 b0=0:回归线通过原点 b1:斜率(slope),回归系数(regression coefficient) 意义:X每改变一个单位,Y平均增加或减少的估计值 b1>0,Y随X的增大而增大一斜上; b1<0,Y随X的增大而减小一斜下; b1=0,Y与X无直线关系一水平 |b|越大,Y随X变化越快,直线越陡峭。
回归系数的假设检验
b≠0能否说明总体中DON (X) 与OAP (Y) 存在线性回归关系呢? b≠0原因: 由于抽样误差引起,总体回归系数 β=0 存在回归关系,总体回归系数β≠0
拟合回归直线的方法:最小二乘法原则:使各实测点到回归直线的纵向距离的平方和最小
求解回归方程
回归方程的解释
1.截距b0的解释:当X为0时,Y的平均估计值为b0 本例截距b0=4.7846分,表明当粮食中DON含量为0时OAP的平均估计值为4.7846分 2.斜率b1的解释:当X每增加一个单位时,Y平均改变b1个单位 本例斜率b1=0.0297,表明在所研究的脱氧雪腐镰刀菌烯醇(DON)范围内,粮食中DON含量每增加1μg/g,患者骨关节炎得分(OAP)就平均增加0.0297分。
相关系数和回归系数关系紧密。
回归中要明确区分反应变量和解释变量。(关注y方向上点到直线的纵向距离)
斜率和截距取决于测量值的单位,一般不用它们的大小衡量x对y的影响力大小(决定系数r²可以),只是x为某单位下它的增量引起y增量的改变。
回归直线概括了整体趋势,给出的预测值并不一定完全准确,只是对整体趋势的一个预测。
残差和残差图
残差( residuals) 残差ei=观察值Yi-预测值Yi哈特,是变量的观测值与基于回归直线的预测值之间的差异。
残差图 (residual plots)
定义:是残差相对于解释变量或反应变量预测值的散点图
用途:评价回归直线与散点的接近程度
以0水平线作为参照,直线与散点的接近程度较好的残差图应呈现为一条无规律且集中于0的水平带。 (若回归直线完全拟合则残差为0)
例:散点先大于估计值,又小于估计值,最后大于估计值,呈现出一定的规律,不是线性趋势
决定系数
决定系数 (r²或R²)
决定系数r²即相关系数r的平方 0≤r²≤1无单位
决定系数的意义:在反应变量Y的总变异中因X与Y的回归关系所能解释的比例,可反映回归贡献的相对程度,也可反映回归拟合的实际效果 (r² > 0.7 拟合良好)
决定系数r²越大b1越大,相关关系越强,X对Y的影响越大,回归效果越好。
解释
例2中38个对象的OAP和粮食中DON含量的相关系数r=0.7863,r²=0.6185,则表明OAP的变异中约61.85%的变异可以用y与x的直线回归关系来解释,剩余38.15%的变异可用x以外的其他因素解释
eg:在一项营养调查中,研究者检测了12名调查对象的体重与肺活量,用简单直线回归分析体重与肺活量之间的数量关系算得r²=0.8915,试说明其意义。 r²=0.8915,说明体重能解释其肺活量变异的89.15%,仅有10.85%的变异是由体重以外的其他因素来解释的,即用体重来预测肺活量的实际效果较好
直线相关与回归的区别与联系
区别
资料要求
相关:X、Y均为随机变量,服从双变量正态分布 回归: Y为正态随机变量,X为选定变量
应用
相关—只反映两变量间相互关系,表明两变量间关系的方向和密切程度 回归—两变量间的从属关系,有自变量与应变量之分,用函数方程表达两变量的数量关系
r和b1的绝对值意义不同
|r|越大,散点越趋于一条直线,两变量关系越密切,相关程度越高 |b1|越大,回归直线越陡,说明当X变化一个单位时,Y的平均变化越大
联系
方向一致:r与b1的正负号一致
相关与回归的陷阱
离群点与强影响值
离群点:处于其他观测值总体趋势以外的观测值
强影响点:对计算造成较大影响的观测值,若剔除会使结果明显变化。
判断
离群点需区分方向:x方向和y方向的离群点。x方向离群点未必在y方向上有很大的回归残差。
评价一个可疑观察点对回归直线的影响,可在包括和去除该可疑观察点这两种情况下做回归分析。
有时不需要区分离群点和强影响点,但不是所有的离群点都是强影响点
不能依据残差大小判断是否为强影响点
观测值范围
变量的取值范围变异太小影响相关关系的强度,导致建立的关联性不稳定
