导图社区 【人文医学】05预防医学与统计学
- 134
- 1
- 2
- 举报
【人文医学】05预防医学与统计学
【人文医学】05预防医学与统计学的思维导图,,内容有 休克的概述、病因与分类、发生机制、功能代谢变化等知识。
提示: 本内容由社区用户上传并分享。平台不对内容的真实性、合法性、知识产权归属及是否侵害第三方权利进行事前审核或保证。本内容可能包含受版权保护的图片、字体或其他第三方素材,使用前请自行确认授权范围。
- 人文医学
- 相似推荐
- 大纲
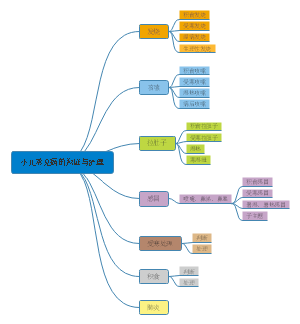
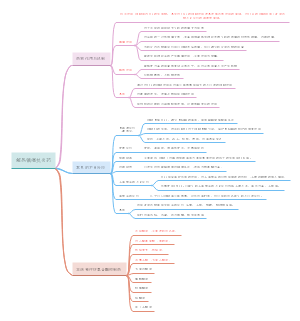
预防医学
绪论
定义
预防医学
预防医学:医学的一门应用学科 ①对象个体及确定的群体(健康、无症状患者) ②注重宏观微观相结合(影响健康因素与人群健康关系) ③预防作用(人群健康权益)
•研究内容:人体健康与环境关系 •研究对象:人群(健康、无症状的) •工作模式:人群-健康群-环境
第一次卫生革命的标志: 从个体预防→转向人群预防
流行病学
研究疾病与健康分布(一定范围内人群) ——最基本的方法:调查分析 •对象:人群 •事件:疾病健康状况 •内容:揭示现象,找出原因,预防措施 •目的:防治疾病,促进健康
研究内容
人群疾病和健康状况分布及影响因素
基本原理
疾病分布论;病因论;预防控制论;HDC
基本原则
群体原则→最显著;现场原则→环境; 对比原则→核心;代表性原则→代表性(人群)
"一群人在现场比着当代表"
疾病分布影响因素
地区、时间、人群
"天时,地利,人和"
三级预防
一级预防:病因预防
最根本性的预防,避免致病因素 (遗传咨询、教育、疫苗接种)→有明确病因 ★病因预防:预防职业病、地方病、传染病
二级预防:“三早”
体检“筛检”:早发现、早诊断、早治疗 (普查、筛查、高危人群专科门诊)→癌症 ★临床前期预防/三早预防:预防肿瘤
临床预防服务 •吃降压药,对高血压→三级预防 •吃降压药,对冠心病/脑血管病→一级预防
♦规律吃降压药,积极控制高血压→三级预防 ♦规律吃降压药,对于冠心病/脑血管病→一级预防
三级预防:治疗并发症
防止并发症,防止伤残,促进康复 (病因/危险因素不明,难以察觉)→慢性病 ★临床期预防/并残康:预防心脑血管疾病
临床预防
三间分布
地区分布(地方性)
•自然疫源性→野生动物; •统计地方性→生活习惯,卫生条件 •自然地方性→(仅)在某地区自然环境
•自然地方性传染病→传播媒介 •生物地球化学性疾病(地方病)→微量元素 •碘缺乏→地方性甲状腺肿,地方性克汀病 •区域性高氟→地方性氟病(氟骨症,氟斑牙)
时间分布
短期波动,季节性,周期性,长期变异 (流感:10-15年/世界性)
人群分布
年龄,职业,性别,社会阶层
偏倚控制 (系统误差)
选择偏倚→现况研究,病例对照研究,队列研究
(易感性偏倚→健康工人效应)
信息(观察)偏倚
•诊断怀疑→队列研究、临床试验 •暴露怀疑→病例对照研究 •发表偏倚→阳性结果更易发表 •回忆、报告(夸大或缩小)、测量(工具)偏倚 •错误分类偏倚→诊断方法不统一
3种分类:选错、信错、选错+信错→※无回忆偏倚 Meta分析(荟萃分析)→不会出现失访偏倚
混杂偏倚→受其他因素干扰
(在试验设计阶段,通过限制和匹配来控制)
基本概念
•同质:研究个体被研究指标的主要影响因素(基本)相同 •变异:同质的个体间各种指标存在差异
•总体:同质观察单位某项变量值的集合 •样本:从总体中随机抽取有代表性的部分观察单位变量值的集合
•参数:总体的统计指标(μ、σ) •统计量:样本的统计指标(X、S)
•系统误差:(仪器) •随机误差
随机测量误差
