导图社区 资料的整理与分析
- 36
- 0
- 0
- 举报
资料的整理与分析
护理,资料的整理是 资料收 集阶段 完成后 科研工 作的继 续,也 是统计 分析的 前提。
编辑于2023-05-18 21:49:51- 护理资料整理与分析
- 相似推荐
- 大纲
资料的整理与分析
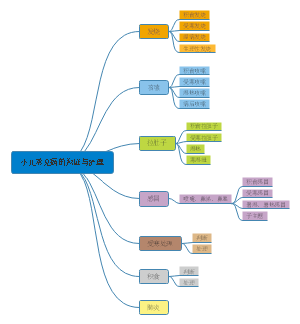
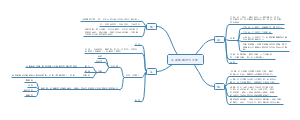
资料的整理
资料的 整理是 资料收 集阶段 完成后 科研工 作的继 续,也 是统计 分析的 前提。
核较原始数据
遗漏的数据→尽量补充完整 重复的资料→经核实无误,应予以删除 过大过小异常值的资料→必要时重新收集数据
专业检查
指从专业的角度 利用专业知识或 生活常识来发现 和纠正错误。
eg:产后两周10月经恢复来潮 女性病人患前列腺癌
统计检查
按统计学要求,通 过数据统计规律发 现和纠正错误
eg:人体体温值记录为56.4℃
计算机检查
当原始数据录入 计算机后,可通 过计算机对全部 数据进行检查。
eg:性别”这个变量用 1表示(男性),2表示(女 性),9表示(缺失),如果 出现数字4,必然是数据 录入错误。
建立数据库
建立数据库是进行统计分析的基础,目前 研究者通常使用统计软件建立数据库,如 EpiData 数据录入软件、SPSS社会科学统 计软件包、SAS等。 SPSS是目前国际上最流行的统计分析软件 之一,广泛应用于社会科学,心理学,医学 的领域。
打开SPSS数据库
输入变量名称及属性
1.输入变量名称及标签:变量名称的 首字母必须是汉字或英文字母,其 后可用字母,数字,下划线等。
2.选择变量类型:输入变量名称后,在 类型(type)栏中默认的类型是数值型(Numeric)。
3.调整宽度
4.调整小数点后位数
5. 标记值标签
录入和保存数据
录入数据
在变量界面(VariableView)写好所有变量 的名称及其属性后,点击数据界面,回到主界面
保存数据
在"文件(File)"下拉菜单中选择"保存(Save)"
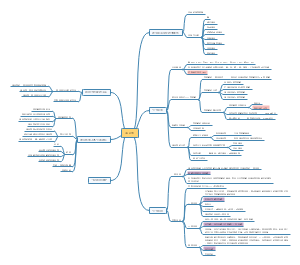
数据的编辑
计算变量
1.选择编辑选项:在SPSS 数据库中,点击“转换(Transform)"下拉菜单中的“计算变量(Compute Variable)”
2.输入计算公式:弹出“计算变量(Compute Variable)”对话框(图8-8),在左上角“目标变量(Target Variable)”栏中,输入要计算出的新变量名称“总分”;在“公式表达(Numeric Expression)”栏中,利用该栏下方提供的“+”符号键,输入计算公式“a1+a2+···a20”。
3.点击“OK”产生新变量: 本例中,输入将20个条目相加的公式后,点击“OK”按钮,即产生 一个新变量“总分”。
重新编码
重新编码为相同变量
1)选择编辑选项:点击“转换(Transform)”下拉菜单中的"Recode into Same Variables” 2)选择变量:在弹出的“Recode into Same Variables”对话框中(图8-10),从左侧变量列表中,将需要重新编码的变量(a5、a9、a13、a17、a19)选入“数值型变量(Numeric Variables)”框内。然后,点击下方的“原值和新值(0Id and New Values)”按钮。
3)定义编码规则:在弹出的“原值和新值(Old and New Values)”对话框中
4)完成重新编码:点击“继续(Continue)”按钮,回到图 8-10所示对话框,点击“0K”按钮,即完 成对该变量的重新编码。
重新编码为不同变量
