导图社区 流行病学第五章5病例对照研究
流行病学第五章5病例对照研究知识总结,包括它的基本原理、特点、研究类型、用途、研究设计与实施、资料的整理与分析、偏倚及其控制等等。
流行病学第十一章11传染病流行病学2:新中国成立以来,我国对传染病防治一直实行预防为主的方针,坚持防治结合、分类管理、依靠科学、全社会参与。
流行病学第十一章11传染病流行病学1:人群作为一个整体对传染病的易感程度称为人群易感性,人群易感性的高低取决于该人群中易感者所占的比例。
流行病学第八章病因及其发现和推断知识总结,包括病因的基本概念、病因学说与病因模型、充分病因-组分病因模型、发现和验证病因等内容。
社区模板帮助中心,点此进入>>
小儿常见病的辩证与护理
蛋白质
均衡饮食一周计划
消化系统常见病
耳鼻喉解剖与生理
糖尿病知识总结
细胞的基本功能
体格检查:一般检查
心裕济川传承谱
解热镇痛抗炎药
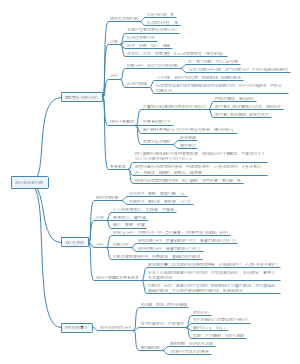
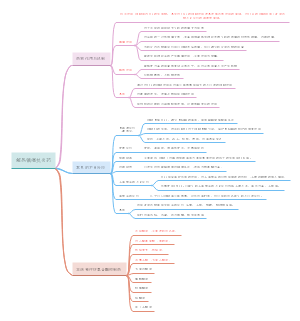
病例对照研究
第一节 概述
基本原理
以当前已经确诊的患有某特定疾病的一组人作为病例组,以不患有该病但具有可比性的一组个体作为对照组,通过询问、实验室检查或复查病史,搜集研究对象既往对各种可能的危险因素的暴露史,测量并采用统计学检验,比较病例组与对照组各因素暴露比例的差异是否具有统计学意义,然后评估各种偏倚对研究结果的影响,并借助病因推断技术,判断某个或某些暴露因素是否为疾病的危险因素,从而达到探索和检验病因假说的目的
由果及因,一定程度上检验病因假说
基本特点
观察性研究
暴露情况是自然存在而非人为控制,并已发生
研究对象分为病例组和对照组
由果溯因
因果联系的论证强度相对较弱
研究类型
非匹配病例对照研究(成组病例对照研究):对照的选择没有其他任何限制与规定,对照人数应等于或多于病例人数
匹配病例对照研究:选择的对照在某些因素或特征上与病例保持一致,目的是使匹配因素在病例组与对照组之间保持均衡,从而排除这些因素对结果的干扰
衍生的几种主要研究类型
巢式病例研究
在队列研究的基础上,在一定观察期中当新发病例累积到一定数量时,将全部病例集中成病例组,在每个病例发病当时,从同一队列的未发病中按一定匹配条件随机选择对照,集中组成对照组
病例-队列研究
在队列研究开始时,在队列中按一定比例随机抽样,选出一个有代表性的样本作为对照组,观察结束时将队列中出现的所研究疾病的全部病例作为病例组,与上述随机抽取的对照组进行比较
对照组可作为多种疾病的共用对照组
病例-病例研究
对于一种疾病的两个亚型进行对比研究
病例交叉研究
以每个病例发病之前的一个或多个时间段作为对照时间段,疾病发生时的暴露情况和同一个个体对照时间段的暴露情况进行比较
研究暴露的瞬时效应
暴露必须是变化的
自身对照
用途
用于疾病病因或危险因素的研究
用于健康相关事件影响因素的研究
用于疾病预后因素的研究
用于临床疗效影响因素的研究
第二节 研究设计与实施
一、确定研究目的
核心和指导思想
二、明确研究类型
广泛地探索疾病的危险因素-非匹配或频数匹配
检验病因假设,尤其是对于小样本的研究或因为病例的年龄、性别等构成特殊,随机抽取的对照组很难与病例组均衡可比时-个体匹配的病例对照研究
三、确定研究对象
病例的选择
病例的定义:诊断明确,统一,尽量使用金标准
病例的类型:新发(代表性好,回忆偏倚小、病例资料容易获得、一定范围或一定时间内较难得到预期的病例数)、现患(回忆偏倚)、死亡(准确性较差)
病例的来源:医院(代表性差)、社区
对照的选择
原则:以与病例相同的诊断标准确为不患所研究疾病的人。对照应该能够代表产生病例的源人群,即对照的暴露分布应与病例源人群的暴露分布一致
来源:从病例的源人群中抽取对照或者获取对照的人群的暴露分布与病例原人群的暴露分布一致
同一个或多个医疗机构中诊断的其他疾病的病人(这种来源的对照的暴露分布常常不同于病例的来源人群)
社区人群或团体人群中非该病病例或健康人
病例的邻居或同一住宅区内的健康人或非该病病例(控制社会经济地位的混杂因素)
病例的配偶、同胞、亲戚、同学或同事等(排除某些环境或遗传因素的影响)
方法
非匹配法
匹配法
匹配或称配比,是要求对照在某些特征或因素上与病例保持一致,保证对照与病例具有可比性,以便对两组进行比较时排除匹配因素的干扰
目的主要是提高研究效率,其次是控制混杂因素的干扰
匹配变量必须是已知的混杂因素,或有充分的理由怀疑为混杂因素