由于非人为因素,对同一观察单位 变量多次测定结果不完全一样
随机抽样误差
由于随机抽样所引起的样本与总体、 样本与样本之间的差异→(☞增加样本含量)
•小概率原理
将P≤0.05或P≤0.01的事件,可以认为 在一次抽样中几乎不可能发生
健康预防
二次污染物
排入环境中的一次污染物 在物理、化学因素或生物的作用下发生变化 或与环境中的其他物质发生反应 形成物理化学性状与一次污染物不同的新污染物
•SO2+在空气中氧化成硫酸盐气溶胶→酸雨 •氮氧化合物+日光照射→光化学烟雾
卫生服务
♦卫生服务需要:客观需要 依据人们的实际健康状况与“理想健康状态”之间存在差距而提出的对预防、医疗、保健、康复等卫生服务的客观需要 ♦卫生服务需求:愿意且有能力消费 从经济和价值观念出发,在一定时期内和一定价格水平上,人们愿意而且有能力消费的卫生服务量 ♦卫生服务利用:实际利用 需求者实际利用卫生服务的数量(即有效需求量)
•卫生服务需要:客观需要 →公平性 •卫生服务需求:愿意且有能力消费 •卫生服务利用:实际利用(即有效需求量)
行为变化阶段
♦无打算阶段:在未来6个月中没有改变自己行为的考虑,或有意坚持不改 ♦打算阶段:打算在未来(6个月内)采取行动,改变疾病危险行为 ♦准备阶段:将于未来1个月内改变行为 ♦行动阶段:在过去的6个月中目标行为已经有所改变 ♦行为维持阶段:已经维持新的行为状态长达6个月以上
•无打算阶段:未来6个月中+不改变
•打算阶段:未来6个月内+将要改变
促使思考,认识到危险行为的危害、 权衡改变行为的利弊, 产生改变行为的意向和动机
•准备阶段:未来1个月内+将要改变
•行动阶段:过去6个月中+已经改变
针对危险行为对于自身、他人和环境的影响 作出评判,尽快开始改变危害健康的行为, 促使参与者作为改变行为的承诺
•行为维持阶段:已经改变+6个月以上
改变环境消除或减少诱惑, 通过帮助建立自我强化和 学会信任来支持行为改变
试验设计三原则
♦对照原则:消除非处理因素对实验结果的影响使处理因素的效应得以体现 ♦随机化原则:每个受试对象有相同的概率被分配到不同避免研究者主观因素对实验效应的影响 ♦重复原则:相同实验条件下重复进行多次观察消除非处理因素的影响
•对照原则:消除非处理因素对实验结果的影响 •随机化原则:避免研究者主观因素对实验效应的影响 •重复原则:消除非处理因素的影响
健康
筛查目的
①实现二级预防(三早,发现可疑患者) ②一级预防(发现高危人群,预防) ③揭示冰山现象
诊断目的
对病人病情及时、正确的判断
健康促进
•健康教育+环境支持(重点在第一级预防) •三个基本策略:倡导、促成(核心)、协调
健康行为
"五A模式":评估,劝告,达成共识,协助,安排随访
营养素(不包括有机盐)
•蛋白质(10-12%):4→动物性、植物性(大豆) •脂类(20-30%):9→动物内脏 •碳水化合物(55-65%)→谷类,水果 •人体必需微量元素:锌、硒、碘、铁 •维生素:B₂→口腔生殖系综合症;叶酸→神经管畸形; A→过量中毒;B₁→脚气病;C→坏血病
膳食纤维→不能供给能量 纤维素,果胶,半纤维素 BMI:24-27.9超重;≥28肥胖
哺乳期膳食
•软食:轻微发热,肠道疾病恢复期 •半流质膳食:发热,消化道疾病,虚弱 •流质膳食:高热,消化道出血,急性传染病,术后患者
★多样化:4~5餐/日;供充足优质蛋白; 多吃含钙、铁;新鲜蔬果 •肠内营养→胃肠功能允许 •肠外营养→消化道胃肠道障碍(中心、周围静脉营养)
食物中毒
食物中毒特点
•24~48h内,发病急,呈暴发性 •与特定食物有关:一旦停止使用,发病停止 •临床表现基本相似:胃肠炎症为主或伴有神经 •无传染性:无传染病时曲线余波
职业病的特点