1)选择编辑选项:点击“转换(Transform)”下拉菜单中的“Recode into DifferentVariables”。 2)选择变量:在弹出的“Recode into Different Variables”对话框中(图8-12)
3)定义编码规则:在弹出的“原值和新值(Old and New Values)“对话框中(图8-13) 4)生成重新编码的新变量:点击“继续(Continue)”按钮,回到图8-12所示对话框,点击“0K” 按钮,即在原变量“总分”的基础上,生成一个新变量
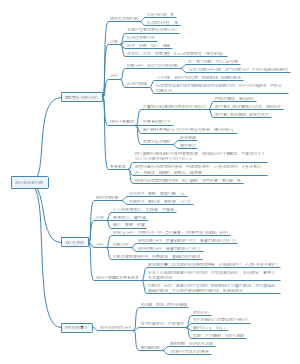
资料的统计学分析
基本概念
1.同质与变异:同志是指研究对象具有的相同状况或属性等共性 变异是指每个研究对象的变量值之间的差异 统计学的任务就是从事物的同质性与变异性的数量表现出发。通过一定数量的对比与分析,揭示出事物的本质特征与规律
2.抽样误差:由于抽样研究所致的样本指标与总体指标之间的差异称为抽样误差 减少抽样误差:①用随机抽样的方法提高样本的代表性②增加样本量到适当水平③选择变异程度小的研究指标
3.假设检验:又称显著性检验,是应用统计学原理,由样本之间的差异去推断样本所代表的总体之间是否有差异的一种推断方法
4.概率:在统计学上用符号p表示概率,p值在0到1之间,越接近于1,表示事件发生的可能性越大,越接近于0表示某事件发生的可能性越小 通常将p<=0.05或p<=0.01称为小概率事件,表示该事件发生的可能性很小,并将其看作事物差异有统计学意义的界限,若p<=0.05或p<=0.01,可得出差异有统计学意义的推论,若p>0.05则得出差异无统计学意义的推论
科研资料的类型
计量资料 (连续型资料)使用定量方法测量某项指标量的大小而获得的资料 计数资料 (无序分类资料)将观察单位按某种属性或类别分组,计数各组例数而得到的资料 等级资料 (有序分类资料)观察单位按某种属性的不同程度分成等级,计数各组例数而得到的资料
资料类型的转换
注意:计数资料或等级资料无法转换成计量资料,计量资料转可转化成计数资料或等级资料 ①互斥性:指每一个组别只能包含特定属性或特征的观察单位,不能相互兼容 ②穷尽性:就是使总体中的每一个观察单位都应有其所能归属的对应的组
描述性统计
质计量资料的描述性统计:质量资料的数据分布形态可分为正态分布和偏态分布,对于正态分布通常采用最小值,最大值,均数,正负标准差进行描述性统计,对于呈偏态分布的质量资料,则采取最小值,最大值,中位数,四分位数,间距进行描述性统计
1.计量资料的描述性统计:计量资料的数据分布形态可分为正态分布和偏态分布 正态分布 通常采用最小值,最大值,均数,正负标准差进行描述性统计 偏态分布 则采取最小值,最大值,中位数,四分位数间距进行描述性统计 具体计算公式:课本P171
2.计数资料和等级资料的描述性统计 技术资料 通常用相对数指标进行描述性统计,最常用的统计指标是率,构成比,相对比。 等级资料 通常用构成比进行描述性统计 具体计算公式:课本P173
比较组间差异的统计分析方法
①单样本t检验 适用于研究中只有一个样本,将样本均属于已 知总体均数进行比较且符合正态分布的计量资料
②两独立样本t检验 适用于两个独立样本的均数比较且均为成正态分布的计量资料
③ 配对样本t检验 适用于配对设计的两个样本均数比较,且两组资料均呈正态分布 对设计包括以下情形:同一研究对象分别接受两种不同处理,同一研究对象接受同一种处理前后的比较
④单因素方差分析 适用于三组及以上独立样本的均数比较,且各组资料均呈正态分布 P<=0.05或p<=0.01,说明各组间均数不全相等,但不能说明哪两组之间存在差异
⑤x2检验 四格表x方检验——课本P179 行x列表x2检验——课本P180~181
