导图社区 030--机电工程施工质量管理
030--机电工程施工质量管理
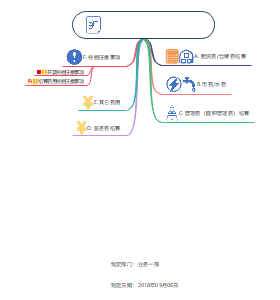
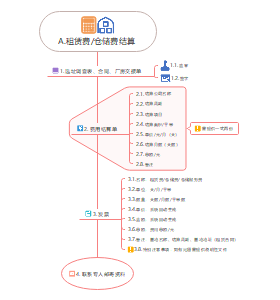
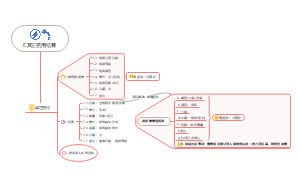
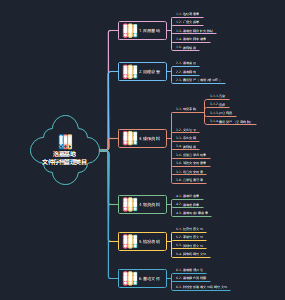
2023年二建机电复习030--机电工程施工质量管理,其机电工程项目质量管理特点: 1.施工中存在交叉施工。各专业、工种、施工单位需要相互协调配合。 2.施工中要与不同单位协调配合。如土建、装饰、设备制造厂等。 3.要进行系统的调试运行及各项功能参数的检测。
编辑于2023-08-11 10:44:31 陕西- 二建机电
- 相似推荐
- 大纲
导图社区 030--机电工程施工质量管理
2023年二建机电复习030--机电工程施工质量管理,其机电工程项目质量管理特点: 1.施工中存在交叉施工。各专业、工种、施工单位需要相互协调配合。 2.施工中要与不同单位协调配合。如土建、装饰、设备制造厂等。 3.要进行系统的调试运行及各项功能参数的检测。
编辑于2023-08-11 10:44:31 陕西