•病因明确 •明确的剂量(接触水平)-反应关系 •接触同样有害因素人群中,常有一定比例的发病 •通常早发现、早诊断、及时治疗预后好
细菌性→最常见 季节性(夏秋)
•沙门菌:夏秋季,动物性食品(毒素不属于神经毒)→4-48h
黄绿色水样便,体温明显升高、高达38~40℃→最常见
•副溶血性弧菌:海产品(鱼)→14-20h
其布阵发性绞痛,水样便(浓血便),里急后重不明显, (皮肤潮红,头晕,心悸,哮喘)→耐盐最强
•葡萄球菌肠毒素:奶及奶制品,蛋类(慎用抗生素)→2-4h
呕吐喷射状(含胆汁,血液),血样或粘液便,体温正常或稍低
•变形杆菌:动物性食品(熟肉)→5-18h
上腹刀绞样疼,急性腹泻,水样便伴有粘液
•肉毒梭菌:自己发酵豆谷类(最耐高温,脑N、自主N末梢)
不表现为胃肠道症状,头晕,头痛,视力模糊,吞咽困难
其他
•河豚中毒→神经中枢(因呼吸衰竭死) •亚硝盐中毒→腌制(鱼类)☞亚甲蓝(美蓝)和Vc解救
因呼衰而死: 河豚中毒,肉毒中毒,亚硝盐中毒,木薯中毒
流行病学
流行强度
散发 某病在某地区人群中呈历年的一般发病率水平,病例在人群中散在发生或零星出现,病例之间无明显联系。 用于描述较大范围(如区、县以上)人群某病流行强度,不用于较少居民区域或单位,通常与前三年发病率水平比较 流行 某地区、某病在某时间的发病率显著超过历年该病的散发发病率。短期内越过省界波及全国甚至超出国界洲界形成大流行 暴发 在一个局部地区或集体单位的人群中,短时间内突然出现许多临床症状相似的病人
①散发:散在发生,今年=往年(用于较大范围) ②流行:3-10倍,今年>往年(明显超过当地水平) ③大流行:>10倍,短时间跨省、跨国(流行性感冒) ④暴发:短时间、小范围、突发(食物中毒)
测量指标
♦发病率=一定时期内某人群中发生某病的新病例数/同期暴露人口数 ♦罹患率=观察期间某病新病例数/同期暴露人口数 ♦患病率=特定时期内某人群中某病新旧病例数/同期暴露人口数 ♦感染率=受检者中阳性人数/受检人数 ♦死亡率=某人群某年总死亡人数/该人群同年平均人口数 ♦病死率=一定期间内因某病死亡人数/同期患某病的人数 ♦n年生存率=随访满n年尚存活的病例数/开始随访的病例数 ♦发病率和罹患率异同: •分子相同均为新发病例数 •发病率一般以年为时间单位 •罹患率以月、周、日或一个流行期为时间单位 •罹患率一般多衡量小范围、短时间的发病频率 •罹患率多描述食物中毒、职业中毒及传染病暴发流行z
•发病率→一年中新病例(描述疾病分布,探讨病因,慢性病) •患病率(现患率)→新旧病例(病程较长,糖尿病) •罹患率→短时间小范围新发病率(小范围传染病、食物中毒)
•续发率→比较传染病传染力强弱(单位时间) •病死率→因病而死亡占总人数比例(急性传染病) •死亡率→一年内死亡的人数所占总人数比例 •累计发病率→适用于固定队列
一年新发高血压(新发→发病率) 目前现患糖尿病(现患→患病率) 突然罹患传染病(突发→罹患率)
筛检指标
♦评价试验真实性基本指标:灵敏度和特异度 ♦灵敏度(真阳性率) •评价诊断试验发现病人的能力 •实际有病且被该诊断实验正确地判断为有病的概率 ♦特异度(真阴性率) •评价诊断试验排除没病的人的能力 •实际无病,按该诊断试验被正确判为无病的概率 ♦漏诊率(假阴性率) •实际有病但依据该诊断实验确定为非病人的概率 ♦误诊率(假阳性率) •实际无病但按该诊断试验被判定为有病的概率
试验
筛检试验:灵敏度高,易误诊→筛查(发现病人)
♦目的:区别无症状的早期病人或病人与健康人 ♦对象:健康或表面健康的人 ♦要求:快速、简便、灵敏度高 ♦费用:一般使用简便、价廉的方法 ♦结果:阳性者须作进一步的诊断或干预
诊断试验:特异性高,易漏诊→确诊(排除没病)