⑥秩和检验 适用于等级资料的比较以及成偏态分布的计量资料的比较不同的秩和检验方法。 ①配对设计:采用Wilcoxon符号秩和检验; ②两个独立样本比较:采用Wilcoxon 秩和检验或Mann-Whitney u检验; ③多个独立样本比较:采用Kruskal-WallisH秩和检验。
分析变量间关系的统计分析方法
相关分析 结果表述:在进行相关分析时计算出r值后需对其进行假设检验。以判断这种相关是本质存在还是抽样误差所致,因此在表述相关分析结果时,需列出两个变量之间的相关系数(r),以及对相关系数进行假设检验的p值
1. Pearson 相关分析适用于两个变量均为计量资料且符合正态分布
2.Spearman相关分析适用于下列情况:①两个变量均为等级资料;②两个变量其一为计量资料,另一个变量为等级资料;③两个变量虽为计量资料,但不服从正态分布。
回归分析
1.多元线性回归:用于分析一个连续型应变 量与多个自变量之间的线性关系,适用于 因变量为计量资料的情况
2.Logistic回归:用于分析一个二分类因变量与多个自变量之间的关 系,适用于因变量为二分类计数资料的情况
原则 1)对样本量的要求:与多元线性回归分析的样本量估算方法有所不同,选行logjistic 回归时,阳性样本数至少是自变量个数的5~10倍。 2)变量的赋值方法:因变量为二分类变量,以0、1赋值。自变量的赋值方法与多元线性回归类似。 3)回归分析的结果表述:Logistic 回归报告结果时,至少应写明下列内容:①因变量的名称及赋值方法。②自变量的名称及赋值方法。③进人回归方程的自变量名称、Wald值及P值、OR值等。
原则 1)对样本量的要求:当样本量过少时,建立的回归方程不稳定。一般来说,样本量至少应是自变量个数的10倍。 2)变量的赋值方法:进行多元线性回归分析时,因变量为计量资料,以原始数值录入。自变量根据资料类型的不同进行赋值。 3)回归分析的结果表述:报告结果时至少应写明下列内容:①因变量的名称。②自变量的名称及赋值方法。③进入回归方程的自变量名称、偏回归系数(B值)、标准化回归系数(β值)、值和P值。
统计表与统计图
统计表:种类,结构与绘制要求,注意事项 课本P187
统计图:种类,结构与绘制要求 课本P188
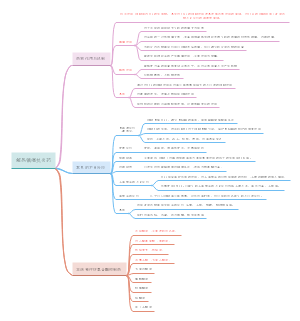
资料的整理与分析
资料的整理
资料的 整理是 资料收 集阶段 完成后 科研工 作的继 续,也 是统计 分析的 前提。
核较原始数据
遗漏的数据→尽量补充完整 重复的资料→经核实无误,应予以删除 过大过小异常值的资料→必要时重新收集数据
专业检查
指从专业的角度 利用专业知识或 生活常识来发现 和纠正错误。
eg:产后两周10月经恢复来潮 女性病人患前列腺癌
统计检查
按统计学要求,通 过数据统计规律发 现和纠正错误
eg:人体体温值记录为56.4℃
计算机检查
当原始数据录入 计算机后,可通 过计算机对全部 数据进行检查。
eg:性别”这个变量用 1表示(男性),2表示(女 性),9表示(缺失),如果 出现数字4,必然是数据 录入错误。
建立数据库
建立数据库是进行统计分析的基础,目前 研究者通常使用统计软件建立数据库,如 EpiData 数据录入软件、SPSS社会科学统 计软件包、SAS等。 SPSS是目前国际上最流行的统计分析软件 之一,广泛应用于社会科学,心理学,医学 的领域。
打开SPSS数据库
输入变量名称及属性
1.输入变量名称及标签:变量名称的 首字母必须是汉字或英文字母,其 后可用字母,数字,下划线等。
2.选择变量类型:输入变量名称后,在 类型(type)栏中默认的类型是数值型(Numeric)。
3.调整宽度
4.调整小数点后位数
5. 标记值标签
录入和保存数据
录入数据
在变量界面(VariableView)写好所有变量 的名称及其属性后,点击数据界面,回到主界面