匹配过度:把不起混杂作用的因素作为匹配变量进行匹配,试图使对照组与病例组在多方面都一致,结果导致所研究的因素也一致,结果反而降低了研究的效率
匹配分为
频数匹配
对照组具有某种或某些因素或特征者所占的比例与病例组一致或相近
个体匹配
以对照与病例个体为单位进行匹配
配对:一个病例匹配一个对照
罕见病:1:r匹配,r一般不超过4
四、确定样本量
影响样本量的因素
研究因素在对照组或人群中的暴露频率(P0)
研究因素与疾病关联强度的估计值,即比值比(OR)
显著性水平
即第Ⅰ类错误(假阳性)概率(α),一般取α=0.05
效能
或称把握度(1-β)
β为第Ⅱ类错误假(阴性)概率,一般取β=0.01
五、确定研究因素
根据研究的目的或具体的目标,确定研究因素(暴露),尽可能采取国际或国内统一标准来确定暴露与否或暴露水平
可以从暴露数量和暴露持续时间评价暴露水平
测量指标尽量选用定量或半定量指标,也可按明确的标准进行定性测量
研究因素并不是越多越好,应以满足研究目的需要为原则-与研究目的有关的变量不可缺少,而且应当尽量细致和深入,与研究目的无关的内容不应列入
六、资料收集方法:询问调查对象填写问卷;查阅档案;现场观察和实际测量某些指标
第三节 资料的整理与分析
一、资料的整理:对原始资料进行全面检查与核实,确保资料尽可能完整和准确;对原始资料进行分组、归纳或编码后输入计算机,建立数据库
二、资料的分析
描述性统计:一般特征描述、均衡性检验
推断性分析
非匹配设计资料的分析
暴露与疾病的关联性分析:卡方检验
关联强度分析
点估计值
病例对照研究中没有暴露组和非暴露组的观察人数,不能计算发病率,不能直接计算RR,但可用比值比OR(odds ratio)-某事物发生的可能性与不发生的可能性之比
OR=ad/bc,表示暴露者的疾病是非暴露者的多少倍
>1,说明暴露与疾病成正关联
OR≈RR的条件:①所研究疾病的发病率(死亡率)很低,很高时OR与RR差很多;②病例对照研究中对照组的代表性好,即其暴露率能代表源人群
计算OR的95%可信区间:估计总体OR的范围,根据OR的可信区间是否包括1来推断暴露因素与疾病之间有无关联-如果OR的95%CI不包括1,说明如果进行多次病例研究,有95%的可能OR不等于1,该研究OR不等于1并非抽样误差导致
估计归因危险度百分比(AR%)和人群归因危险度百分比(PAR%)
AR%(attributable risk percentage)表示在暴露人群中由于暴露引起的发病占全部发病的AR%
PAR%(population attribution risk percentage)表示在一般人群中由于暴露引起的发病占全部发病的PAR%
1:1配对资料的分析
暴露与疾病关联分析:McNemar 卡方检验
OR=c/b
非匹配资料的分层分析
判断因素是否属于混杂因素:①与暴露有关;②与疾病有关;③不是中间环节
按某一混杂因素分成若干亚层→分别计算各层的ORi→齐性检验
差异无统计学意义→各层资料同质→计算总的OR(ORMH)
差异有统计学意义→不属于同质资料→不宜再计算OR,进一步分析分层因素和暴露因素之间的交互作用
剂量反应关系的分析
将不同暴露水平分成多个有序的暴露等级,不同暴露等级与无暴露或最低暴露水平的暴露作比较,分析暴露与疾病之间的剂量反应关系
将资料归纳成R*C列联表形式→进行R*C列联表资料的卡方检验→计算各暴露水平的OR值→卡方趋势检验
第四节 偏倚及其控制
选择偏倚
产生原因:选择的研究对象不能代表源人群
常见偏倚
入院率偏倚(伯克森偏倚):代表性存疑。尽可能在社区人群中选择病例和对照;最好在多个不同级别、不同种类的医院选择
现患病例-新发病例偏倚(奈曼偏倚):现患病例会导致得到的暴露信息只与存活有关,或是已被改变。选择新发病例作为研究对象,时间顺序错误
检出症候偏倚(暴露偏倚):某因素的存在可提高所研究疾病早期病例的检出率,在医院收集病例时最好包括不同来源的早、中、晚期病人
信息偏倚
产生原因:收集整理信息中测量暴露与结局的方法有缺陷
回忆偏倚:研究对象对暴露史或既往史回忆的准确性和完整性存在系统误差引起-选择新发病例,充分利用客观记录资料
调查偏倚:培训调查员,统一对病例和对照的提问方式和调查技术;仪器、试剂要精良、统一,经常检查、校准
混杂偏倚
由于某个因素既与疾病有关系,又与所研究的暴露因素有关系的外来因素的影响,掩盖或夸大了所研究的暴露因素与疾病的联系所造成的偏倚
混杂因素存在不一定导致混杂偏倚,在两个组中分布不均衡时才会导致
避免:对研究对象采取限制、配比等方法;分层分析或多因素分析
第五节 与队列研究优点和局限性的比较