♦目的:区别病人与可疑有病但实际无病的人 ♦对象:病人或可疑病人 ♦要求:复杂、准确、特异性高 ♦费用:一般在医院内进行,花费较高 ♦结果:阳性者需要给予治疗
灵敏度(真阳性率)
→实际患病中的阳性率 实际有病被筛选出有病的病例
特异度(真阴性率)
→未患病中的阴性率 实际无病被筛选出无病的病例
漏诊率(假阴性率)
灵敏度没有查出的病例(有病没查出)
误诊率(假阳性率)
特异度没有查出的病例(没病却查错)
阴性预测值
受试者试验结果阴性,无该病的可能
★约登指数=灵敏度+特异度-1 ★符合率(粗一致率) =(灵敏度人数+特异度人数)/总人数→极其可靠 •并联试验→灵敏度↑,漏诊率↓,阴性预测值↑ •串联试验→特异度↑,误诊率↓,阳性预测值↑ ★ROC曲线: 灵敏度为纵坐标,(1-特异度)误诊率为横坐标
分类
观察法
描述性研究
现况研究(横断面/患病率研究)
→应用最广泛,不明原因得病 (普查、筛查、抽样调查:患病率)
☞产生假设
生态学研究
疾病监测
☞当对某种疾病或人群健康状况不明时
分析性研究
队列研究(由因至果)→RR:关联强度
☞可研究疾病的自然史
病例对照研究(由果至因)→OR:关联强度
☞检验病因假设
实验法
实验研究
临床试验
•以临床病人为对象,研究药物和治疗方法效果 →(医院)患病人群(消除选择、混杂偏倚)
现场试验
•以未患病人群为对象,施加干预
社区干预试验(最可靠)
先措施后效果, 控制研究因素 ☞验证假设
数理法
理论研究(客观定量)
现况研究看现在、病例对照看以前、 队列研究看以后、临床试验看给药
现况研究 (横断面/患病率)
在某一人群中应用普查或抽样调查等方法收集特定时间内某种疾病或健康状况及有关变量的资料,以描述当时疾病或健康状况的分布及与疾病有关的因素
分类
①普查、筛查 ②抽样调查(样本代表性)→患病率高,变异程度不大
随机抽样方法
♦单纯随机抽样 将调查总体全部基本单位编号, 再用抽签或随机数学等方法随机抽取部分基本单位组成样本 ♦系统抽样(机械抽样) 按照某种顺序给总体中的个体编号, 然后随机地抽取一个编号作为第一调查个体, 其他的调查个体则按照某种确定的规则抽取。 最常用的为等距抽样 ♦分层抽样 先将总体全部个体按某种特征分成若干层, 再从每一层内随机抽取一定数量的个体合起来组成样本。 有等比抽样与最优抽样 ♦整群抽样 先将总体分成若干群体,形成一个抽样框; 从中随机抽取几个群体组成样本; 对抽中群体的全部个体进行调查 ♦多阶段抽样或复杂抽样 将整个抽样过程分成若干阶段进行, 各节段采用上述不同抽样方法
①简单随机抽样:先编号再按随机抽→最基本,最常用 ②系统抽样(机械/等距离):编号(每隔几个)按顺序抽 ③分层抽样(最优/等比例):分类(高中低)→误差最小 ④整群抽样(群组):先分群(户/社区)再抽 ⑤多级抽样(2项以上)
按三间分布分组, 展示分布特点, 分析并形成病因假设
队列研究 (由因至果)
将一个范围明确的人群按暴露因素的有无或暴露程度分为不同的亚组,追踪观察一定期限,比较不同亚组之间某病发病率或死亡率有无差异,从而判断暴露因素与结局有无关联及关联大小
暴露组:暴露于研究因素并出现结局
•特殊暴露人群:生活或工作 •一般人群→终止时间以潜伏期为依据 •有组织的团体→(均衡性,代表性)
对照组:人群中非暴露者
•内对照→人群内部包含暴露、非暴露两种人群 •外对照→人群内没有非暴露者 •总人口对照→该地区全人群与暴露组比较 •多重对照:加强说服力(±1无关,>1危险,<1安全)
计算
RR(相对危险度)=暴露÷非暴露发病率(RR↑,关联强度↑)
AR(归因危险度)=暴露-非暴露发病率
按是否暴露于所研究因素(暴露组/非暴露组) →暴露因素与结局有无关联 ①可靠、由因至果、可计算发病率、估计关联强度 ②不适于发病率低的、易发生失访偏倚、耗大复杂
