导图社区 保尔·柯察金的成长经历
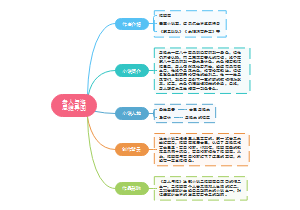
《钢铁是怎样炼成的》保尔·柯察金的成长经历,本图对时间点和发生的事件做了非常详细的罗列,可以了解下。
这是一篇关于《水浒传》的思维导图,主要内容有作者、故事发展、薛—承、精彩情节、语言特色等。
《艾青诗选》为人教版九上必读书目,本思维导图十分详细,并附有作者照片、写作背景等于其中,有助于理解诗歌。
浩瀚的大气-2.3 九上化学 化学变化中的质量守恒 思维导图详细无误 包含2.3 化学变化中的质量守恒内容 并附有教材图片辅助理解 有利于预习新知
社区模板帮助中心,点此进入>>
《老人与海》思维导图
《钢铁是怎样炼成的》章节概要图
《傅雷家书》思维导图
《西游记》思维导图
《水浒传》思维导图
《茶馆》思维导图
《朝花夕拾》篇目思维导图
《红星照耀中国》书籍介绍思维导图
初中物理质量与密度课程导图
桃花源记思维导图
保尔·柯察金
1903年
出生
贫困的铁路工人家庭
幼年时期
失去父亲
被学校开除
12岁
被母送到车站食堂当杂役
受尽凌辱
厌恶有钱人
1917年
“十月革命”爆发
革命遭到阻挠
保尔家乡遭到战火摧残
红军解放家乡后撤走
与老布尔什维克朱赫来共度
为解救朱赫来被关押
被错放
来到冬妮娅家
离开冬妮娅家
参军
头部被弹片击中
无法回到前线
投入艰苦劳动
参加工友聚会
带了冬妮娅而遭到嘲笑
意识到阶级分化
冬妮娅回绝和保尔站在同一战线上
感情破裂
开始修建铁路
工作艰苦
与优秀女共产党员丽达多有接触
产生感情后依旧下定决心断绝感情
患上伤寒
引发肺炎
送回家乡修养
在“已死”的谣言中顽强地活了下来
入党
继续忘我劳作
身体健康难保
长期住院治疗
后
与女民工达雅相爱
顽强学习
全身瘫痪、双目失明
开始写作
忍受痛苦写成的手稿丢失
振作起来
自己口述、请人代录
以顽强毅力著成《暴风雨所诞生的》
保尔·柯察金的成长经历
薛一承