保存数据
在"文件(File)"下拉菜单中选择"保存(Save)"
数据的编辑
计算变量
1.选择编辑选项:在SPSS 数据库中,点击“转换(Transform)"下拉菜单中的“计算变量(Compute Variable)”
2.输入计算公式:弹出“计算变量(Compute Variable)”对话框(图8-8),在左上角“目标变量(Target Variable)”栏中,输入要计算出的新变量名称“总分”;在“公式表达(Numeric Expression)”栏中,利用该栏下方提供的“+”符号键,输入计算公式“a1+a2+···a20”。
3.点击“OK”产生新变量: 本例中,输入将20个条目相加的公式后,点击“OK”按钮,即产生 一个新变量“总分”。
重新编码
重新编码为相同变量
1)选择编辑选项:点击“转换(Transform)”下拉菜单中的"Recode into Same Variables” 2)选择变量:在弹出的“Recode into Same Variables”对话框中(图8-10),从左侧变量列表中,将需要重新编码的变量(a5、a9、a13、a17、a19)选入“数值型变量(Numeric Variables)”框内。然后,点击下方的“原值和新值(0Id and New Values)”按钮。
3)定义编码规则:在弹出的“原值和新值(Old and New Values)”对话框中
4)完成重新编码:点击“继续(Continue)”按钮,回到图 8-10所示对话框,点击“0K”按钮,即完 成对该变量的重新编码。
重新编码为不同变量
1)选择编辑选项:点击“转换(Transform)”下拉菜单中的“Recode into DifferentVariables”。 2)选择变量:在弹出的“Recode into Different Variables”对话框中(图8-12)
3)定义编码规则:在弹出的“原值和新值(Old and New Values)“对话框中(图8-13) 4)生成重新编码的新变量:点击“继续(Continue)”按钮,回到图8-12所示对话框,点击“0K” 按钮,即在原变量“总分”的基础上,生成一个新变量
资料的统计学分析
基本概念
1.同质与变异:同志是指研究对象具有的相同状况或属性等共性 变异是指每个研究对象的变量值之间的差异 统计学的任务就是从事物的同质性与变异性的数量表现出发。通过一定数量的对比与分析,揭示出事物的本质特征与规律
2.抽样误差:由于抽样研究所致的样本指标与总体指标之间的差异称为抽样误差 减少抽样误差:①用随机抽样的方法提高样本的代表性②增加样本量到适当水平③选择变异程度小的研究指标
3.假设检验:又称显著性检验,是应用统计学原理,由样本之间的差异去推断样本所代表的总体之间是否有差异的一种推断方法
4.概率:在统计学上用符号p表示概率,p值在0到1之间,越接近于1,表示事件发生的可能性越大,越接近于0表示某事件发生的可能性越小 通常将p<=0.05或p<=0.01称为小概率事件,表示该事件发生的可能性很小,并将其看作事物差异有统计学意义的界限,若p<=0.05或p<=0.01,可得出差异有统计学意义的推论,若p>0.05则得出差异无统计学意义的推论
科研资料的类型
计量资料 (连续型资料)使用定量方法测量某项指标量的大小而获得的资料 计数资料 (无序分类资料)将观察单位按某种属性或类别分组,计数各组例数而得到的资料 等级资料 (有序分类资料)观察单位按某种属性的不同程度分成等级,计数各组例数而得到的资料
资料类型的转换
注意:计数资料或等级资料无法转换成计量资料,计量资料转可转化成计数资料或等级资料 ①互斥性:指每一个组别只能包含特定属性或特征的观察单位,不能相互兼容 ②穷尽性:就是使总体中的每一个观察单位都应有其所能归属的对应的组