病例对照研究 (由果至因)
从研究人群中选择一定数量的某种病人作为病例组,在同一人群中选择一定数量的非某种病病人作为对照,调查病例组和对照组人群既往某些暴露因素出现的频率并进行比较,以分析这些因素与疾病的联系
病例组:新发病例(社区新发病例)
对照组:产生病例总人群中未患该病的一个随机个体
成组(四格表):OR=ad/bc(比值比→暴露与疾病关联强度)
1:1匹配(M≤4):OR=c/d(OR=1无关,OR>1危险因素,OR<1保护)
按是否患病(疾病常见、暴露罕见),(病例组/对照组) →暴露因素与疾病关联强度 ♦观察性研究,由果至因,检验病因假设,一种疾病与多种因素 ①适用罕见病、对象较少、一种疾病与多个因素关系、快 ②不适于暴露率很低的,难以判断先后顺序, 易发生选择和回忆偏倚,不能计算率(发病率),直接RR
实验性研究
临床试验
•以临床病人为对象,研究药物和治疗方法效果 →(医院)患病人群(消除选择、混杂偏倚)
现场试验
•以未患病人群为对象,施加干预
率
有效率,治愈率,生存率
•历史对照→与过去同类患者(几年前) •自身对照→同一批对象前后疗效(自身前后)
对同一总体研究对象随机分实验组、对照组 →给实验组予实验因素,判断实验因素效果 ♦施加干预因素→最重要;前瞻性观察;有平行对照;随机分组
统计学
统计资料
分类
计量资料:身高、体重、血压(单位)→定量资料
t、F检验(正态、方差等齐)
计数资料(分类资料):血型、职业→定性资料
X²检验
等级资料:学历、成绩(ABC)、药物疗效
秩和检验(正态、方差不齐)
分类
数值变量资料(计量)
分类变量资料(计数)
无序多分类
二分类
多分类
有序多分类(等级)
秩和检验(正态、方差不齐)
定量资料的 统计描述
集中与离散趋势
资料分布
正态分布:均数/几何均数、标准差
偏态分布:中位数、四分位数间距
集中趋势
♦算数均数 •说明一组观察值的平均水平或集中趋势 •是描述定量数据最常用的方法 •适用于对称分布或偏度不大的资料 ♦几何均数 •适用于观察值呈明显倍数关系数据 ♦中位数 •将观察值从小到大按顺序排列,居中心位置的数值 •适合于频数分布呈明显偏态或频数分布两端无确定值 •分布不清:出现个别极大/极小值,分布一端或两端无确定数值 ♦百分位数 •百分位数Px指,x%的数据项小于或等于这个值 •其余(100-x)%的数据项大于或等于这个值 •其中P50即表示中位数 •适用于任何频数分布资料,尤其明显呈偏态分布资料
•算数均数(μ/X)→对称分布
•几何均数(G)→呈倍数、对数关系(血清滴度)
正态分布
•中位数(M)→分布不清:出现个别极大/极小值
•百分位数→
偏态分布
离散趋势
♦极差(R全距) •观察值中最大值Xmax和最小值Xmin之差 •变异指标中最简单者,越大说明变异程度大 ♦四分位数间距(Q) •将所有观察值排序后,分成四个数目相等的段落 •中间50%观察值的数据范围(Q=Pz75-P25) •主要用于描述明显偏态分布资料的变异特征 •描述个体差异(两端含不确定值) ♦方差和标准差 •使用最多的变异指标 •标准差是描述正态分布变异程度的最佳指标 ♦变异系数(CV) •标准差除以均数为变异系数 •均数相差较大或单位不同的几组观察值变异程度比较 ☞可比较(不同计量指标)两均数相差较大时指标的变异程度
•极差(全距R)→最简单指标
•四分位数间距(Q)→描述个体差异(两端含不确定值)
偏态分布
•方差/标准差(σ/S)→最佳指标,绝对离散程度
正态分布
•变异系数(CV)=S/X·100%→相对离散程度
统计图