外推(extrapolation): 用现有解释变量x值获得的回归直线,来预测x值范围外的反应变量y值,应避免外推
非线性相关
散点图及残差图显示两变量存在非线性趋势。则可通过数据转换将非线性数据转为线性关联 对数转换适用于变量为正时,但变异呈指数级变化的数据。将原始值进行对数转换后,替代原始值进行分析,更趋近直线关系 也可用原始数据拟合曲线来探索两变量的关联(了解)
潜在影响变量 (分层分析)
探索两变量间的关联性时,单独分析发现存在关联或无关联,但以变量的某种属性进行分层分析即引入第三变量分层时,再分析其关系,原有关联会在某些层内发生变化甚至方向相反,此第三变量即潜在影响变量。 注意:分层资料盲目合并易造成假象 第三变量若为定量变量则可转为分类变量进行分析 (a原本为正相关,分层后零相关。b原本零相关,分层后正相关。c原本负相关,分层后正相关。)
平均数的相关
平均数的相关潜在影响变量 基于大量个体平均值的相关强度通常要高于基于相同变量的个体数据之间的相关强度 根据实际问题及研究目的明确研究变量和观测单位十分重要
其他注意事项
要有实际意义;(女生的体重和男生的身高) 先绘制散点图 (有无离群值,是否有线性趋势) ; 有联系不一定是因果关系,也可能是伴随关系(树高、人高) 两变量间无线性关系,不代表没关系(曲线) 进行相关和回归都必须进行假设检验
分类变量的相关
交叉表的制作
当两变量均为分类变量时,原始数据可以整理成交叉表(cross table)(或列联表)的形式 以组别的形式呈现数据的结构,用研究对象的例数(频数)或者比例(相对频数)来描述 可给出两个变量值的组合例数
条件分布与关联
联合分布
两分类变量的所有单元格的构成比组成两变量的联合分布。
边缘分布
交叉表中单个变量的分布称为该变量的边缘分布。 较边缘分布,联合分布能提供更多信息,帮助了解两变量的关系
条件分布
在设定一个变量取值的条件下,计算另一个变量取值的分布,所得到的分布
关联
比较可得到性别和维生素D缺乏情况的关系,即女童的维生素D缺乏比例高于男童(0.2968>0.1986)。
Pearson列联系数
1.数据整理 将所得数据整理为交叉表,并计算相应的联合分布和边缘分布。
2.列联系数计算 两分类变量的关联性一般采用Pearson列联系数(contingency coefficient)r来反映,其计算公式为
计算步骤:理论频数 → c² → r 计算理论频数,交叉1,4项为正,2,3项为负 计算c²,每一项的分子都相同 计算r,记得是整体开平方,用手机计算器要加括号
分类变量相关分析的陷阱
与定量变量一样,分类变量进行相关性分析时要注意潜在的影响变量,单独分析两变量和按潜在影响变量分层后再分析两变量,原有的关联会在某些层内发生变化,有时甚至方向发生反转 若忽视潜在影响变量,观察的结果可能会造成误导,这一现象称为辛普森悖论(Simpson’s paradox)。
例:
结论:VD水平低的人群中日常体力水平为静态的比例更大,分析时“静态”增大了VD水平低者患心脏病的比例。
关联与因果
关联中因果、共变与混杂
即使两变量存在很强的关联性,仍不能证实两变量间存在因果关系
几种常见的关联模式如下。虚线双箭头一存在关联,实线箭头一有因果关系
因果:解释变量x变化是y变化的原因,为直接因果关系。 例:动物实验中黄曲霉毒素可诱发小鼠肝癌。
共变:x和y的关联实际是由另一个影响变量z引起的。 例:由于夏季高温,造成游泳溺亡人数与冷饮销量同时升高而呈现较强的正向关联
混杂:解释变量x和另一个影响变量z都会对反应变量y产生影响。由于z对x的混杂作用,不能把x和z的效应分开 例:研究吸烟与肺癌关联时,研究者收集的数据中可能吸烟组的中老年人比例高于非吸烟组从而得到的关联性夸大了吸烟与肺癌的因果关系,称之为混杂(confounding)
因果的确定
因果确定最直接有效的方法是实验(控制所有可能的混杂变量的效应)但是人群研究涉及伦理及实际情况,实验往往不可行 运用统计分析方法说明因果关联存在争议,但在满足某些条件时,仍可提示很强的因果关系,如吸烟与肺癌关联的经典例子。
流行病学方法
病因推断的10条标准(希尔准则) : 1.时间顺序 2.关联强度 3.剂量-反应关系 4.结果的一致性 5.实验证据 6.生物学合理性 7.生物学一致性 8.特异性 9.相似性 10.预测力