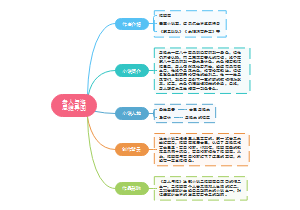
导图社区 八下物理核心考点
八下物理核心考点
此梳理突出概念理解与公式应用,建议结合《义务教育物理课程标准》强化科学探究能力,通过实验深化对压强、浮力等抽象概念的理解。
编辑于2025-02-15 09:56:50- 八下物理
- 核心考点
- 八下数学 华师版新
【八下数学华师版精华速览】 聚焦数据分析与几何证明两大核心,从分式运算到函数图像层层递进重点模块:①第19章数据分析三剑客平均数、方差、极差指导决策②平行四边形家族(矩形/菱形/正方形)的判定与性质解析③反比例函数与一次函数的图像特征及应用建模④分式方程解法与增根问题实战特色提炼:通过"中点四边形"等典型例题串联几何思维,结合标准差计算强化数据敏感性,助你掌握从公式推导到实际建模的完整链路。
- 七下数学(华师版新)核心考点
【数学七下核心突破】轴对称与方程不等式双线并进,轻松攻克几何代数难点! 内容亮点: 1. 几何三板斧:轴对称/平移/旋转的作图与性质全解析,搭配三角形全等判定技巧,破解折叠与组合变换题 2. 代数双引擎:从一元一次方程到不等式组,强化含参讨论与应用题建模,辅以三元方程组拓展思维 3. 考点闭环:等腰三角形性质 内角和定理打底,融合坐标系平移规律,助你拿下旋转作图与方案设计压轴题。
- 甘谷小简AI中高考对策
【甘谷小简AI中高考对策:用时间复利撬动提分杠杆】 核心理念:每日微习惯 单点突破,让弱科变强每月聚焦1科,每周攻克1个弱势板块,通过结构化经验本、错题资产化、五步精准学法实现系统性提升AI智能引领测画背默多元输出,寒暑假提前学 节假日5闭环,用可持续微习惯(清错题/背单词/刷基础)替代突击训练坚持"先完成再完美",即使慢也不停,时间终将让积累显现在成绩上。
八下物理核心考点
社区模板帮助中心,点此进入>>
- 八下数学 华师版新
【八下数学华师版精华速览】 聚焦数据分析与几何证明两大核心,从分式运算到函数图像层层递进重点模块:①第19章数据分析三剑客平均数、方差、极差指导决策②平行四边形家族(矩形/菱形/正方形)的判定与性质解析③反比例函数与一次函数的图像特征及应用建模④分式方程解法与增根问题实战特色提炼:通过"中点四边形"等典型例题串联几何思维,结合标准差计算强化数据敏感性,助你掌握从公式推导到实际建模的完整链路。
- 七下数学(华师版新)核心考点
【数学七下核心突破】轴对称与方程不等式双线并进,轻松攻克几何代数难点! 内容亮点: 1. 几何三板斧:轴对称/平移/旋转的作图与性质全解析,搭配三角形全等判定技巧,破解折叠与组合变换题 2. 代数双引擎:从一元一次方程到不等式组,强化含参讨论与应用题建模,辅以三元方程组拓展思维 3. 考点闭环:等腰三角形性质 内角和定理打底,融合坐标系平移规律,助你拿下旋转作图与方案设计压轴题。
- 甘谷小简AI中高考对策
【甘谷小简AI中高考对策:用时间复利撬动提分杠杆】 核心理念:每日微习惯 单点突破,让弱科变强每月聚焦1科,每周攻克1个弱势板块,通过结构化经验本、错题资产化、五步精准学法实现系统性提升AI智能引领测画背默多元输出,寒暑假提前学 节假日5闭环,用可持续微习惯(清错题/背单词/刷基础)替代突击训练坚持"先完成再完美",即使慢也不停,时间终将让积累显现在成绩上。
- 相似推荐
- 大纲