间断型 ♦直条图→适用于相互独立、无量关系的资料,以表示其指标大小 ♦箱式图→可比较各个相互独立的计量资料 ♦圆形图(饼图)、百分直条图→适用于构成比资料,反映各组成部分的大小 连续型 ♦线图→适用连续性资料,反映数量随时间的变迁;某一种现象属于另一种现象而变迁 ♦半对数线图→反映事物发展速度(相对比) ♦直方图→反映连续性变量的频数分布 ♦散点图→适用于成对教据,反映散点分布趋势 地域性资料 ♦统计地图→表示某种事物的地理分布情况 ♦直方图(定量资料) 直条矩形面积代表各组频数,各矩形面积总和代表频数总和, 用于表示连续变量频数分布情况 ♦直条图(定性资料) 等宽直条的长短来表示相对独立的统计指标数值大小和它们之间的对比关系 ♦线条图(定量资料) 通过线段的上升或下降来表示指标(变量)的连续变化过程, 适用于描述一个变量随另一个变量变化的趋势和波动情况 反映数量随时间的变迁,一种现象随另一种变化 ♦构成图(定性资料) 常用构成图有圆图和百分条图,圆图用各扇形面积 来表示全体中各部分所占比例; 百分条图用矩,条长度表示100%,其中分隔各段表示构成百分比
直方图(定量资料):反映连续性变量的频数分布
直条图(定性资料):适用相互独立、无数量关系的资料
线条图(定量资料):反映数量随时间的变迁
构成图(定性资料):适用构成比资料,反映各组成部分的大小
抽样误差与标准误
抽样误差
•由抽样造成的样本统计量和总体参数之间的差异
标准误
•反应样本均数之间变异的标准差称为标准误 •抽样误差的大小由标准误表示 •通过增加样本含量来减小标准误
假设检验的步骤
①建立假设
目的:检验总体参数是否不同
•H0:μ=μ0
即样本均数与总体均数相同→无效假设
•H1:μ≠μ0
即样本均数与总体均数不同(α=0.05)
②计算t值
③确定P值,做出结论
•t计≥t查, 则P≤0.05(α)
→拒绝H0,接受H1,差异有统计学意义, 有显著性,可以认为不同/不全相等/有差别
•t计<t查, 则P>0.05(α)
→不拒绝H0,差异无统计学意义, 无显著性,尚不能认为不同
统计学描述
频率表的编制步骤
•计算全距(极差:R) •确定组距(8-15组:i) •划分组段 •统计频数 •频率与累计频率
•揭示资料的分布类型 (对称分布,偏态分布 ) •观察资料的集中趋势和离散趋势 •便于发现某特大,特小值 •便于计算统计指数和进一步做统计处理
定性资料
相对数:两个有关联的指标之比
率(P):频率指标→说明某现象发生的频率或强度
P=某时期实际发生的个数 /同时期可能发生的总数×K(比例基数)
构成比→说明各构成部分在总体中所占比重分布
构成比=某事物内部某一组成部分的个数 /同一事物各组成部分的总数×100%
相对比→说明两指标间的比例关系 •对比指标:指同类事物的两个指标之比→(男女性别比) •关系指标:指两个有关的,但非同类事物的数量的比
相对比=甲指标/乙指标×100% (两指标可以是绝对数,相对数或平均数)
平均率
平均率=分子合计/分母合计
率的标准化:消除其内部构成不同对合计率的影响
疾病统计指标
正态分布
特点
•对称性:频数分布以均数(μ)为中心,左右基本对称
•集中性:靠近均数两侧的频数较多,远离逐渐减少
•绝对正态分布:μ=0、σ=1 →σ越大,μ代表性越差(反相关)
位置参数(μ)→集中趋势位置(左右) 形状参数(σ)→离散程度(上下)
面积分布规律
参考值范围 (均数±标准差)
•X±1S→68.27% •X±1.96S→95% •X±2.58S→99%
可信区间 (均数±标准误)
•X±1Sx→68.27% •X±1.96Sx→95% •X±2.58Sx→99%
→总体均数 标准误(Sx)=标准差(S)/√n
医学参考值范围
定义
医学上绝大多数正常人的某项指标范围 (95%,排除影响指标的同质人群)
正态分布法→正态 百分位数法→偏态