描述性统计
质计量资料的描述性统计:质量资料的数据分布形态可分为正态分布和偏态分布,对于正态分布通常采用最小值,最大值,均数,正负标准差进行描述性统计,对于呈偏态分布的质量资料,则采取最小值,最大值,中位数,四分位数,间距进行描述性统计
1.计量资料的描述性统计:计量资料的数据分布形态可分为正态分布和偏态分布 正态分布 通常采用最小值,最大值,均数,正负标准差进行描述性统计 偏态分布 则采取最小值,最大值,中位数,四分位数间距进行描述性统计 具体计算公式:课本P171
2.计数资料和等级资料的描述性统计 技术资料 通常用相对数指标进行描述性统计,最常用的统计指标是率,构成比,相对比。 等级资料 通常用构成比进行描述性统计 具体计算公式:课本P173
比较组间差异的统计分析方法
①单样本t检验 适用于研究中只有一个样本,将样本均属于已 知总体均数进行比较且符合正态分布的计量资料
②两独立样本t检验 适用于两个独立样本的均数比较且均为成正态分布的计量资料
③ 配对样本t检验 适用于配对设计的两个样本均数比较,且两组资料均呈正态分布 对设计包括以下情形:同一研究对象分别接受两种不同处理,同一研究对象接受同一种处理前后的比较
④单因素方差分析 适用于三组及以上独立样本的均数比较,且各组资料均呈正态分布 P<=0.05或p<=0.01,说明各组间均数不全相等,但不能说明哪两组之间存在差异
⑤x2检验 四格表x方检验——课本P179 行x列表x2检验——课本P180~181
⑥秩和检验 适用于等级资料的比较以及成偏态分布的计量资料的比较不同的秩和检验方法。 ①配对设计:采用Wilcoxon符号秩和检验; ②两个独立样本比较:采用Wilcoxon 秩和检验或Mann-Whitney u检验; ③多个独立样本比较:采用Kruskal-WallisH秩和检验。
分析变量间关系的统计分析方法
相关分析 结果表述:在进行相关分析时计算出r值后需对其进行假设检验。以判断这种相关是本质存在还是抽样误差所致,因此在表述相关分析结果时,需列出两个变量之间的相关系数(r),以及对相关系数进行假设检验的p值
1. Pearson 相关分析适用于两个变量均为计量资料且符合正态分布
2.Spearman相关分析适用于下列情况:①两个变量均为等级资料;②两个变量其一为计量资料,另一个变量为等级资料;③两个变量虽为计量资料,但不服从正态分布。
回归分析
1.多元线性回归:用于分析一个连续型应变 量与多个自变量之间的线性关系,适用于 因变量为计量资料的情况
2.Logistic回归:用于分析一个二分类因变量与多个自变量之间的关 系,适用于因变量为二分类计数资料的情况
原则 1)对样本量的要求:与多元线性回归分析的样本量估算方法有所不同,选行logjistic 回归时,阳性样本数至少是自变量个数的5~10倍。 2)变量的赋值方法:因变量为二分类变量,以0、1赋值。自变量的赋值方法与多元线性回归类似。 3)回归分析的结果表述:Logistic 回归报告结果时,至少应写明下列内容:①因变量的名称及赋值方法。②自变量的名称及赋值方法。③进人回归方程的自变量名称、Wald值及P值、OR值等。
原则 1)对样本量的要求:当样本量过少时,建立的回归方程不稳定。一般来说,样本量至少应是自变量个数的10倍。 2)变量的赋值方法:进行多元线性回归分析时,因变量为计量资料,以原始数值录入。自变量根据资料类型的不同进行赋值。 3)回归分析的结果表述:报告结果时至少应写明下列内容:①因变量的名称。②自变量的名称及赋值方法。③进入回归方程的自变量名称、偏回归系数(B值)、标准化回归系数(β值)、值和P值。
统计表与统计图
统计表:种类,结构与绘制要求,注意事项 课本P187
统计图:种类,结构与绘制要求 课本P188