•90%→X±1.64S→P5-P95 •95%→X±1.96S→P2.5-P97.55 •99%→X±2.58S→P0.5-P99.5
总体均数(μ)的 区间估计与假设
标准误
样本均数 (χ)的标准差(σχ反映均数抽样误差大小的指标)
Sχ=S/√n ← σχ=σ/√n (标准误与标准差成正比)
通过增加样本含量来减小标准误
•表示抽样误差大小,从而说明样本均数的可靠性 •进行总体均数(μ)的区间估计 •进行均数的t检验
差异:样本均数与样本均数,样本均数与总体均数 Sχ越大,用样本均数估计总体均数,可靠性越小
t分布
•以0为中心,左右对称的单峰分布 •与线变化与自由度(V=n-1)相关: V越大,t值越分散,曲线越低,平越接近Z •随着自由度增大,t分布逐渐接近正态曲线(Z分布)
t界值表(α=0.05)
•V相同,P越小,t越大 •P相同,V越小,t越大 •t计≥t查,则P≤0.05(α);t计<t查,则P>0.05(α)
总体均数(μ)的估计
点值估计
用样本统计量直接作为总体参数的估计值 (直接用χ作为μ估计值,样本率P作为总体率π的估计值)
区间估计
(可信区间 CI)按一定概率(1-α)估计,包含总体参数(μ)可能的范围
总体均数(μ)被包含在该区间的概率为1-α (95%)
可信区间CI
n≤50→t分布:χ±t×Sχ n>50→Z分布:χ±Z×Sχ
准确度:即概率大小可信区间(1-α)表示 精确度:反映在区间的宽度上 在可信度固定下提高精密度的唯一方法,扩大样本量
99%:CI估计范围宽,准确度高 95%:CI估计范围窄,精确度高
t检验
错误
t检验
样本来自正态分布,两样本总体方差(σ)相等。计量资料
单样本t检验(样本均数与总体均数)
•H0:μ=μ0 •H1:μ≠μ0 (V=n-1)
t=‖χ-μ0‖/Sχ
配对t检验 (同质对象总体均数前后对比 )
•H0:μd=0 •H1:μd≠0 (V=n-1)
t=‖d‖/Sd
独立样本t检验 (两样本均数比较 )
•H0:μ1=μ2 •H1:μ1≠μ2 (V=n1+n2-2)
t=‖χ1-χ2‖/Sχ1-χ2
t'检验
两小样本均数比较,方差不齐,正态分布
方差等齐性检验 (总体方差 )
统计资料
♦计量资料:(常有单位和小数点) 身高、体重、血压(单位)→t、F检验(正态、方差等齐) ♦计数资料:(分类资料:按属性和类别分组) 血型、职业→X²检验 ♦等级资料:(有序多分类) 学历、成绩(ABC)、药物疗效→秩和检验(正态、方差不齐) ♦数值变量资料(计量) ♦分类变量资料(计数) •无序多分类:二分类、多分类 •有序多分类(等级)
计量资料:有单位 (身高、体重、血压)
♦计量资料:身高、体重、血压(常有单位和小数点) →t、F检验(正态、方差等齐)
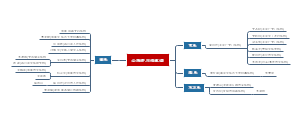
单样本
正态分布
是
单 样 本 t 检 验
否
配对符号秩和检验
两样本
配对
差值服从 正态分布
是
配 对 t 检 验
否
配对符号秩和检验
分组
正态分布
是
方差齐性
是
独 立 样 本 t 检 验
否
两独立样本秩和检验
否
两独立样本秩和检验
多样本
是
正态分布
是
方差齐性
是
方差分析
否
多个独立样本秩和检验
否
多个独立样本秩和检验
计数资料:无单位 (血型、职业)
♦计数资料:血型、职业(按属性和类别分组) →X²检验
两行两列
配对
是
配对X²检验
b+c≥40
是
MCmmar 检验
否
校正配对X²检验
否
四格表X²检验
n>40,T>5
是
Pearson X²检验
否
校正四格表X²检验
多行多列
有序多分类 (等级:药效)
♦等级资料:(有序多分类) 学历、成绩(ABC)、药物疗效→秩和检验(正态、方差不齐)
是
秩和检验
否
行列表X²检验